 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Reasoning Over Unstructured Text with Beam Dense Retrieval
Apr 13, 2021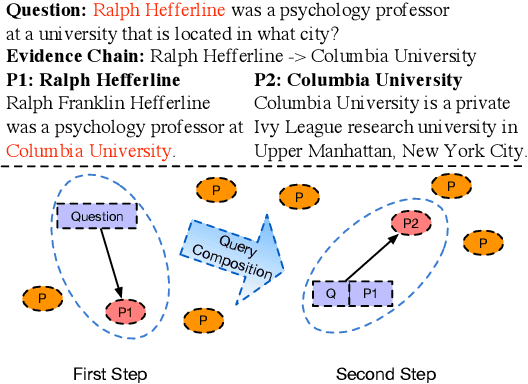
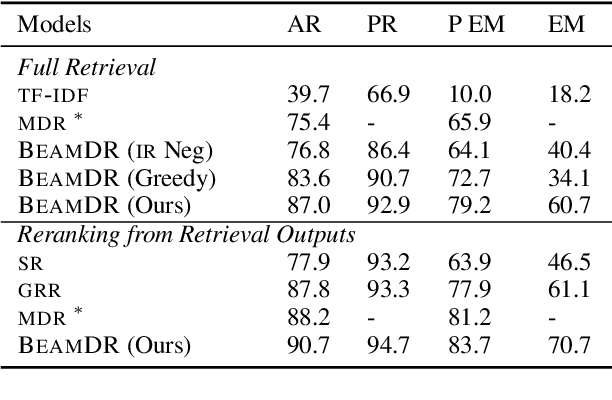
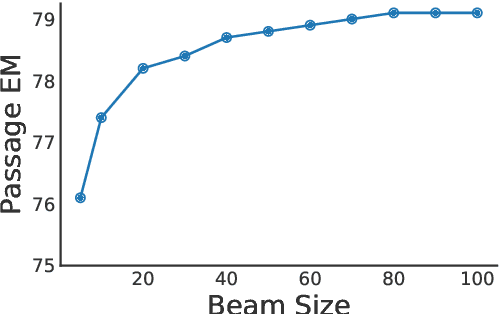
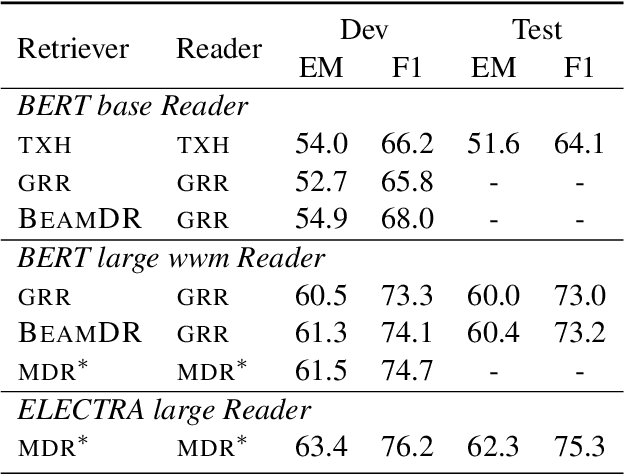
Complex question answering often requires finding a reasoning chain that consists of multiple evidence pieces. Current approaches incorporate the strengths of structured knowledge and unstructured text, assuming text corpora is semi-structured. Building on dense retrieval methods, we propose a new multi-step retrieval approach (BeamDR) that iteratively forms an evidence chain through beam search in dense representations. When evaluated on multi-hop question answering, BeamDR is competitive to state-of-the-art systems, without using any semi-structured information. Through query composition in dense space, BeamDR captures the implicit relationships between evidence in the reasoning chain. The code is available at https://github.com/ henryzhao5852/BeamDR.
