 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Apr 23, 2024



This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
What is Point Supervision Worth in Video Instance Segmentation?
Apr 01, 2024



Video instance segmentation (VIS) is a challenging vision task that aims to detect, segment, and track objects in videos. Conventional VIS methods rely on densely-annotated object masks which are expensive. We reduce the human annotations to only one point for each object in a video frame during training, and obtain high-quality mask predictions close to fully supervised models. Our proposed training method consists of a class-agnostic proposal generation module to provide rich negative samples and a spatio-temporal point-based matcher to match the object queries with the provided point annotations. Comprehensive experiments on three VIS benchmarks demonstrate competitive performance of the proposed framework, nearly matching fully supervised methods.
Improving Distant 3D Object Detection Using 2D Box Supervision
Mar 14, 2024



Improving the detection of distant 3d objects is an important yet challenging task. For camera-based 3D perception, the annotation of 3d bounding relies heavily on LiDAR for accurate depth information. As such, the distance of annotation is often limited due to the sparsity of LiDAR points on distant objects, which hampers the capability of existing detectors for long-range scenarios. We address this challenge by considering only 2D box supervision for distant objects since they are easy to annotate. We propose LR3D, a framework that learns to recover the missing depth of distant objects. LR3D adopts an implicit projection head to learn the generation of mapping between 2D boxes and depth using the 3D supervision on close objects. This mapping allows the depth estimation of distant objects conditioned on their 2D boxes, making long-range 3D detection with 2D supervision feasible. Experiments show that without distant 3D annotations, LR3D allows camera-based methods to detect distant objects (over 200m) with comparable accuracy to full 3D supervision. Our framework is general, and could widely benefit 3D detection methods to a large extent.
Causal Perception
Jan 24, 2024Perception occurs when two individuals interpret the same information differently. Despite being a known phenomenon with implications for bias in decision-making, as individuals' experience determines interpretation, perception remains largely overlooked in automated decision-making (ADM) systems. In particular, it can have considerable effects on the fairness or fair usage of an ADM system, as fairness itself is context-specific and its interpretation dependent on who is judging. In this work, we formalize perception under causal reasoning to capture the act of interpretation by an individual. We also formalize individual experience as additional causal knowledge that comes with and is used by an individual. Further, we define and discuss loaded attributes, which are attributes prone to evoke perception. Sensitive attributes, such as gender and race, are clear examples of loaded attributes. We define two kinds of causal perception, unfaithful and inconsistent, based on the causal properties of faithfulness and consistency. We illustrate our framework through a series of decision-making examples and discuss relevant fairness applications. The goal of this work is to position perception as a parameter of interest, useful for extending the standard, single interpretation ADM problem formulation.
Fully Attentional Networks with Self-emerging Token Labeling
Jan 08, 2024



Recent studies indicate that Vision Transformers (ViTs) are robust against out-of-distribution scenarios. In particular, the Fully Attentional Network (FAN) - a family of ViT backbones, has achieved state-of-the-art robustness. In this paper, we revisit the FAN models and improve their pre-training with a self-emerging token labeling (STL) framework. Our method contains a two-stage training framework. Specifically, we first train a FAN token labeler (FAN-TL) to generate semantically meaningful patch token labels, followed by a FAN student model training stage that uses both the token labels and the original class label. With the proposed STL framework, our best model based on FAN-L-Hybrid (77.3M parameters) achieves 84.8% Top-1 accuracy and 42.1% mCE on ImageNet-1K and ImageNet-C, and sets a new state-of-the-art for ImageNet-A (46.1%) and ImageNet-R (56.6%) without using extra data, outperforming the original FAN counterpart by significant margins. The proposed framework also demonstrates significantly enhanced performance on downstream tasks such as semantic segmentation, with up to 1.7% improvement in robustness over the counterpart model. Code is available at https://github.com/NVlabs/STL.
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
Dec 05, 2023



End-to-end autonomous driving recently emerged as a promising research direction to target autonomy from a full-stack perspective. Along this line, many of the latest works follow an open-loop evaluation setting on nuScenes to study the planning behavior. In this paper, we delve deeper into the problem by conducting thorough analyses and demystifying more devils in the details. We initially observed that the nuScenes dataset, characterized by relatively simple driving scenarios, leads to an under-utilization of perception information in end-to-end models incorporating ego status, such as the ego vehicle's velocity. These models tend to rely predominantly on the ego vehicle's status for future path planning. Beyond the limitations of the dataset, we also note that current metrics do not comprehensively assess the planning quality, leading to potentially biased conclusions drawn from existing benchmarks. To address this issue, we introduce a new metric to evaluate whether the predicted trajectories adhere to the road. We further propose a simple baseline able to achieve competitive results without relying on perception annotations. Given the current limitations on the benchmark and metrics, we suggest the community reassess relevant prevailing research and be cautious whether the continued pursuit of state-of-the-art would yield convincing and universal conclusions. Code and models are available at \url{https://github.com/NVlabs/BEV-Planner}
BEVNeXt: Reviving Dense BEV Frameworks for 3D Object Detection
Dec 04, 2023



