 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Susceptible are LLMs to Influence in Prompts?
Aug 17, 2024



Large Language Models (LLMs) are highly sensitive to prompts, including additional context provided therein. As LLMs grow in capability, understanding their prompt-sensitivity becomes increasingly crucial for ensuring reliable and robust performance, particularly since evaluating these models becomes more challenging. In this work, we investigate how current models (Llama, Mixtral, Falcon) respond when presented with additional input from another model, mimicking a scenario where a more capable model -- or a system with access to more external information -- provides supplementary information to the target model. Across a diverse spectrum of question-answering tasks, we study how an LLM's response to multiple-choice questions changes when the prompt includes a prediction and explanation from another model. Specifically, we explore the influence of the presence of an explanation, the stated authoritativeness of the source, and the stated confidence of the supplementary input. Our findings reveal that models are strongly influenced, and when explanations are provided they are swayed irrespective of the quality of the explanation. The models are more likely to be swayed if the input is presented as being authoritative or confident, but the effect is small in size. This study underscores the significant prompt-sensitivity of LLMs and highlights the potential risks of incorporating outputs from external sources without thorough scrutiny and further validation. As LLMs continue to advance, understanding and mitigating such sensitivities will be crucial for their reliable and trustworthy deployment.
On scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Assessing Large Language Models on Climate Information
Oct 04, 2023



Understanding how climate change affects us and learning about available solutions are key steps toward empowering individuals and communities to mitigate and adapt to it. As Large Language Models (LLMs) rise in popularity, it is necessary to assess their capability in this domain. In this study, we present a comprehensive evaluation framework, grounded in science communication principles, to analyze LLM responses to climate change topics. Our framework emphasizes both the presentational and epistemological adequacy of answers, offering a fine-grained analysis of LLM generations. Spanning 8 dimensions, our framework discerns up to 30 distinct issues in model outputs. The task is a real-world example of a growing number of challenging problems where AI can complement and lift human performance. We introduce a novel and practical protocol for scalable oversight that uses AI Assistance and relies on raters with relevant educational backgrounds. We evaluate several recent LLMs and conduct a comprehensive analysis of the results, shedding light on both the potential and the limitations of LLMs in the realm of climate communication.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022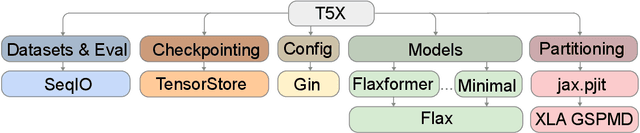
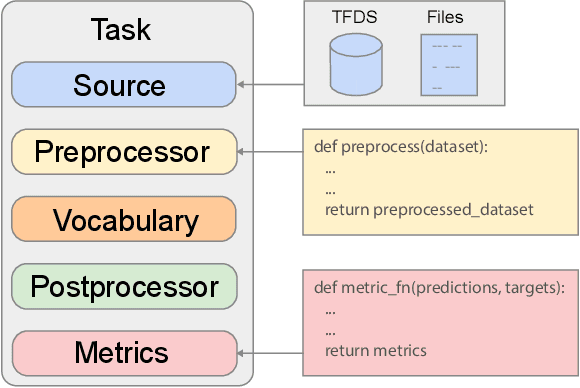
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Tomayto, Tomahto. Beyond Token-level Answer Equivalence for Question Answering Evaluation
Feb 15, 2022The predictions of question answering (QA) systems are typically evaluated against manually annotated finite sets of one or more answers. This leads to a coverage limitation that results in underestimating the true performance of systems, and is typically addressed by extending over exact match (EM) with predefined rules or with the token-level F1 measure. In this paper, we present the first systematic conceptual and data-driven analysis to examine the shortcomings of token-level equivalence measures. To this end, we define the asymmetric notion of answer equivalence (AE), accepting answers that are equivalent to or improve over the reference, and collect over 26K human judgements for candidates produced by multiple QA systems on SQuAD. Through a careful analysis of this data, we reveal and quantify several concrete limitations of the F1 measure, such as false impression of graduality, missing dependence on question, and more. Since collecting AE annotations for each evaluated model is expensive, we learn a BERT matching BEM measure to approximate this task. Being a simpler task than QA, we find BEM to provide significantly better AE approximations than F1, and more accurately reflect the performance of systems. Finally, we also demonstrate the practical utility of AE and BEM on the concrete application of minimal accurate prediction sets, reducing the number of required answers by up to 2.6 times.
