 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric Depth Based Feature Representation Learning for Object Detection and Segmentation in Bird's Eye View
Jul 11, 2023



Recent vision-only perception models for autonomous driving achieved promising results by encoding multi-view image features into Bird's-Eye-View (BEV) space. A critical step and the main bottleneck of these methods is transforming image features into the BEV coordinate frame. This paper focuses on leveraging geometry information, such as depth, to model such feature transformation. Existing works rely on non-parametric depth distribution modeling leading to significant memory consumption, or ignore the geometry information to address this problem. In contrast, we propose to use parametric depth distribution modeling for feature transformation. We first lift the 2D image features to the 3D space defined for the ego vehicle via a predicted parametric depth distribution for each pixel in each view. Then, we aggregate the 3D feature volume based on the 3D space occupancy derived from depth to the BEV frame. Finally, we use the transformed features for downstream tasks such as object detection and semantic segmentation. Existing semantic segmentation methods do also suffer from an hallucination problem as they do not take visibility information into account. This hallucination can be particularly problematic for subsequent modules such as control and planning. To mitigate the issue, our method provides depth uncertainty and reliable visibility-aware estimations. We further leverage our parametric depth modeling to present a novel visibility-aware evaluation metric that, when taken into account, can mitigate the hallucination problem. Extensive experiments on object detection and semantic segmentation on the nuScenes datasets demonstrate that our method outperforms existing methods on both tasks.
FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation
Jul 04, 2023This technical report summarizes the winning solution for the 3D Occupancy Prediction Challenge, which is held in conjunction with the CVPR 2023 Workshop on End-to-End Autonomous Driving and CVPR 23 Workshop on Vision-Centric Autonomous Driving Workshop. Our proposed solution FB-OCC builds upon FB-BEV, a cutting-edge camera-based bird's-eye view perception design using forward-backward projection. On top of FB-BEV, we further study novel designs and optimization tailored to the 3D occupancy prediction task, including joint depth-semantic pre-training, joint voxel-BEV representation, model scaling up, and effective post-processing strategies. These designs and optimization result in a state-of-the-art mIoU score of 54.19% on the nuScenes dataset, ranking the 1st place in the challenge track. Code and models will be released at: https://github.com/NVlabs/FB-BEV.
FasterViT: Fast Vision Transformers with Hierarchical Attention
Jun 09, 2023We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy \vs image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
Domain Adaptive Decision Trees: Implications for Accuracy and Fairness
Feb 27, 2023



In uses of pre-trained machine learning models, it is a known issue that the target population in which the model is being deployed may not have been reflected in the source population with which the model was trained. This can result in a biased model when deployed, leading to a reduction in model performance. One risk is that, as the population changes, certain demographic groups will be under-served or otherwise disadvantaged by the model, even as they become more represented in the target population. The field of domain adaptation proposes techniques for a situation where label data for the target population does not exist, but some information about the target distribution does exist. In this paper we contribute to the domain adaptation literature by introducing domain-adaptive decision trees (DADT). We focus on decision trees given their growing popularity due to their interpretability and performance relative to other more complex models. With DADT we aim to improve the accuracy of models trained in a source domain (or training data) that differs from the target domain (or test data). We propose an in-processing step that adjusts the information gain split criterion with outside information corresponding to the distribution of the target population. We demonstrate DADT on real data and find that it improves accuracy over a standard decision tree when testing in a shifted target population. We also study the change in fairness under demographic parity and equal opportunity. Results show an improvement in fairness with the use of DADT.
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
Feb 23, 2023



Humans can easily imagine the complete 3D geometry of occluded objects and scenes. This appealing ability is vital for recognition and understanding. To enable such capability in AI systems, we propose VoxFormer, a Transformer-based semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images. Our framework adopts a two-stage design where we start from a sparse set of visible and occupied voxel queries from depth estimation, followed by a densification stage that generates dense 3D voxels from the sparse ones. A key idea of this design is that the visual features on 2D images correspond only to the visible scene structures rather than the occluded or empty spaces. Therefore, starting with the featurization and prediction of the visible structures is more reliable. Once we obtain the set of sparse queries, we apply a masked autoencoder design to propagate the information to all the voxels by self-attention. Experiments on SemanticKITTI show that VoxFormer outperforms the state of the art with a relative improvement of 20.0% in geometry and 18.1% in semantics and reduces GPU memory during training by ~45% to less than 16GB. Our code is available on https://github.com/NVlabs/VoxFormer.