Fool Me Twice: Entailment from Wikipedia Gamification
Apr 10, 2021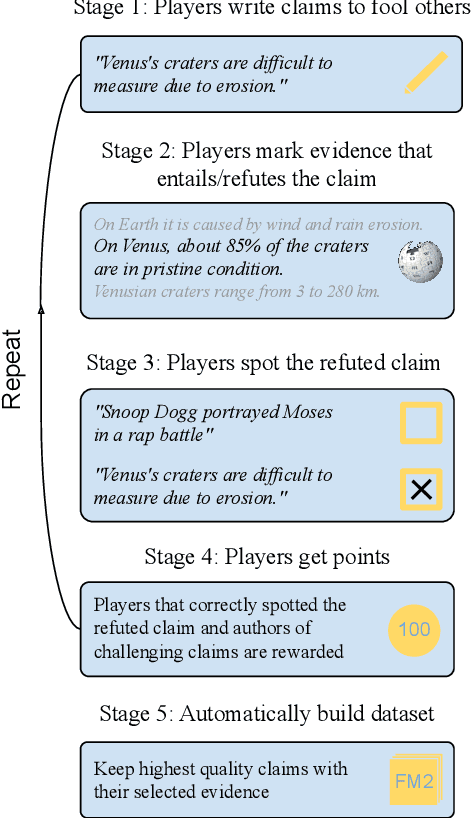
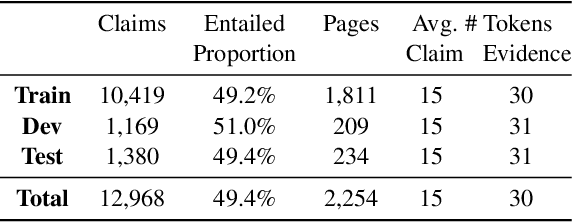

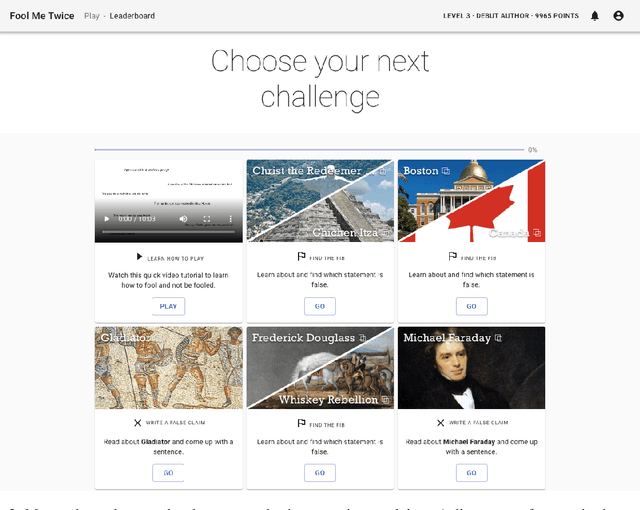
We release FoolMeTwice (FM2 for short), a large dataset of challenging entailment pairs collected through a fun multi-player game. Gamification encourages adversarial examples, drastically lowering the number of examples that can be solved using "shortcuts" compared to other popular entailment datasets. Players are presented with two tasks. The first task asks the player to write a plausible claim based on the evidence from a Wikipedia page. The second one shows two plausible claims written by other players, one of which is false, and the goal is to identify it before the time runs out. Players "pay" to see clues retrieved from the evidence pool: the more evidence the player needs, the harder the claim. Game-play between motivated players leads to diverse strategies for crafting claims, such as temporal inference and diverting to unrelated evidence, and results in higher quality data for the entailment and evidence retrieval tasks. We open source the dataset and the game code.
