 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAssistant Conversations -- Democratizing Large Language Model Alignment
Apr 14, 2023



Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages distributed across 66,497 conversation trees, in 35 different languages, annotated with 461,292 quality ratings. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. To demonstrate the OpenAssistant Conversations dataset's effectiveness, we present OpenAssistant, the first fully open-source large-scale instruction-tuned model to be trained on human data. A preference study revealed that OpenAssistant replies are comparably preferred to GPT-3.5-turbo (ChatGPT) with a relative winrate of 48.3% vs. 51.7% respectively. We release our code and data under fully permissive licenses.
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Feb 01, 2022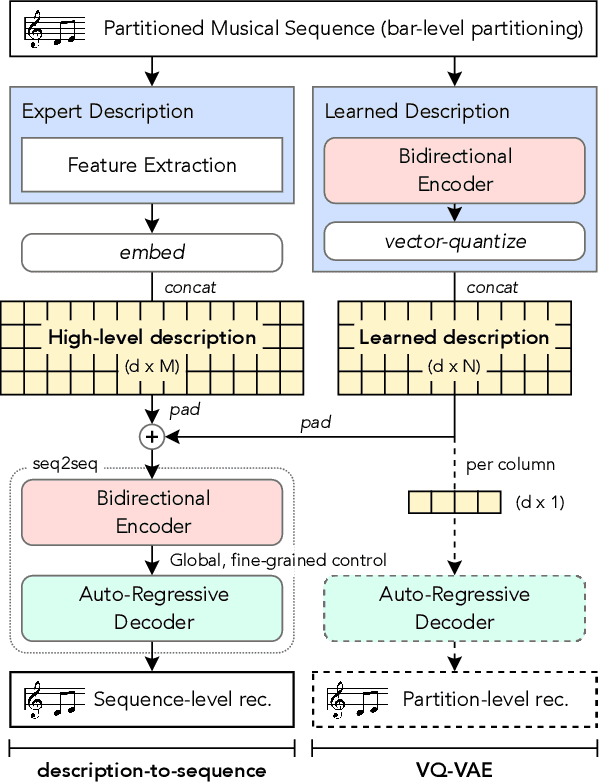

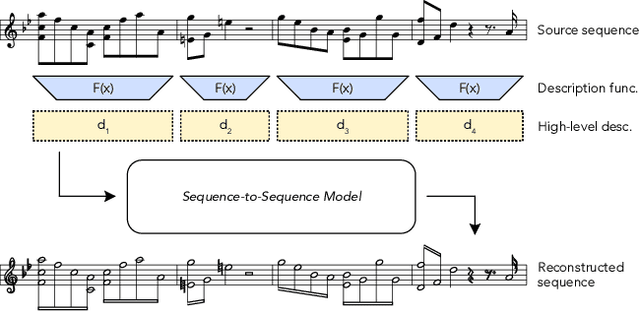
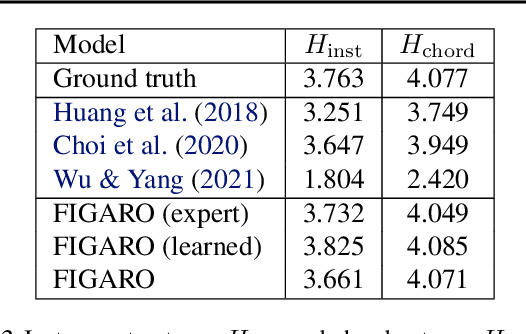
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised description-to-sequence task, which allows for fine-grained controllable generation on a global level. We do so by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.
