 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Cannot Feed Two Birds with One Score: the Accuracy-Naturalness Tradeoff in Translation
Apr 01, 2025The goal of translation, be it by human or by machine, is, given some text in a source language, to produce text in a target language that simultaneously 1) preserves the meaning of the source text and 2) achieves natural expression in the target language. However, researchers in the machine translation community usually assess translations using a single score intended to capture semantic accuracy and the naturalness of the output simultaneously. In this paper, we build on recent advances in information theory to mathematically prove and empirically demonstrate that such single-score summaries do not and cannot give the complete picture of a system's true performance. Concretely, we prove that a tradeoff exists between accuracy and naturalness and demonstrate it by evaluating the submissions to the WMT24 shared task. Our findings help explain well-known empirical phenomena, such as the observation that optimizing translation systems for a specific accuracy metric (like BLEU) initially improves the system's naturalness, while ``overfitting'' the system to the metric can significantly degrade its naturalness. Thus, we advocate for a change in how translations are evaluated: rather than comparing systems using a single number, they should be compared on an accuracy-naturalness plane.
Getting Free Bits Back from Rotational Symmetries in LLMs
Oct 02, 2024


Current methods for compressing neural network weights, such as decomposition, pruning, quantization, and channel simulation, often overlook the inherent symmetries within these networks and thus waste bits on encoding redundant information. In this paper, we propose a format based on bits-back coding for storing rotationally symmetric Transformer weights more efficiently than the usual array layout at the same floating-point precision. We evaluate our method on Large Language Models (LLMs) pruned by SliceGPT (Ashkboos et al., 2024) and achieve a 3-5% reduction in total bit usage for free across different model sizes and architectures without impacting model performance within a certain numerical precision.
Accelerating Relative Entropy Coding with Space Partitioning
May 20, 2024



Relative entropy coding (REC) algorithms encode a random sample following a target distribution $Q$, using a coding distribution $P$ shared between the sender and receiver. Sadly, general REC algorithms suffer from prohibitive encoding times, at least on the order of $2^{D_{\text{KL}}[Q||P]}$, and faster algorithms are limited to very specific settings. This work addresses this issue by introducing a REC scheme utilizing space partitioning to reduce runtime in practical scenarios. We provide theoretical analyses of our method and demonstrate its effectiveness with both toy examples and practical applications. Notably, our method successfully handles REC tasks with $D_{\text{KL}}[Q||P]$ about three times what previous methods can manage and reduces the compression rate by approximately 5-15\% in VAE-based lossless compression on MNIST and INR-based lossy compression on CIFAR-10 compared to previous methods, significantly improving the practicality of REC for neural compression.
Some Notes on the Sample Complexity of Approximate Channel Simulation
May 14, 2024Channel simulation algorithms can efficiently encode random samples from a prescribed target distribution $Q$ and find applications in machine learning-based lossy data compression. However, algorithms that encode exact samples usually have random runtime, limiting their applicability when a consistent encoding time is desirable. Thus, this paper considers approximate schemes with a fixed runtime instead. First, we strengthen a result of Agustsson and Theis and show that there is a class of pairs of target distribution $Q$ and coding distribution $P$, for which the runtime of any approximate scheme scales at least super-polynomially in $D_\infty[Q \Vert P]$. We then show, by contrast, that if we have access to an unnormalised Radon-Nikodym derivative $r \propto dQ/dP$ and knowledge of $D_{KL}[Q \Vert P]$, we can exploit global-bound, depth-limited A* coding to ensure $\mathrm{TV}[Q \Vert P] \leq \epsilon$ and maintain optimal coding performance with a sample complexity of only $\exp_2\big((D_{KL}[Q \Vert P] + o(1)) \big/ \epsilon\big)$.
Estimating optimal PAC-Bayes bounds with Hamiltonian Monte Carlo
Oct 30, 2023



An important yet underexplored question in the PAC-Bayes literature is how much tightness we lose by restricting the posterior family to factorized Gaussian distributions when optimizing a PAC-Bayes bound. We investigate this issue by estimating data-independent PAC-Bayes bounds using the optimal posteriors, comparing them to bounds obtained using MFVI. Concretely, we (1) sample from the optimal Gibbs posterior using Hamiltonian Monte Carlo, (2) estimate its KL divergence from the prior with thermodynamic integration, and (3) propose three methods to obtain high-probability bounds under different assumptions. Our experiments on the MNIST dataset reveal significant tightness gaps, as much as 5-6\% in some cases.
RECOMBINER: Robust and Enhanced Compression with Bayesian Implicit Neural Representations
Sep 29, 2023



COMpression with Bayesian Implicit NEural Representations (COMBINER) is a recent data compression method that addresses a key inefficiency of previous Implicit Neural Representation (INR)-based approaches: it avoids quantization and enables direct optimization of the rate-distortion performance. However, COMBINER still has significant limitations: 1) it uses factorized priors and posterior approximations that lack flexibility; 2) it cannot effectively adapt to local deviations from global patterns in the data; and 3) its performance can be susceptible to modeling choices and the variational parameters' initializations. Our proposed method, Robust and Enhanced COMBINER (RECOMBINER), addresses these issues by 1) enriching the variational approximation while maintaining its computational cost via a linear reparameterization of the INR weights, 2) augmenting our INRs with learnable positional encodings that enable them to adapt to local details and 3) splitting high-resolution data into patches to increase robustness and utilizing expressive hierarchical priors to capture dependency across patches. We conduct extensive experiments across several data modalities, showcasing that RECOMBINER achieves competitive results with the best INR-based methods and even outperforms autoencoder-based codecs on low-resolution images at low bitrates.
Minimal Random Code Learning with Mean-KL Parameterization
Jul 15, 2023


