 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCKSTRING: easy molecular docking yields better benchmarks for ligand design
Oct 29, 2021
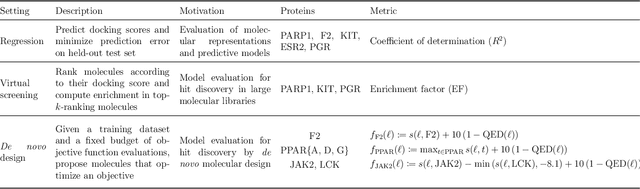
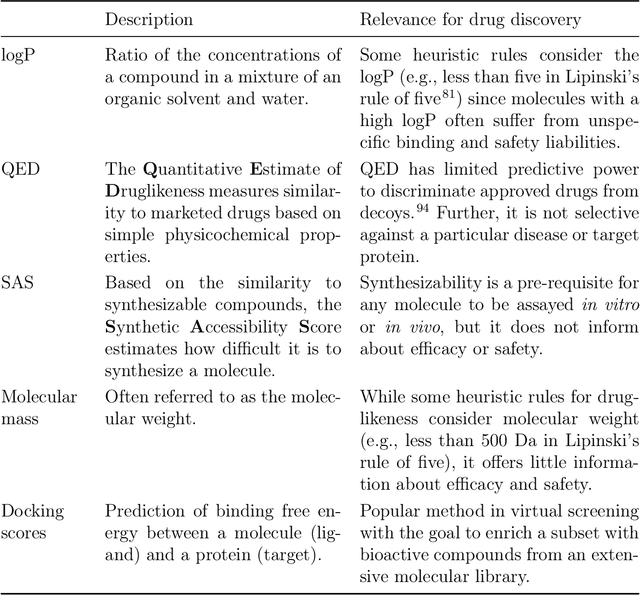
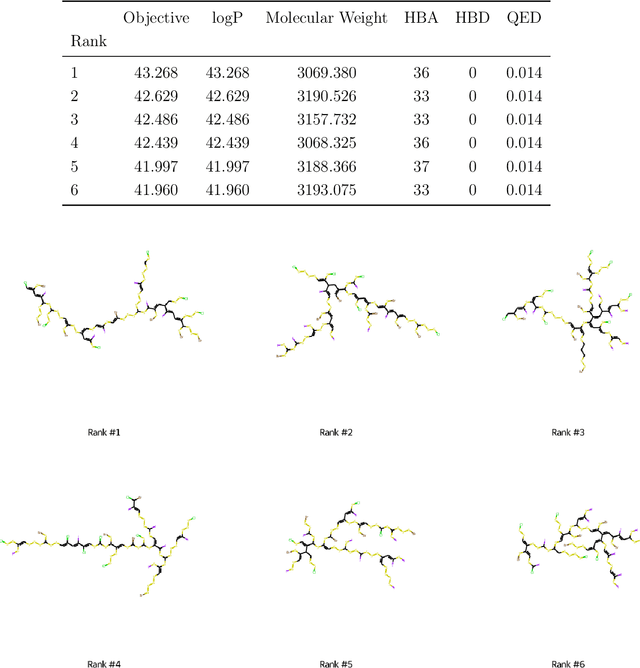
The field of machine learning for drug discovery is witnessing an explosion of novel methods. These methods are often benchmarked on simple physicochemical properties such as solubility or general druglikeness, which can be readily computed. However, these properties are poor representatives of objective functions in drug design, mainly because they do not depend on the candidate's interaction with the target. By contrast, molecular docking is a widely successful method in drug discovery to estimate binding affinities. However, docking simulations require a significant amount of domain knowledge to set up correctly which hampers adoption. To this end, we present DOCKSTRING, a bundle for meaningful and robust comparison of ML models consisting of three components: (1) an open-source Python package for straightforward computation of docking scores; (2) an extensive dataset of docking scores and poses of more than 260K ligands for 58 medically-relevant targets; and (3) a set of pharmaceutically-relevant benchmark tasks including regression, virtual screening, and de novo design. The Python package implements a robust ligand and target preparation protocol that allows non-experts to obtain meaningful docking scores. Our dataset is the first to include docking poses, as well as the first of its size that is a full matrix, thus facilitating experiments in multiobjective optimization and transfer learning. Overall, our results indicate that docking scores are a more appropriate evaluation objective than simple physicochemical properties, yielding more realistic benchmark tasks and molecular candidates.