Fool Me Twice: Entailment from Wikipedia Gamification
Apr 10, 2021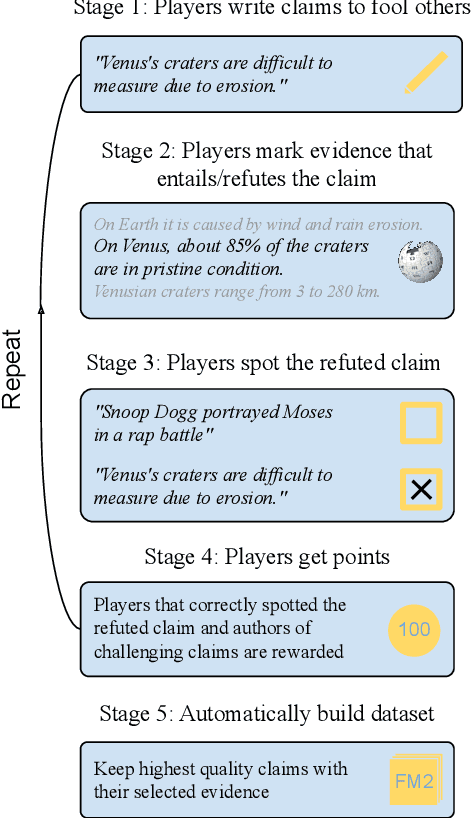
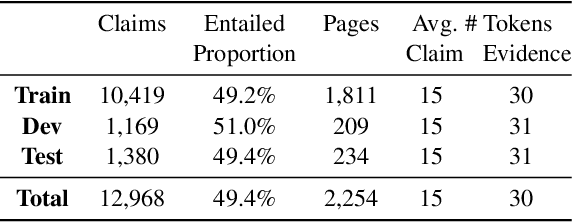

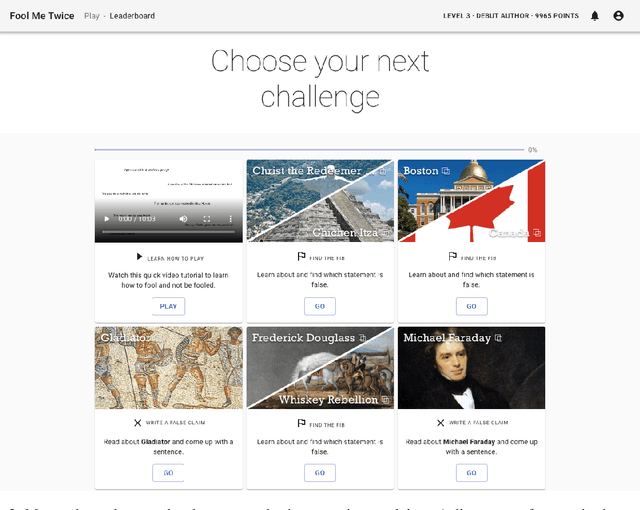
We release FoolMeTwice (FM2 for short), a large dataset of challenging entailment pairs collected through a fun multi-player game. Gamification encourages adversarial examples, drastically lowering the number of examples that can be solved using "shortcuts" compared to other popular entailment datasets. Players are presented with two tasks. The first task asks the player to write a plausible claim based on the evidence from a Wikipedia page. The second one shows two plausible claims written by other players, one of which is false, and the goal is to identify it before the time runs out. Players "pay" to see clues retrieved from the evidence pool: the more evidence the player needs, the harder the claim. Game-play between motivated players leads to diverse strategies for crafting claims, such as temporal inference and diverting to unrelated evidence, and results in higher quality data for the entailment and evidence retrieval tasks. We open source the dataset and the game code.