Counterfactual Situation Testing: Uncovering Discrimination under Fairness given the Difference
Feb 23, 2023We present counterfactual situation testing (CST), a causal data mining framework for detecting discrimination in classifiers. CST aims to answer in an actionable and meaningful way the intuitive question "what would have been the model outcome had the individual, or complainant, been of a different protected status?" It extends the legally-grounded situation testing of Thanh et al. (2011) by operationalizing the notion of fairness given the difference using counterfactual reasoning. For any complainant, we find and compare similar protected and non-protected instances in the dataset used by the classifier to construct a control and test group, where a difference between the decision outcomes of the two groups implies potential individual discrimination. Unlike situation testing, which builds both groups around the complainant, we build the test group on the complainant's counterfactual generated using causal knowledge. The counterfactual is intended to reflect how the protected attribute when changed affects the seemingly neutral attributes used by the classifier, which is taken for granted in many frameworks for discrimination. Under CST, we compare similar individuals within each group but dissimilar individuals across both groups due to the possible difference between the complainant and its counterfactual. Evaluating our framework on two classification scenarios, we show that it uncovers a greater number of cases than situation testing, even when the classifier satisfies the counterfactual fairness condition of Kusner et al. (2017).
Vision Transformers Are Good Mask Auto-Labelers
Jan 10, 2023We propose Mask Auto-Labeler (MAL), a high-quality Transformer-based mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates their mask pseudo-labels.We show that Vision Transformers are good mask auto-labelers. Our method significantly reduces the gap between auto-labeling and human annotation regarding mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of their fully-supervised counterparts, retaining up to 97.4\% performance of fully supervised models. The best model achieves 44.1\% mAP on COCO instance segmentation (test-dev 2017), outperforming state-of-the-art box-supervised methods by significant margins. Qualitative results indicate that masks produced by MAL are, in some cases, even better than human annotations.
Soft Masking for Cost-Constrained Channel Pruning
Nov 04, 2022Structured channel pruning has been shown to significantly accelerate inference time for convolution neural networks (CNNs) on modern hardware, with a relatively minor loss of network accuracy. Recent works permanently zero these channels during training, which we observe to significantly hamper final accuracy, particularly as the fraction of the network being pruned increases. We propose Soft Masking for cost-constrained Channel Pruning (SMCP) to allow pruned channels to adaptively return to the network while simultaneously pruning towards a target cost constraint. By adding a soft mask re-parameterization of the weights and channel pruning from the perspective of removing input channels, we allow gradient updates to previously pruned channels and the opportunity for the channels to later return to the network. We then formulate input channel pruning as a global resource allocation problem. Our method outperforms prior works on both the ImageNet classification and PASCAL VOC detection datasets.