Scalable One-Pass Optimisation of High-Dimensional Weight-Update Hyperparameters by Implicit Differentiation
Oct 20, 2021



Machine learning training methods depend plentifully and intricately on hyperparameters, motivating automated strategies for their optimisation. Many existing algorithms restart training for each new hyperparameter choice, at considerable computational cost. Some hypergradient-based one-pass methods exist, but these either cannot be applied to arbitrary optimiser hyperparameters (such as learning rates and momenta) or take several times longer to train than their base models. We extend these existing methods to develop an approximate hypergradient-based hyperparameter optimiser which is applicable to any continuous hyperparameter appearing in a differentiable model weight update, yet requires only one training episode, with no restarts. We also provide a motivating argument for convergence to the true hypergradient, and perform tractable gradient-based optimisation of independent learning rates for each model parameter. Our method performs competitively from varied random hyperparameter initialisations on several UCI datasets and Fashion-MNIST (using a one-layer MLP), Penn Treebank (using an LSTM) and CIFAR-10 (using a ResNet-18), in time only 2-3x greater than vanilla training.
Action-Sufficient State Representation Learning for Control with Structural Constraints
Oct 12, 2021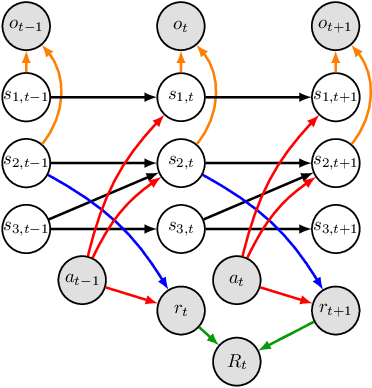
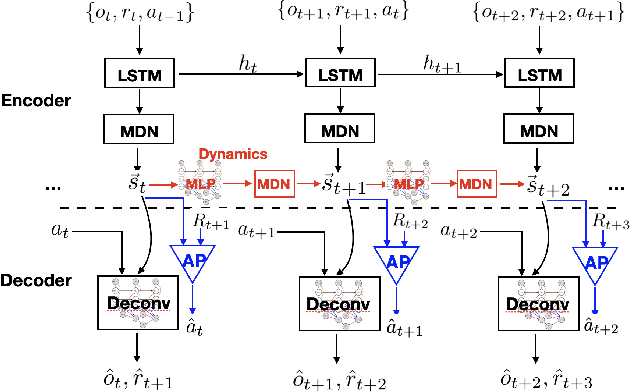

Perceived signals in real-world scenarios are usually high-dimensional and noisy, and finding and using their representation that contains essential and sufficient information required by downstream decision-making tasks will help improve computational efficiency and generalization ability in the tasks. In this paper, we focus on partially observable environments and propose to learn a minimal set of state representations that capture sufficient information for decision-making, termed \textit{Action-Sufficient state Representations} (ASRs). We build a generative environment model for the structural relationships among variables in the system and present a principled way to characterize ASRs based on structural constraints and the goal of maximizing cumulative reward in policy learning. We then develop a structured sequential Variational Auto-Encoder to estimate the environment model and extract ASRs. Our empirical results on CarRacing and VizDoom demonstrate a clear advantage of learning and using ASRs for policy learning. Moreover, the estimated environment model and ASRs allow learning behaviors from imagined outcomes in the compact latent space to improve sample efficiency.