CLIMATE-FEVER: A Dataset for Verification of Real-World Climate Claims
Jan 02, 2021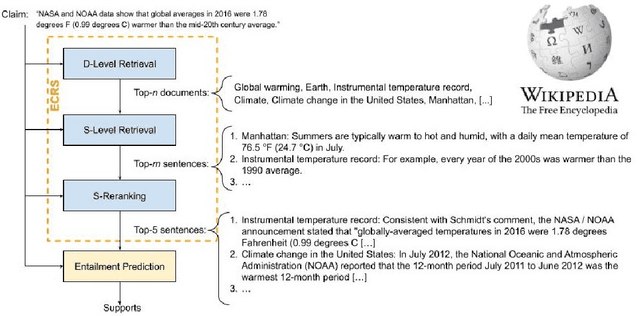
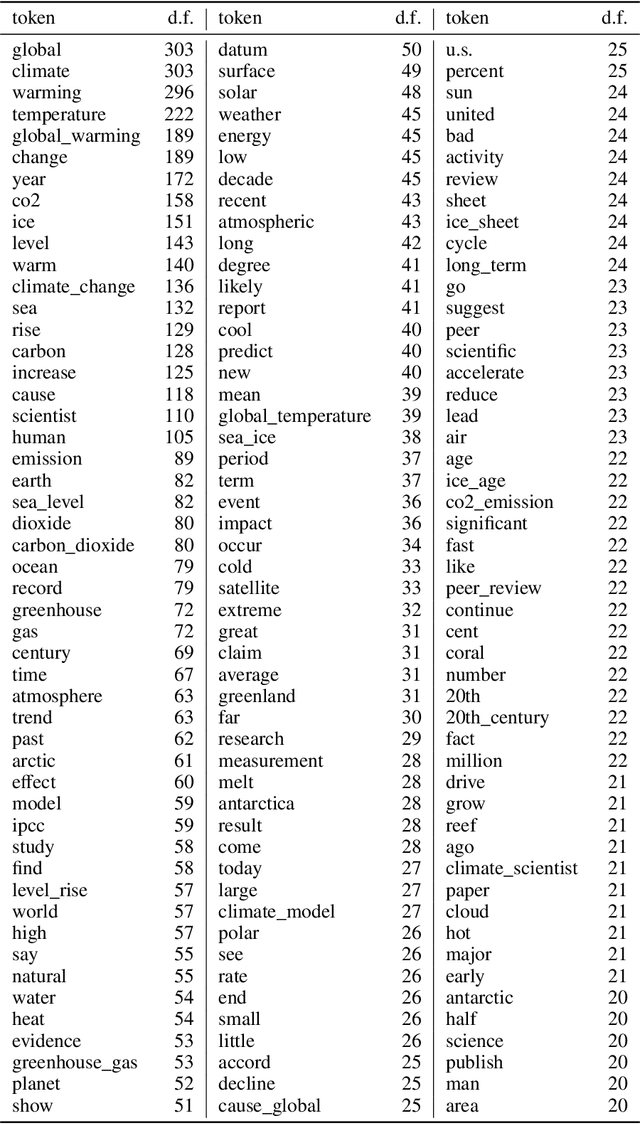
We introduce CLIMATE-FEVER, a new publicly available dataset for verification of climate change-related claims. By providing a dataset for the research community, we aim to facilitate and encourage work on improving algorithms for retrieving evidential support for climate-specific claims, addressing the underlying language understanding challenges, and ultimately help alleviate the impact of misinformation on climate change. We adapt the methodology of FEVER [1], the largest dataset of artificially designed claims, to real-life claims collected from the Internet. While during this process, we could rely on the expertise of renowned climate scientists, it turned out to be no easy task. We discuss the surprising, subtle complexity of modeling real-world climate-related claims within the \textsc{fever} framework, which we believe provides a valuable challenge for general natural language understanding. We hope that our work will mark the beginning of a new exciting long-term joint effort by the climate science and AI community.