Recently, the rise of query-based Transformer decoders is reshaping camera-based 3D object detection. These query-based decoders are surpassing the traditional dense BEV (Bird's Eye View)-based methods. However, we argue that dense BEV frameworks remain important due to their outstanding abilities in depth estimation and object localization, depicting 3D scenes accurately and comprehensively. This paper aims to address the drawbacks of the existing dense BEV-based 3D object detectors by introducing our proposed enhanced components, including a CRF-modulated depth estimation module enforcing object-level consistencies, a long-term temporal aggregation module with extended receptive fields, and a two-stage object decoder combining perspective techniques with CRF-modulated depth embedding. These enhancements lead to a "modernized" dense BEV framework dubbed BEVNeXt. On the nuScenes benchmark, BEVNeXt outperforms both BEV-based and query-based frameworks under various settings, achieving a state-of-the-art result of 64.2 NDS on the nuScenes test set.
SEGIC: Unleashing the Emergent Correspondence for In-Context Segmentation
Nov 24, 2023



In-context segmentation aims at segmenting novel images using a few labeled example images, termed as "in-context examples", exploring content similarities between examples and the target. The resulting models can be generalized seamlessly to novel segmentation tasks, significantly reducing the labeling and training costs compared with conventional pipelines. However, in-context segmentation is more challenging than classic ones due to its meta-learning nature, requiring the model to learn segmentation rules conditioned on a few samples, not just the segmentation. Unlike previous work with ad-hoc or non-end-to-end designs, we propose SEGIC, an end-to-end segment-in-context framework built upon a single vision foundation model (VFM). In particular, SEGIC leverages the emergent correspondence within VFM to capture dense relationships between target images and in-context samples. As such, information from in-context samples is then extracted into three types of instructions, i.e. geometric, visual, and meta instructions, serving as explicit conditions for the final mask prediction. SEGIC is a straightforward yet effective approach that yields state-of-the-art performance on one-shot segmentation benchmarks. Notably, SEGIC can be easily generalized to diverse tasks, including video object segmentation and open-vocabulary segmentation. Code will be available at \url{https://github.com/MengLcool/SEGIC}.
Towards Viewpoint Robustness in Bird's Eye View Segmentation
Sep 11, 2023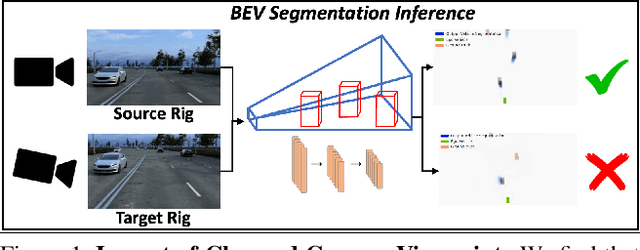


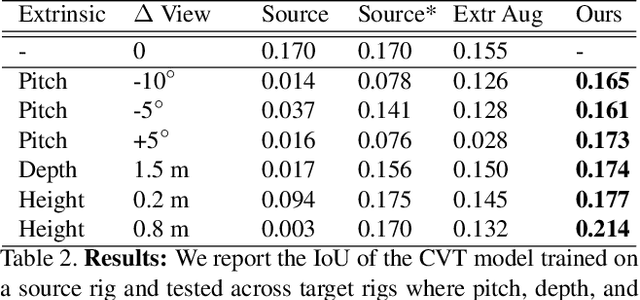
Autonomous vehicles (AV) require that neural networks used for perception be robust to different viewpoints if they are to be deployed across many types of vehicles without the repeated cost of data collection and labeling for each. AV companies typically focus on collecting data from diverse scenarios and locations, but not camera rig configurations, due to cost. As a result, only a small number of rig variations exist across most fleets. In this paper, we study how AV perception models are affected by changes in camera viewpoint and propose a way to scale them across vehicle types without repeated data collection and labeling. Using bird's eye view (BEV) segmentation as a motivating task, we find through extensive experiments that existing perception models are surprisingly sensitive to changes in camera viewpoint. When trained with data from one camera rig, small changes to pitch, yaw, depth, or height of the camera at inference time lead to large drops in performance. We introduce a technique for novel view synthesis and use it to transform collected data to the viewpoint of target rigs, allowing us to train BEV segmentation models for diverse target rigs without any additional data collection or labeling cost. To analyze the impact of viewpoint changes, we leverage synthetic data to mitigate other gaps (content, ISP, etc). Our approach is then trained on real data and evaluated on synthetic data, enabling evaluation on diverse target rigs. We release all data for use in future work. Our method is able to recover an average of 14.7% of the IoU that is otherwise lost when deploying to new rigs.
FB-BEV: BEV Representation from Forward-Backward View Transformations
Aug 17, 2023



View Transformation Module (VTM), where transformations happen between multi-view image features and Bird-Eye-View (BEV) representation, is a crucial step in camera-based BEV perception systems. Currently, the two most prominent VTM paradigms are forward projection and backward projection. Forward projection, represented by Lift-Splat-Shoot, leads to sparsely projected BEV features without post-processing. Backward projection, with BEVFormer being an example, tends to generate false-positive BEV features from incorrect projections due to the lack of utilization on depth. To address the above limitations, we propose a novel forward-backward view transformation module. Our approach compensates for the deficiencies in both existing methods, allowing them to enhance each other to obtain higher quality BEV representations mutually. We instantiate the proposed module with FB-BEV, which achieves a new state-of-the-art result of 62.4% NDS on the nuScenes test set. Code and models are available at https://github.com/NVlabs/FB-BEV.