Improving black-box optimization in VAE latent space using decoder uncertainty
Jun 30, 2021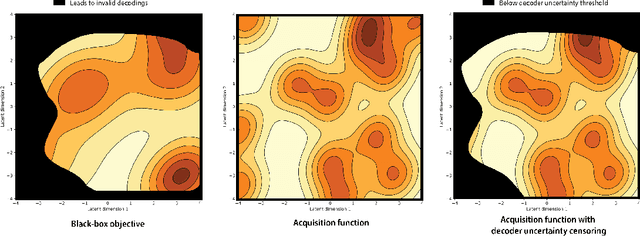
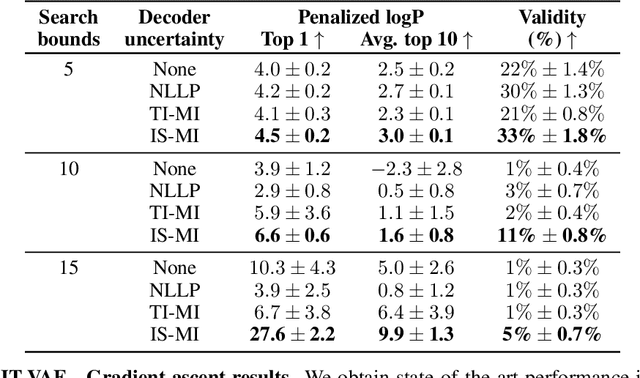


Optimization in the latent space of variational autoencoders is a promising approach to generate high-dimensional discrete objects that maximize an expensive black-box property (e.g., drug-likeness in molecular generation, function approximation with arithmetic expressions). However, existing methods lack robustness as they may decide to explore areas of the latent space for which no data was available during training and where the decoder can be unreliable, leading to the generation of unrealistic or invalid objects. We propose to leverage the epistemic uncertainty of the decoder to guide the optimization process. This is not trivial though, as a naive estimation of uncertainty in the high-dimensional and structured settings we consider would result in high estimator variance. To solve this problem, we introduce an importance sampling-based estimator that provides more robust estimates of epistemic uncertainty. Our uncertainty-guided optimization approach does not require modifications of the model architecture nor the training process. It produces samples with a better trade-off between black-box objective and validity of the generated samples, sometimes improving both simultaneously. We illustrate these advantages across several experimental settings in digit generation, arithmetic expression approximation and molecule generation for drug design.
Contextual HyperNetworks for Novel Feature Adaptation
Apr 12, 2021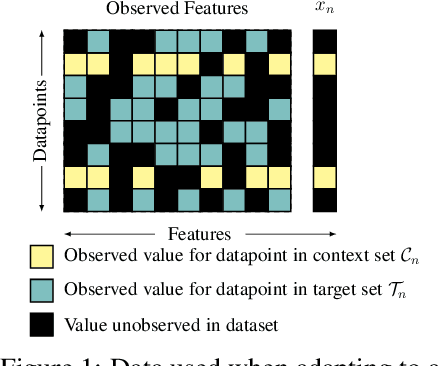
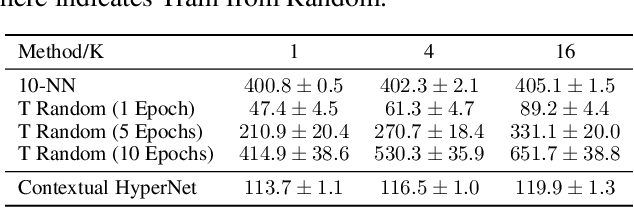
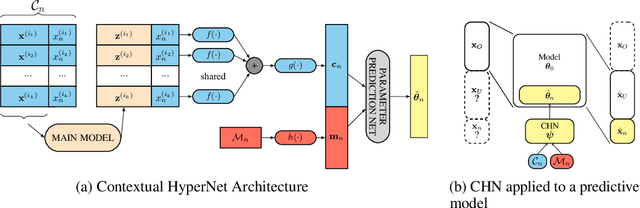
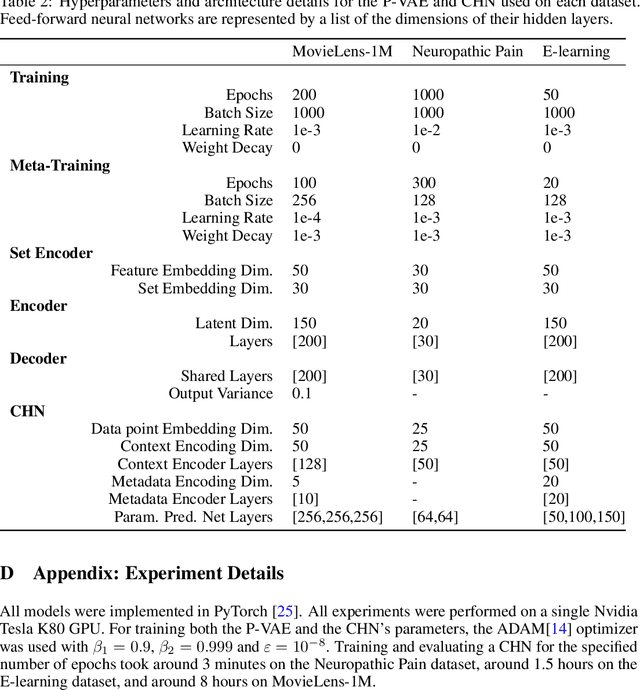
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.