Complex Factoid Question Answering with a Free-Text Knowledge Graph
Mar 23, 2021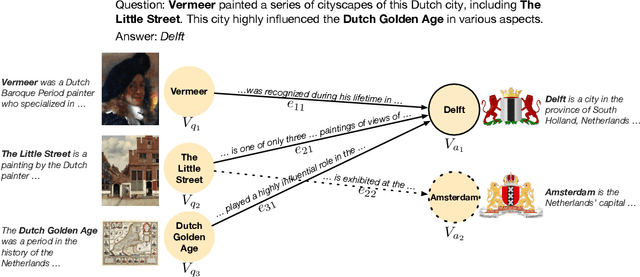
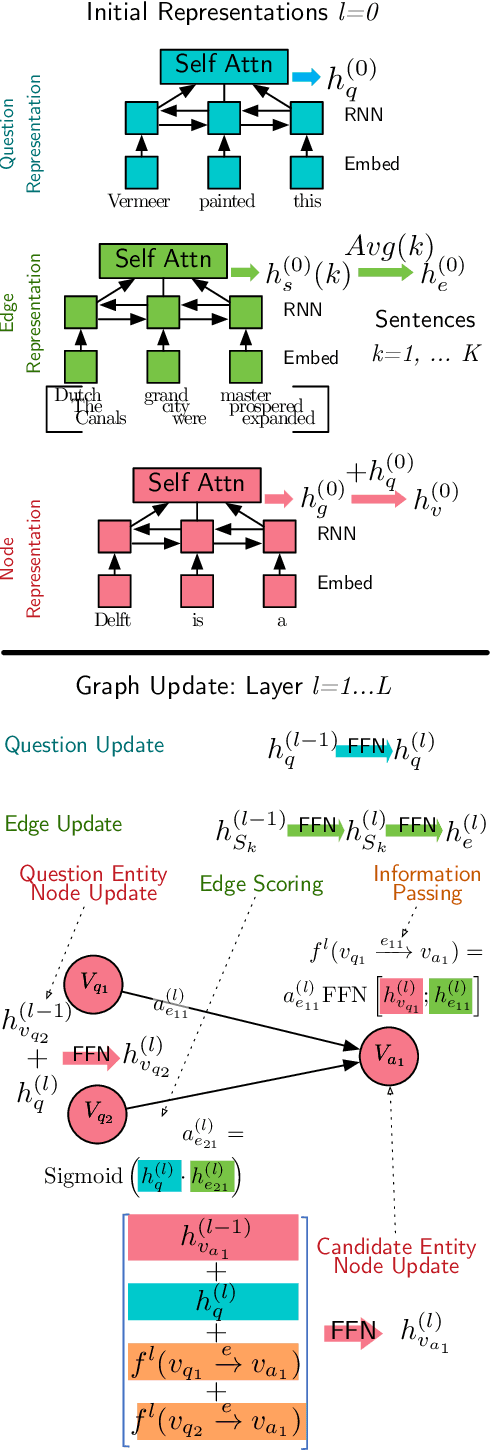

We introduce DELFT, a factoid question answering system which combines the nuance and depth of knowledge graph question answering approaches with the broader coverage of free-text. DELFT builds a free-text knowledge graph from Wikipedia, with entities as nodes and sentences in which entities co-occur as edges. For each question, DELFT finds the subgraph linking question entity nodes to candidates using text sentences as edges, creating a dense and high coverage semantic graph. A novel graph neural network reasons over the free-text graph-combining evidence on the nodes via information along edge sentences-to select a final answer. Experiments on three question answering datasets show DELFT can answer entity-rich questions better than machine reading based models, bert-based answer ranking and memory networks. DELFT's advantage comes from both the high coverage of its free-text knowledge graph-more than double that of dbpedia relations-and the novel graph neural network which reasons on the rich but noisy free-text evidence.
ClimaText: A Dataset for Climate Change Topic Detection
Jan 02, 2021
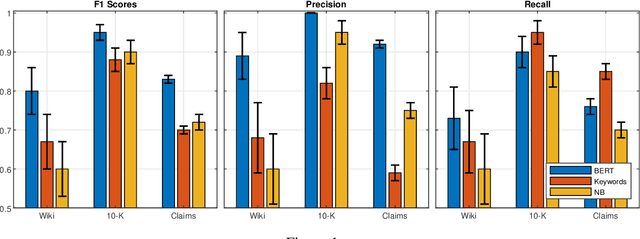

Climate change communication in the mass media and other textual sources may affect and shape public perception. Extracting climate change information from these sources is an important task, e.g., for filtering content and e-discovery, sentiment analysis, automatic summarization, question-answering, and fact-checking. However, automating this process is a challenge, as climate change is a complex, fast-moving, and often ambiguous topic with scarce resources for popular text-based AI tasks. In this paper, we introduce \textsc{ClimaText}, a dataset for sentence-based climate change topic detection, which we make publicly available. We explore different approaches to identify the climate change topic in various text sources. We find that popular keyword-based models are not adequate for such a complex and evolving task. Context-based algorithms like BERT \cite{devlin2018bert} can detect, in addition to many trivial cases, a variety of complex and implicit topic patterns. Nevertheless, our analysis reveals a great potential for improvement in several directions, such as, e.g., capturing the discussion on indirect effects of climate change. Hence, we hope this work can serve as a good starting point for further research on this topic.