Meta Answering for Machine Reading
Nov 11, 2019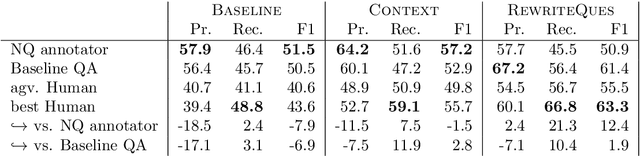
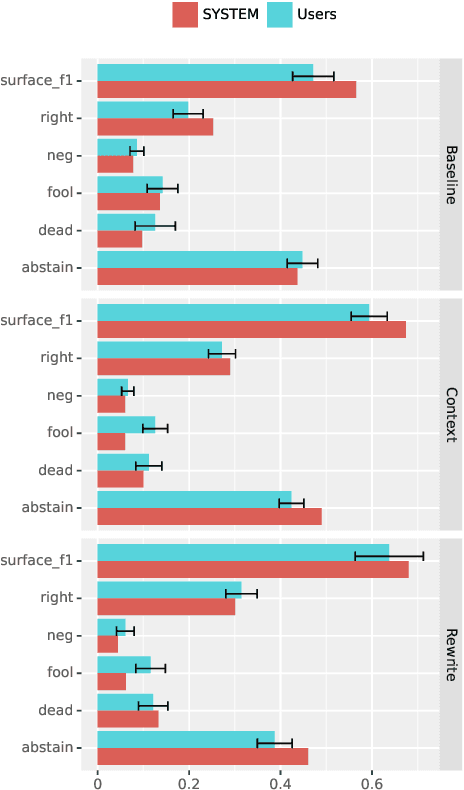

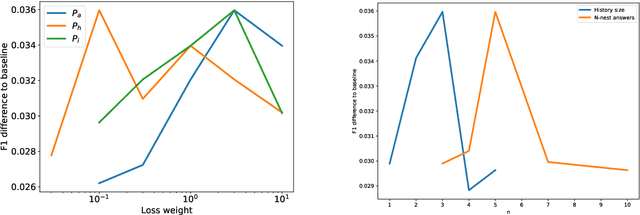
We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.
Learning to Coordinate Multiple Reinforcement Learning Agents for Diverse Query Reformulation
Sep 27, 2018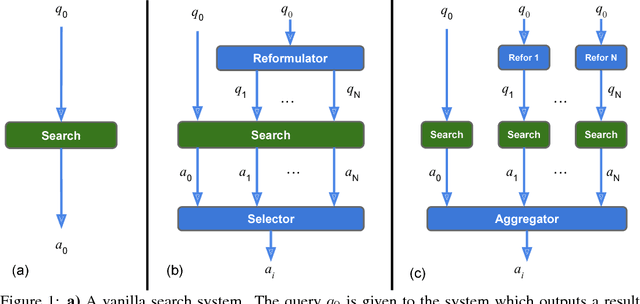
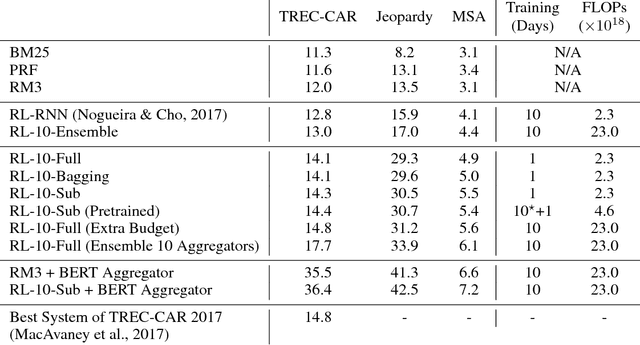
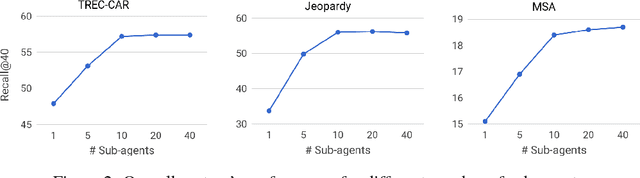
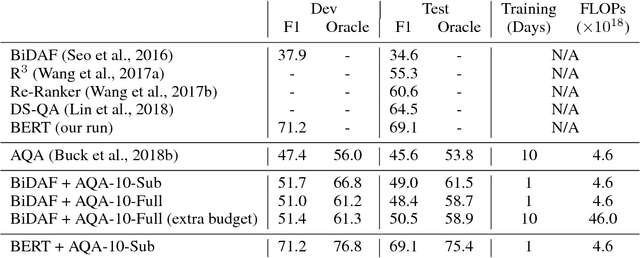
We propose a method to efficiently learn diverse strategies in reinforcement learning for query reformulation in the tasks of document retrieval and question answering. In the proposed framework an agent consists of multiple specialized sub-agents and a meta-agent that learns to aggregate the answers from sub-agents to produce a final answer. Sub-agents are trained on disjoint partitions of the training data, while the meta-agent is trained on the full training set. Our method makes learning faster, because it is highly parallelizable, and has better generalization performance than strong baselines, such as an ensemble of agents trained on the full data. We show that the improved performance is due to the increased diversity of reformulation strategies.