Boosting Search Engines with Interactive Agents
Sep 01, 2021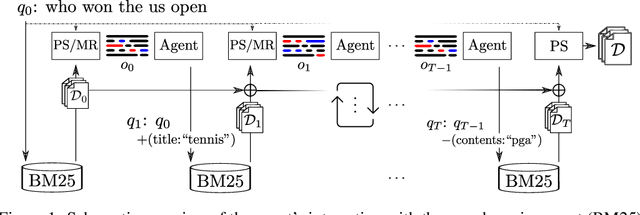
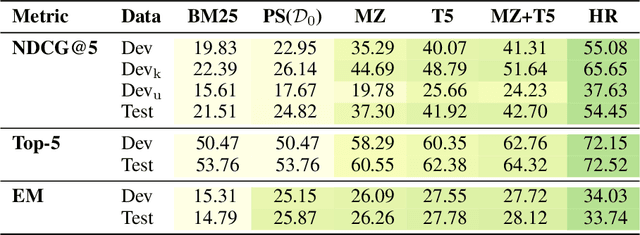
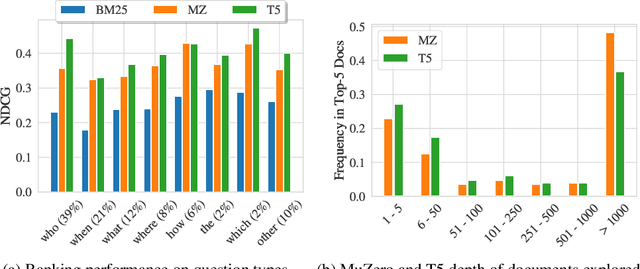

Can machines learn to use a search engine as an interactive tool for finding information? That would have far reaching consequences for making the world's knowledge more accessible. This paper presents first steps in designing agents that learn meta-strategies for contextual query refinements. Our approach uses machine reading to guide the selection of refinement terms from aggregated search results. Agents are then empowered with simple but effective search operators to exert fine-grained and transparent control over queries and search results. We develop a novel way of generating synthetic search sessions, which leverages the power of transformer-based generative language models through (self-)supervised learning. We also present a reinforcement learning agent with dynamically constrained actions that can learn interactive search strategies completely from scratch. In both cases, we obtain significant improvements over one-shot search with a strong information retrieval baseline. Finally, we provide an in-depth analysis of the learned search policies.
Generative Minimization Networks: Training GANs Without Competition
Mar 23, 2021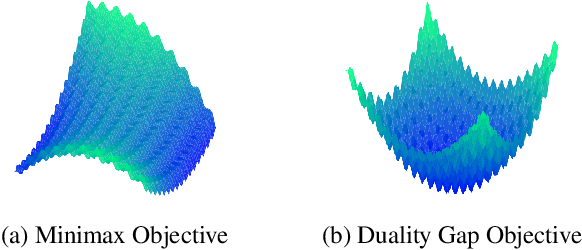