Active Slices for Sliced Stein Discrepancy
Feb 08, 2021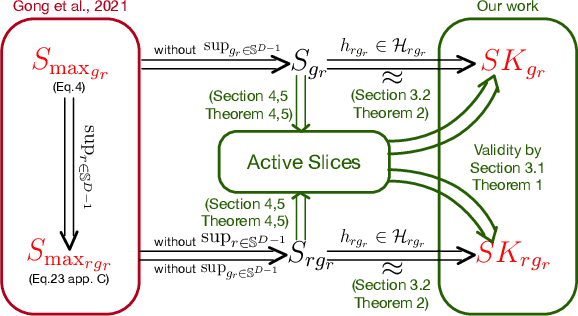
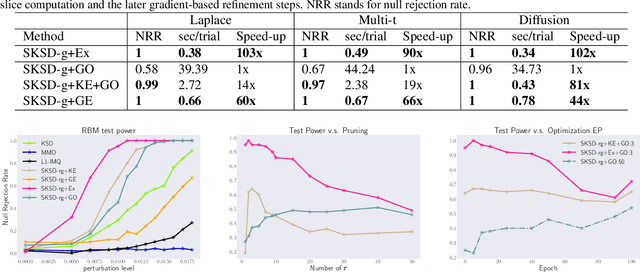
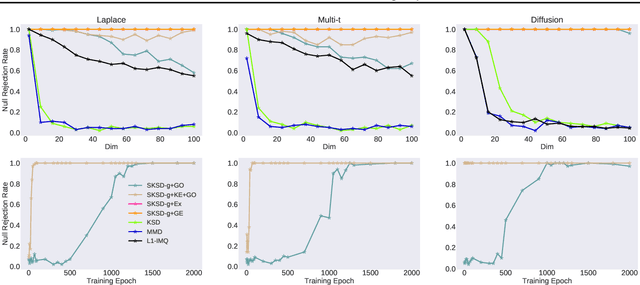

Sliced Stein discrepancy (SSD) and its kernelized variants have demonstrated promising successes in goodness-of-fit tests and model learning in high dimensions. Despite their theoretical elegance, their empirical performance depends crucially on the search of optimal slicing directions to discriminate between two distributions. Unfortunately, previous gradient-based optimisation approaches for this task return sub-optimal results: they are computationally expensive, sensitive to initialization, and they lack theoretical guarantees for convergence. We address these issues in two steps. First, we provide theoretical results stating that the requirement of using optimal slicing directions in the kernelized version of SSD can be relaxed, validating the resulting discrepancy with finite random slicing directions. Second, given that good slicing directions are crucial for practical performance, we propose a fast algorithm for finding such slicing directions based on ideas of active sub-space construction and spectral decomposition. Experiments on goodness-of-fit tests and model learning show that our approach achieves both improved performance and faster convergence. Especially, we demonstrate a 14-80x speed-up in goodness-of-fit tests when comparing with gradient-based alternatives.