CLIMATE-FEVER: A Dataset for Verification of Real-World Climate Claims
Jan 02, 2021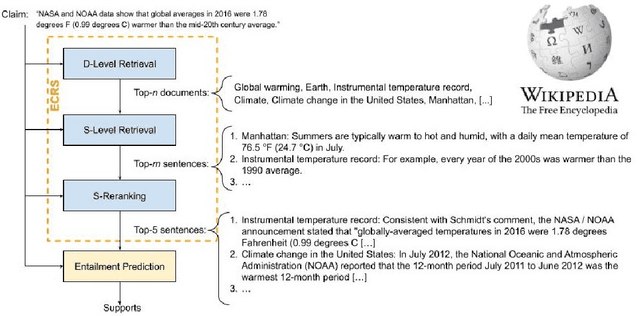
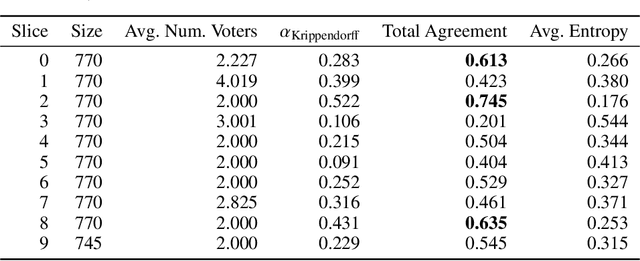
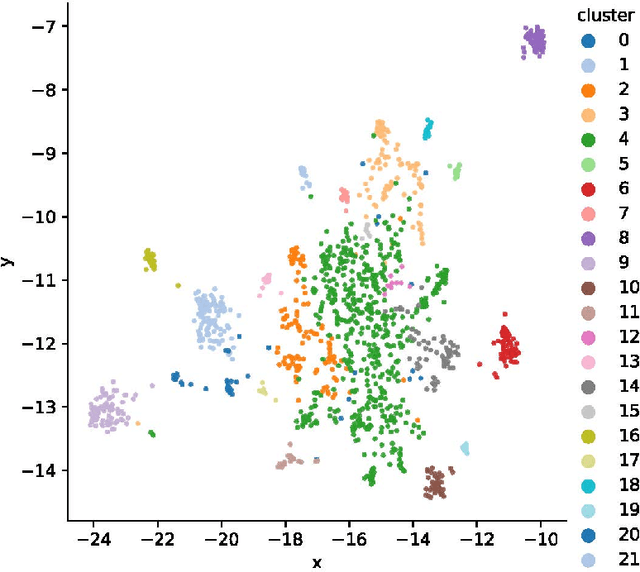
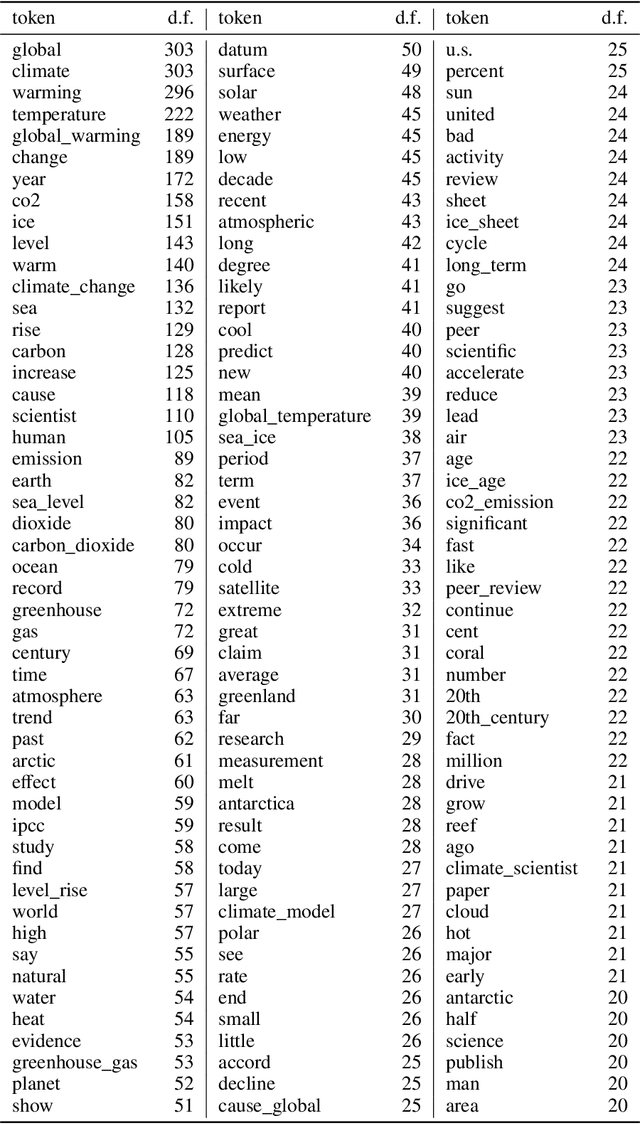
We introduce CLIMATE-FEVER, a new publicly available dataset for verification of climate change-related claims. By providing a dataset for the research community, we aim to facilitate and encourage work on improving algorithms for retrieving evidential support for climate-specific claims, addressing the underlying language understanding challenges, and ultimately help alleviate the impact of misinformation on climate change. We adapt the methodology of FEVER [1], the largest dataset of artificially designed claims, to real-life claims collected from the Internet. While during this process, we could rely on the expertise of renowned