This paper studies the qualitative behavior and robustness of two variants of Minimal Random Code Learning (MIRACLE) used to compress variational Bayesian neural networks. MIRACLE implements a powerful, conditionally Gaussian variational approximation for the weight posterior $Q_{\mathbf{w}}$ and uses relative entropy coding to compress a weight sample from the posterior using a Gaussian coding distribution $P_{\mathbf{w}}$. To achieve the desired compression rate, $D_{\mathrm{KL}}[Q_{\mathbf{w}} \Vert P_{\mathbf{w}}]$ must be constrained, which requires a computationally expensive annealing procedure under the conventional mean-variance (Mean-Var) parameterization for $Q_{\mathbf{w}}$. Instead, we parameterize $Q_{\mathbf{w}}$ by its mean and KL divergence from $P_{\mathbf{w}}$ to constrain the compression cost to the desired value by construction. We demonstrate that variational training with Mean-KL parameterization converges twice as fast and maintains predictive performance after compression. Furthermore, we show that Mean-KL leads to more meaningful variational distributions with heavier tails and compressed weight samples which are more robust to pruning.
Compression with Bayesian Implicit Neural Representations
May 30, 2023



Many common types of data can be represented as functions that map coordinates to signal values, such as pixel locations to RGB values in the case of an image. Based on this view, data can be compressed by overfitting a compact neural network to its functional representation and then encoding the network weights. However, most current solutions for this are inefficient, as quantization to low-bit precision substantially degrades the reconstruction quality. To address this issue, we propose overfitting variational Bayesian neural networks to the data and compressing an approximate posterior weight sample using relative entropy coding instead of quantizing and entropy coding it. This strategy enables direct optimization of the rate-distortion performance by minimizing the $\beta$-ELBO, and target different rate-distortion trade-offs for a given network architecture by adjusting $\beta$. Moreover, we introduce an iterative algorithm for learning prior weight distributions and employ a progressive refinement process for the variational posterior that significantly enhances performance. Experiments show that our method achieves strong performance on image and audio compression while retaining simplicity.
Compressing Images by Encoding Their Latent Representations with Relative Entropy Coding
Oct 27, 2020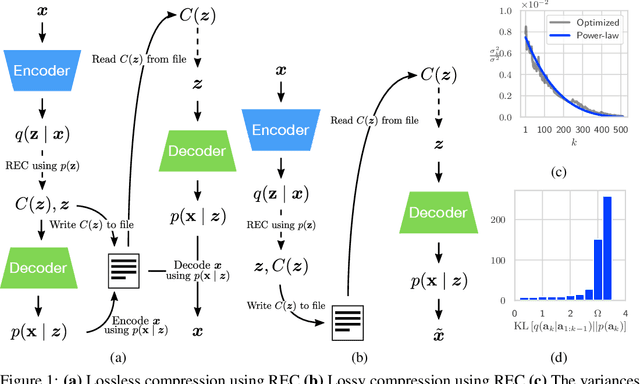
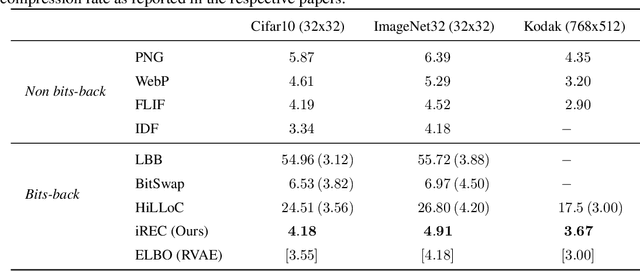
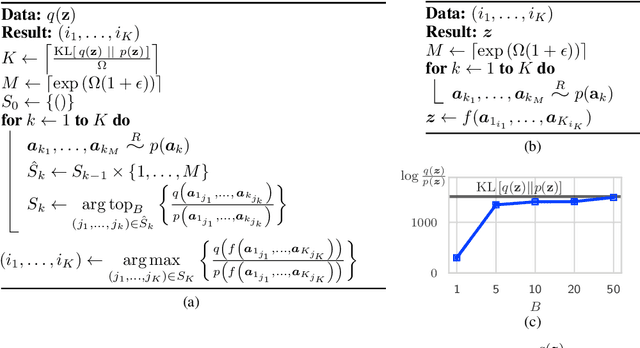
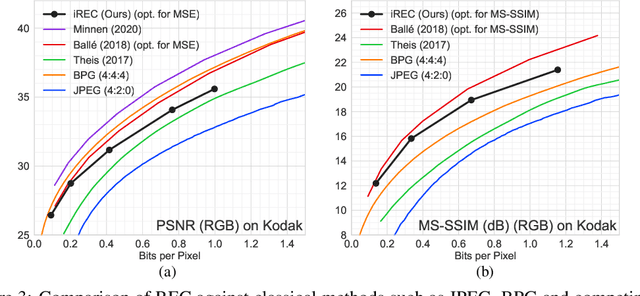
Variational Autoencoders (VAEs) have seen widespread use in learned image compression. They are used to learn expressive latent representations on which downstream compression methods can operate with high efficiency. Recently proposed 'bits-back' methods can indirectly encode the latent representation of images with codelength close to the relative entropy between the latent posterior and the prior. However, due to the underlying algorithm, these methods can only be used for lossless compression, and they only achieve their nominal efficiency when compressing multiple images simultaneously; they are inefficient for compressing single images. As an alternative, we propose a novel method, Relative Entropy Coding (REC), that can directly encode the latent representation with codelength close to the relative entropy for single images, supported by our empirical results obtained on the Cifar10, ImageNet32 and Kodak datasets. Moreover, unlike previous bits-back methods, REC is immediately applicable to lossy compression, where it is competitive with the state-of-the-art on the Kodak dataset.