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
Mar 02, 2018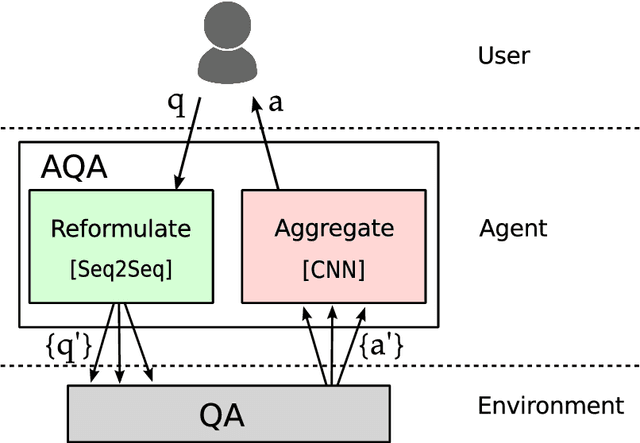
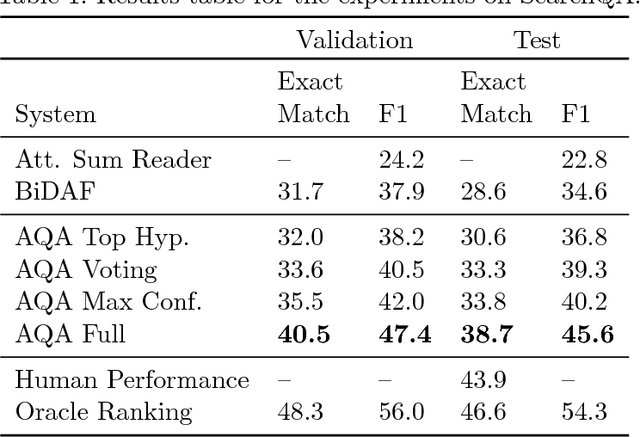
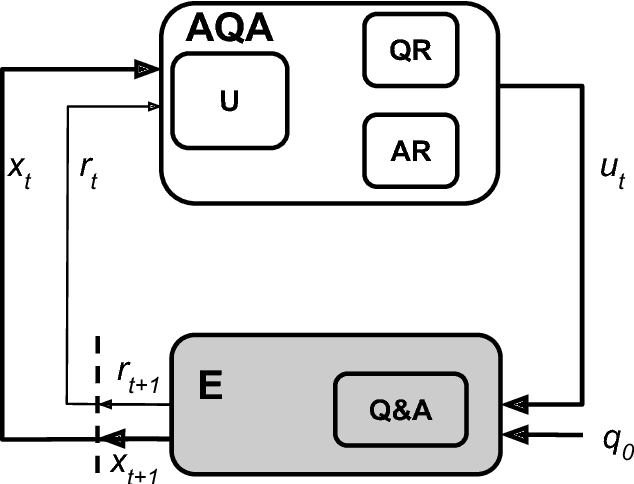
We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering. We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer. The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks. We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.