climate scientists, it turned out to be no easy task. We discuss the surprising, subtle complexity of modeling real-world climate-related claims within the \textsc{fever} framework, which we believe provides a valuable challenge for general natural language understanding. We hope that our work will mark the beginning of a new exciting long-term joint effort by the climate science and AI community.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021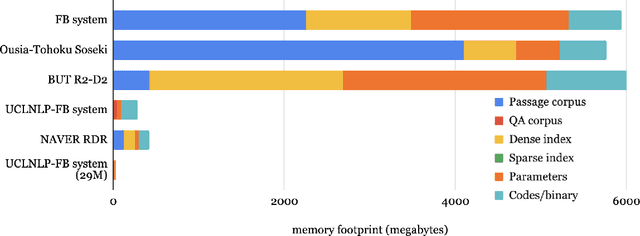
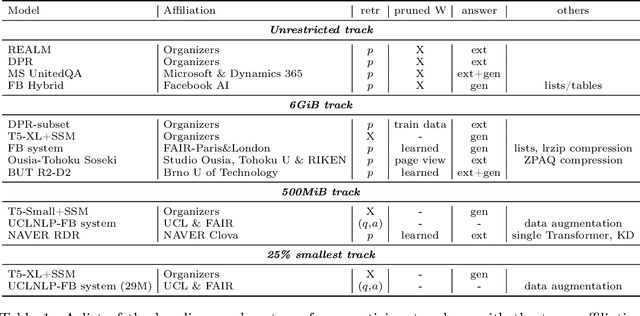
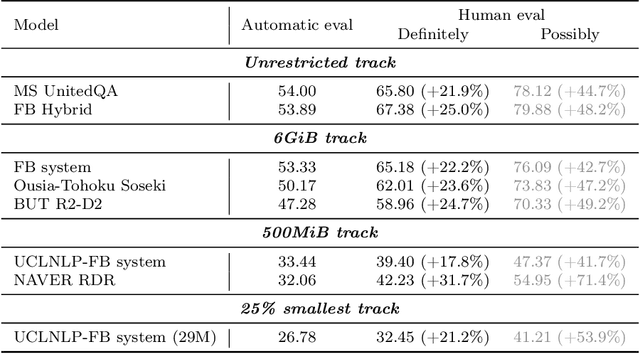
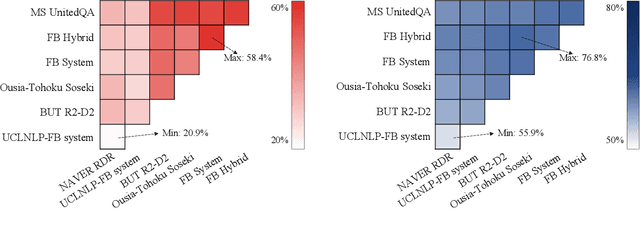
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Cold-start Active Learning through Self-supervised Language Modeling
Oct 22, 2020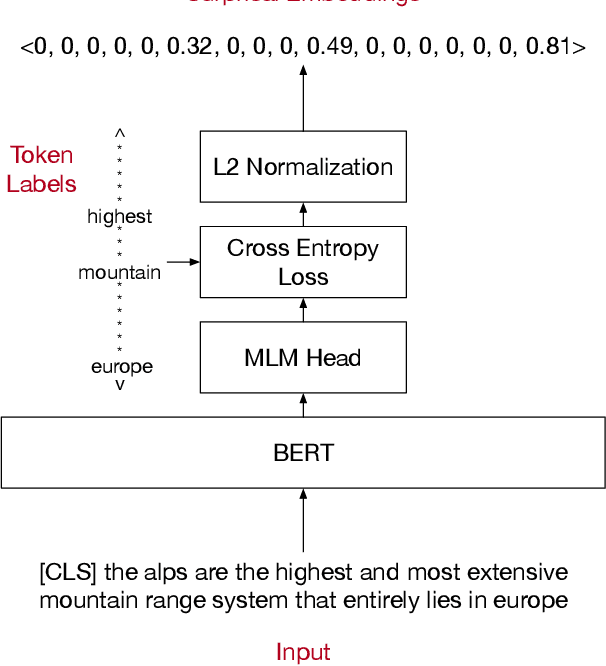
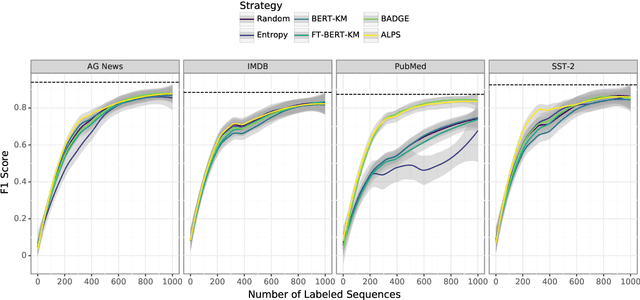

Active learning strives to reduce annotation costs by choosing the most critical examples to label. Typically, the active learning strategy is contingent on the classification model. For instance, uncertainty sampling depends on poorly calibrated model confidence scores. In the cold-start setting, active learning is impractical because of model instability and data scarcity. Fortunately, modern NLP provides an additional source of information: pre-trained language models. The pre-training loss can find examples that surprise the model and should be labeled for efficient fine-tuning. Therefore, we treat the language modeling loss as a proxy for classification uncertainty. With BERT, we develop a simple strategy based on the masked language modeling loss that minimizes labeling costs for text classification. Compared to other baselines, our approach reaches higher accuracy within less sampling iterations and computation time.