Barking up the right tree: an approach to search over molecule synthesis DAGs
Dec 21, 2020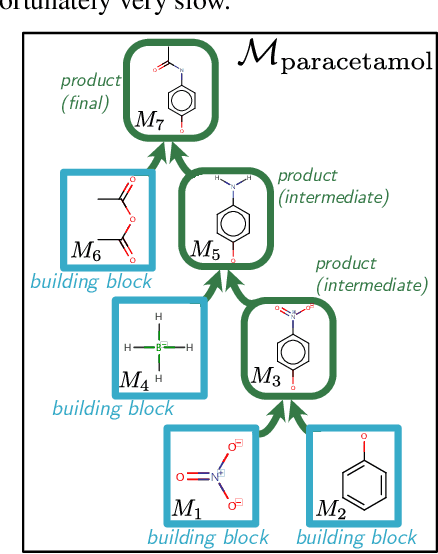
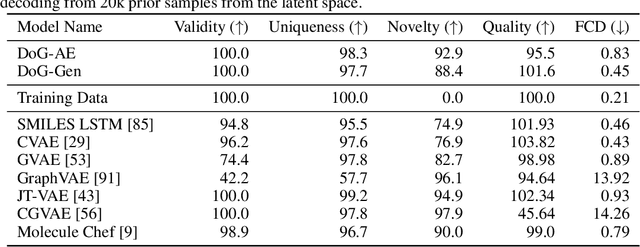
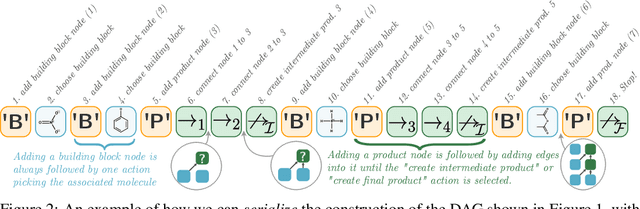

When designing new molecules with particular properties, it is not only important what to make but crucially how to make it. These instructions form a synthesis directed acyclic graph (DAG), describing how a large vocabulary of simple building blocks can be recursively combined through chemical reactions to create more complicated molecules of interest. In contrast, many current deep generative models for molecules ignore synthesizability. We therefore propose a deep generative model that better represents the real world process, by directly outputting molecule synthesis DAGs. We argue that this provides sensible inductive biases, ensuring that our model searches over the same chemical space that chemists would also have access to, as well as interpretability. We show that our approach is able to model chemical space well, producing a wide range of diverse molecules, and allows for unconstrained optimization of an inherently constrained problem: maximize certain chemical properties such that discovered molecules are synthesizable.
Sample-Efficient Reinforcement Learning via Counterfactual-Based Data Augmentation
Dec 16, 2020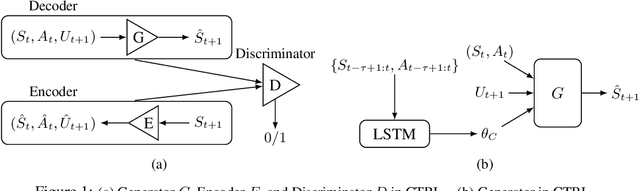
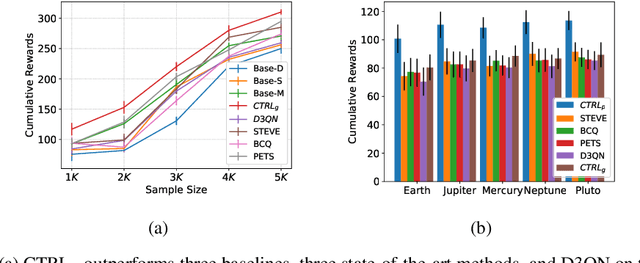

Reinforcement learning (RL) algorithms usually require a substantial amount of interaction data and perform well only for specific tasks in a fixed environment. In some scenarios such as healthcare, however, usually only few records are available for each patient, and patients may show different responses to the same treatment, impeding the application of current RL algorithms to learn optimal policies. To address the issues of mechanism heterogeneity and related data scarcity, we propose a data-efficient RL algorithm that exploits structural causal models (SCMs) to model the state dynamics, which are estimated by leveraging both commonalities and differences across subjects. The learned SCM enables us to counterfactually reason what would have happened had another treatment been taken. It helps avoid real (possibly risky) exploration and mitigates the issue that limited experiences lead to biased policies. We propose counterfactual RL algorithms to learn both population-level and individual-level policies. We show that counterfactual outcomes are identifiable under mild conditions and that Q- learning on the counterfactual-based augmented data set converges to the optimal value function. Experimental results on synthetic and real-world data demonstrate the efficacy of the proposed approach.