Structural Pruning via Latency-Saliency Knapsack
Oct 18, 2022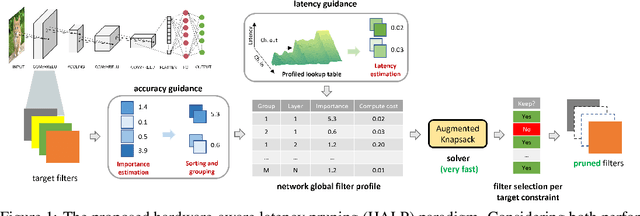
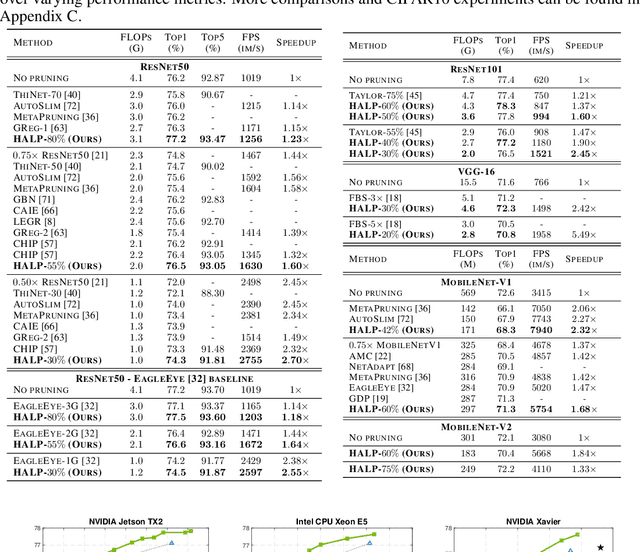
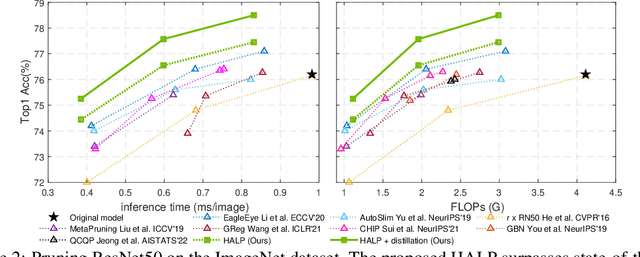
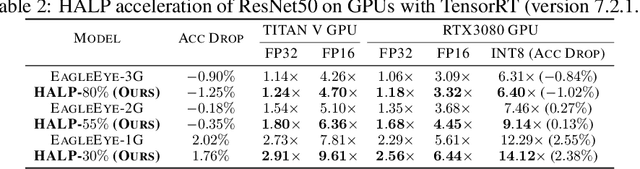
Structural pruning can simplify network architecture and improve inference speed. We propose Hardware-Aware Latency Pruning (HALP) that formulates structural pruning as a global resource allocation optimization problem, aiming at maximizing the accuracy while constraining latency under a predefined budget on targeting device. For filter importance ranking, HALP leverages latency lookup table to track latency reduction potential and global saliency score to gauge accuracy drop. Both metrics can be evaluated very efficiently during pruning, allowing us to reformulate global structural pruning under a reward maximization problem given target constraint. This makes the problem solvable via our augmented knapsack solver, enabling HALP to surpass prior work in pruning efficacy and accuracy-efficiency trade-off. We examine HALP on both classification and detection tasks, over varying networks, on ImageNet and VOC datasets, on different platforms. In particular, for ResNet-50/-101 pruning on ImageNet, HALP improves network throughput by $1.60\times$/$1.90\times$ with $+0.3\%$/$-0.2\%$ top-1 accuracy changes, respectively. For SSD pruning on VOC, HALP improves throughput by $1.94\times$ with only a $0.56$ mAP drop. HALP consistently outperforms prior art, sometimes by large margins. Project page at https://halp-neurips.github.io/.