On the Potential of Lexico-logical Alignments for Semantic Parsing to SQL Queries
Oct 21, 2020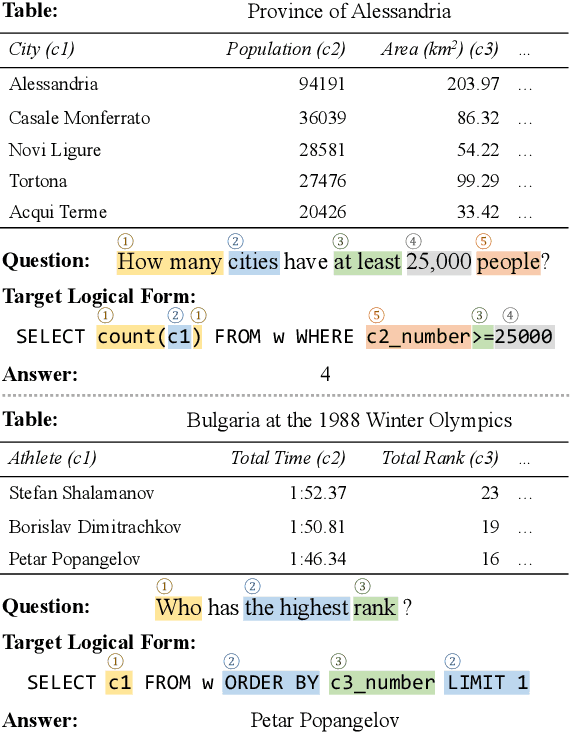
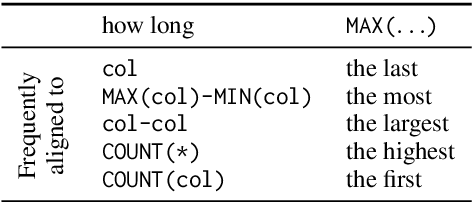
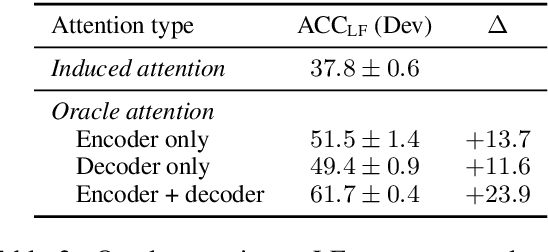
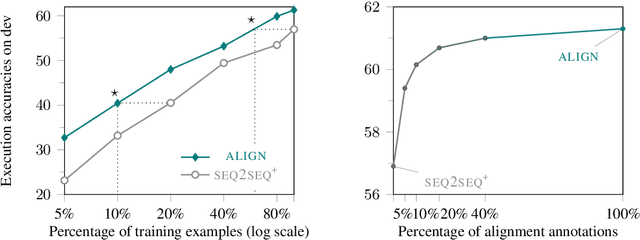
Large-scale semantic parsing datasets annotated with logical forms have enabled major advances in supervised approaches. But can richer supervision help even more? To explore the utility of fine-grained, lexical-level supervision, we introduce Squall, a dataset that enriches 11,276 WikiTableQuestions English-language questions with manually created SQL equivalents plus alignments between SQL and question fragments. Our annotation enables new training possibilities for encoder-decoder models, including approaches from machine translation previously precluded by the absence of alignments. We propose and test two methods: (1) supervised attention; (2) adopting an auxiliary objective of disambiguating references in the input queries to table columns. In 5-fold cross validation, these strategies improve over strong baselines by 4.4% execution accuracy. Oracle experiments suggest that annotated alignments can support further accuracy gains of up to 23.9%.