FIT: a Fast and Accurate Framework for Solving Medical Inquiring and Diagnosing Tasks
Dec 02, 2020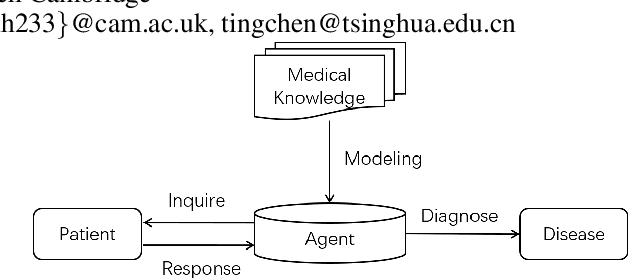

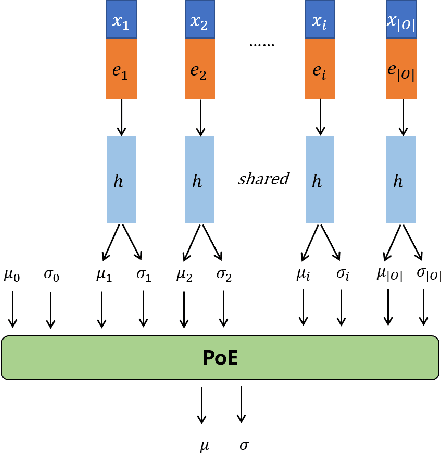

Automatic self-diagnosis provides low-cost and accessible healthcare via an agent that queries the patient and makes predictions about possible diseases. From a machine learning perspective, symptom-based self-diagnosis can be viewed as a sequential feature selection and classification problem. Reinforcement learning methods have shown good performance in this task but often suffer from large search spaces and costly training. To address these problems, we propose a competitive framework, called FIT, which uses an information-theoretic reward to determine what data to collect next. FIT improves over previous information-based approaches by using a multimodal variational autoencoder (MVAE) model and a two-step sampling strategy for disease prediction. Furthermore, we propose novel methods to substantially reduce the computational cost of FIT to a level that is acceptable for practical online self-diagnosis. Our results in two simulated datasets show that FIT can effectively deal with large search space problems, outperforming existing baselines. Moreover, using two medical datasets, we show that FIT is a competitive alternative in real-world settings.
Symmetry-Aware Actor-Critic for 3D Molecular Design
Nov 25, 2020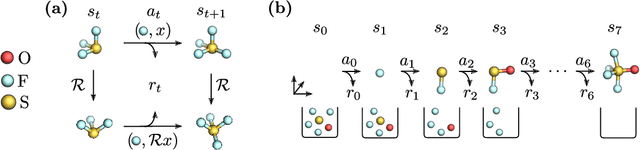
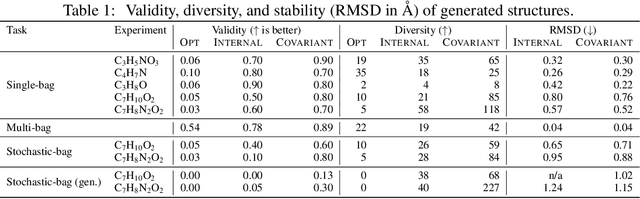
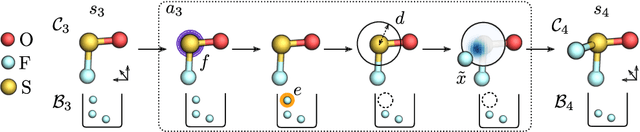

Automating molecular design using deep reinforcement learning (RL) has the potential to greatly accelerate the search for novel materials. Despite recent progress on leveraging graph representations to design molecules, such methods are fundamentally limited by the lack of three-dimensional (3D) information. In light of this, we propose a novel actor-critic architecture for 3D molecular design that can generate molecular structures unattainable with previous approaches. This is achieved by exploiting the symmetries of the design process through a rotationally covariant state-action representation based on a spherical harmonics series expansion. We demonstrate the benefits of our approach on several 3D molecular design tasks, where we find that building in such symmetries significantly improves generalization and the quality of generated molecules.