 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Synthetic Web: Adversarially-Curated Mini-Internets for Diagnosing Epistemic Weaknesses of Language Agents
Feb 28, 2026Language agents increasingly act as web-enabled systems that search, browse, and synthesize information from diverse sources. However, these sources can include unreliable or adversarial content, and the robustness of agents to adversarial ranking - where misleading information appears prominently in search results - remains poorly understood. Existing benchmarks evaluate functional navigation or static factuality but cannot causally isolate this vulnerability, and current mitigation strategies for retrieval-augmented generation remain largely untested under such conditions. We introduce Synthetic Web Benchmark, a procedurally generated environment comprising thousands of hyperlinked articles with ground-truth labels for credibility and factuality, process-level interaction traces, and contamination filtering to eliminate training-data leakage. By injecting a single high-plausibility misinformation article into a controllable search rank, we measure the causal effect of adversarial exposure in six frontier models. The results reveal catastrophic failures: accuracy collapses despite unlimited access to truthful sources, with minimal search escalation and severe miscalibration. These findings expose fundamental limitations in how current frontier models handle conflicting information, with immediate implications for deployment in high-stakes domains. Our benchmark enables systematic analysis of these failure modes and provides a controlled testbed for evaluating mitigation strategies under adversarial ranking - a gap in current research. This work establishes a reproducible baseline for developing search-robust and epistemically humble agents capable of resisting manipulation in high-stakes domains.
DRIFT: Deep Reinforcement Learning for Functional Software Testing
Jul 16, 2020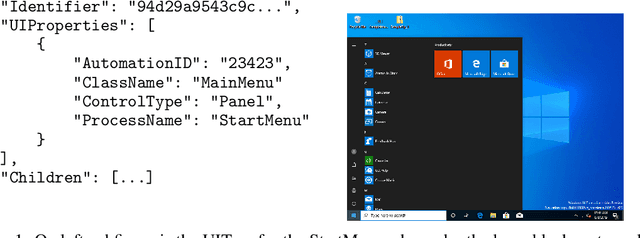
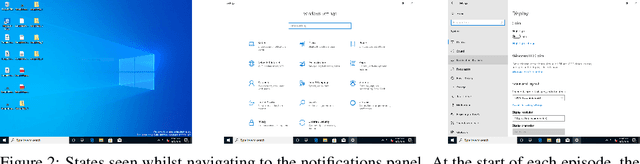
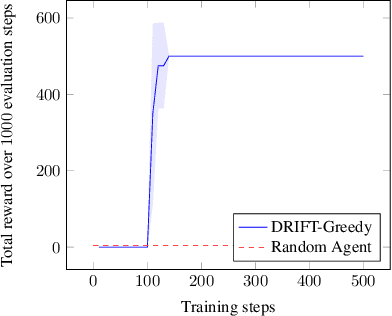

Efficient software testing is essential for productive software development and reliable user experiences. As human testing is inefficient and expensive, automated software testing is needed. In this work, we propose a Reinforcement Learning (RL) framework for functional software testing named DRIFT. DRIFT operates on the symbolic representation of the user interface. It uses Q-learning through Batch-RL and models the state-action value function with a Graph Neural Network. We apply DRIFT to testing the Windows 10 operating system and show that DRIFT can robustly trigger the desired software functionality in a fully automated manner. Our experiments test the ability to perform single and combined tasks across different applications, demonstrating that our framework can efficiently test software with a large range of testing objectives.