* Findings of ACL: EMNLP 2020
Why Overfitting Isn't Always Bad: Retrofitting Cross-Lingual Word Embeddings to Dictionaries
May 01, 2020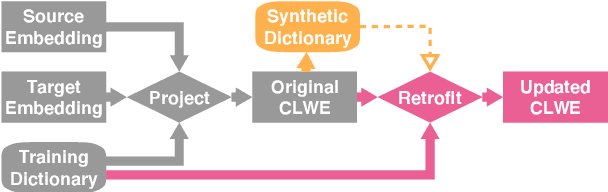
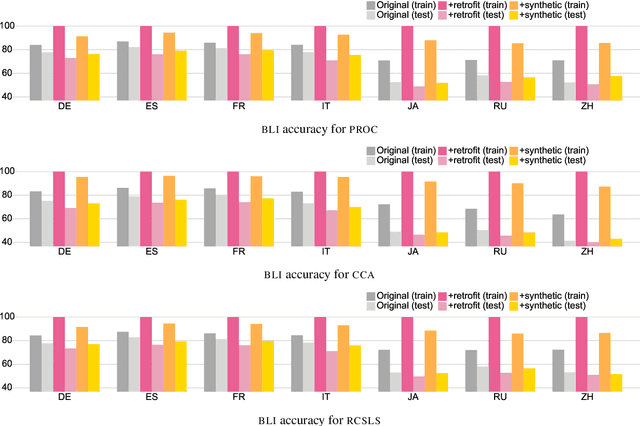
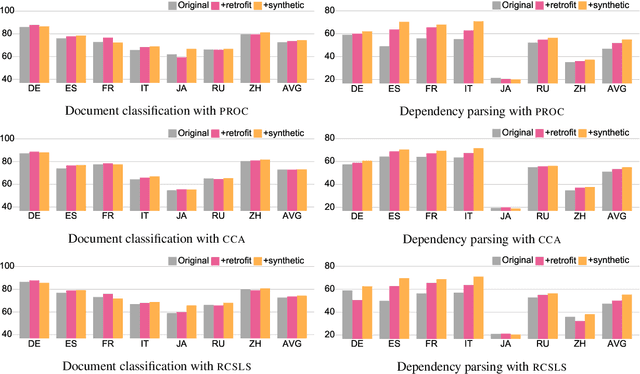
Cross-lingual word embeddings (CLWE) are often evaluated on bilingual lexicon induction (BLI). Recent CLWE methods use linear projections, which underfit the training dictionary, to generalize on BLI. However, underfitting can hinder generalization to other downstream tasks that rely on words from the training dictionary. We address this limitation by retrofitting CLWE to the training dictionary, which pulls training translation pairs closer in the embedding space and overfits the training dictionary. This simple post-processing step often improves accuracy on two downstream tasks, despite lowering BLI test accuracy. We also retrofit to both the training dictionary and a synthetic dictionary induced from CLWE, which sometimes generalizes even better on downstream tasks. Our results confirm the importance of fully exploiting training dictionary in downstream tasks and explains why BLI is a flawed CLWE evaluation.
Meta Answering for Machine Reading
Nov 11, 2019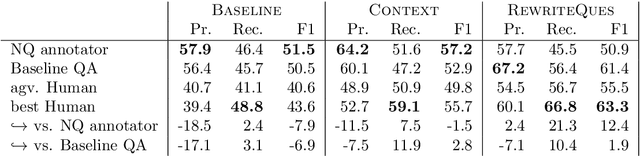
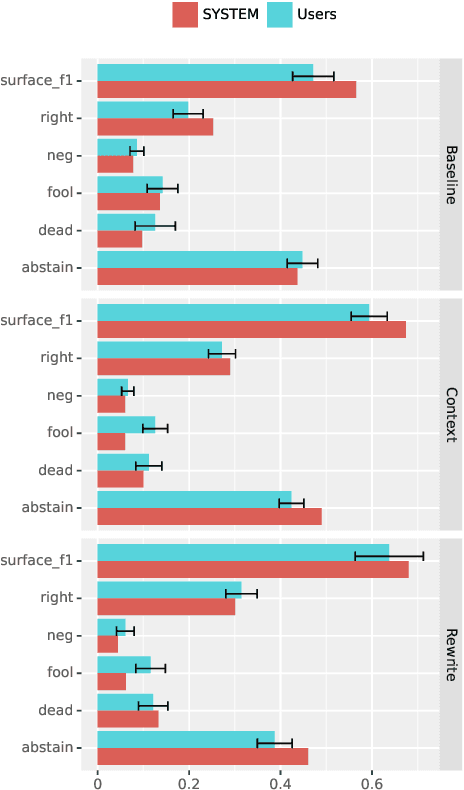

We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.