Optimizing Data Collection for Machine Learning
Oct 03, 2022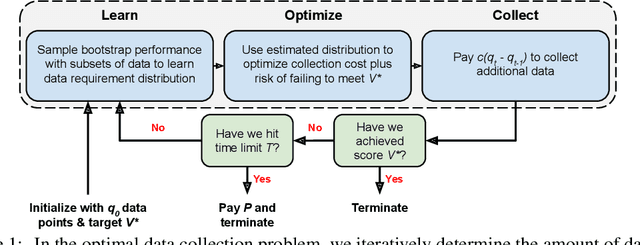
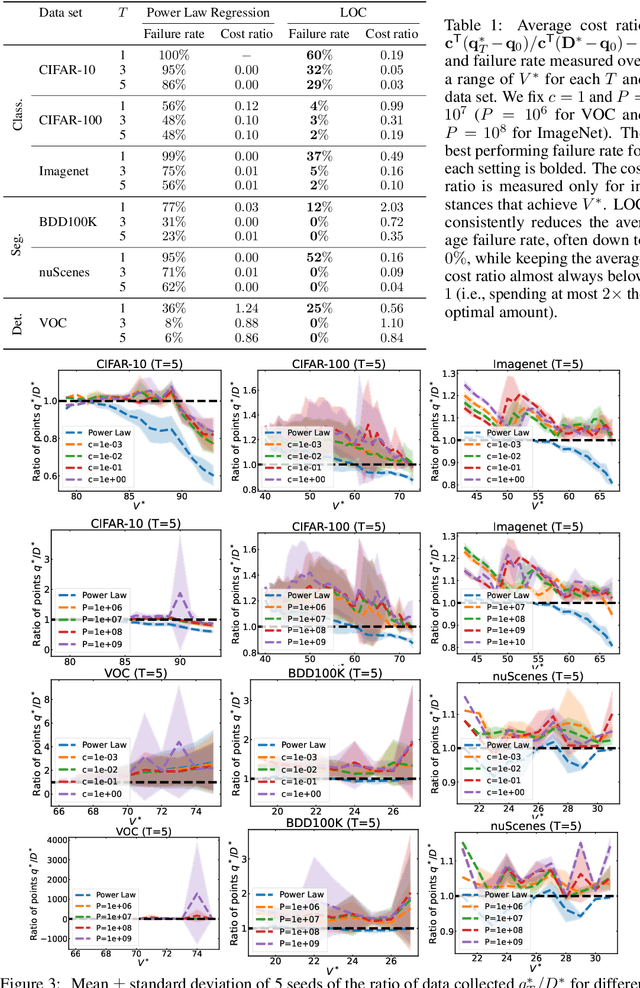
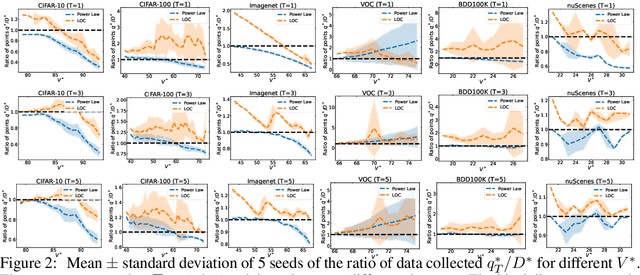
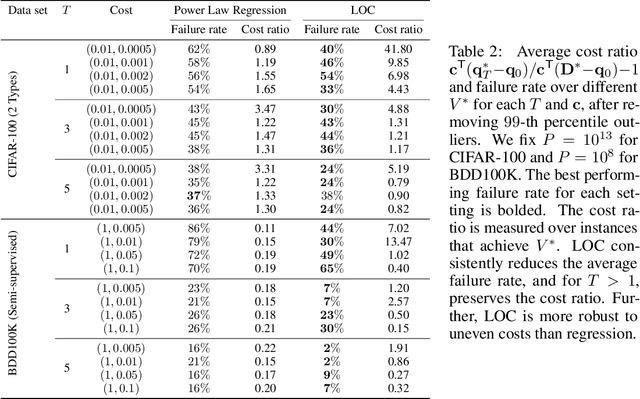
Modern deep learning systems require huge data sets to achieve impressive performance, but there is little guidance on how much or what kind of data to collect. Over-collecting data incurs unnecessary present costs, while under-collecting may incur future costs and delay workflows. We propose a new paradigm for modeling the data collection workflow as a formal optimal data collection problem that allows designers to specify performance targets, collection costs, a time horizon, and penalties for failing to meet the targets. Additionally, this formulation generalizes to tasks requiring multiple data sources, such as labeled and unlabeled data used in semi-supervised learning. To solve our problem, we develop Learn-Optimize-Collect (LOC), which minimizes expected future collection costs. Finally, we numerically compare our framework to the conventional baseline of estimating data requirements by extrapolating from neural scaling laws. We significantly reduce the risks of failing to meet desired performance targets on several classification, segmentation, and detection tasks, while maintaining low total collection costs.