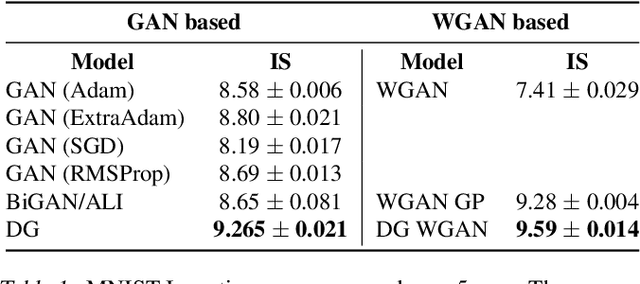
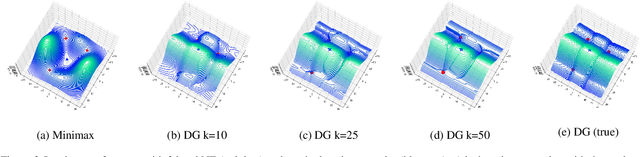
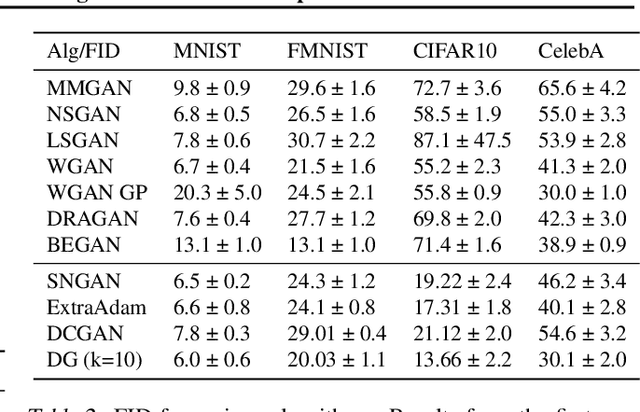
Many applications in machine learning can be framed as minimization problems and solved efficiently using gradient-based techniques. However, recent applications of generative models, particularly GANs, have triggered interest in solving min-max games for which standard optimization techniques are often not suitable. Among known problems experienced by practitioners is the lack of convergence guarantees or convergence to a non-optimum cycle. At the heart of these problems is the min-max structure of the GAN objective which creates non-trivial dependencies between the players. We propose to address this problem by optimizing a different objective that circumvents the min-max structure using the notion of duality gap from game theory. We provide novel convergence guarantees on this objective and demonstrate why the obtained limit point solves the problem better than known techniques.
Meta Answering for Machine Reading
Nov 11, 2019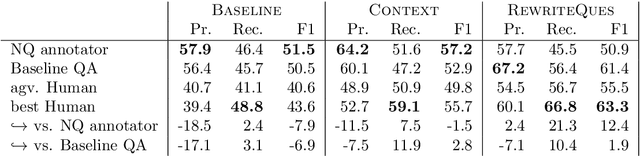
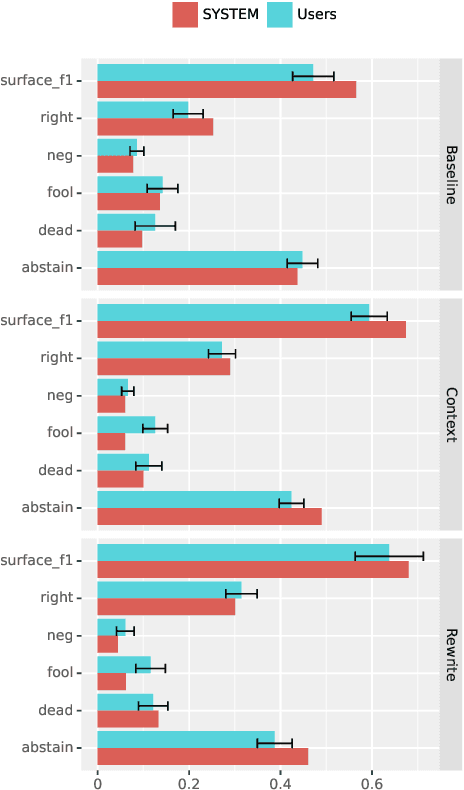

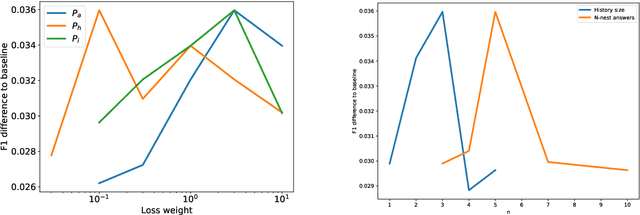
We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.
Adversarial Training Generalizes Data-dependent Spectral Norm Regularization
Jun 17, 2019
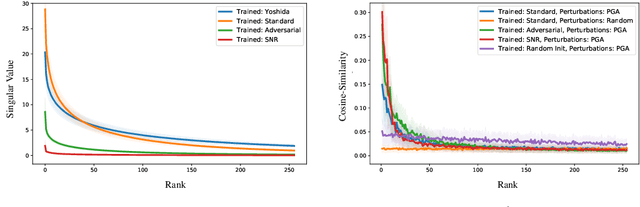
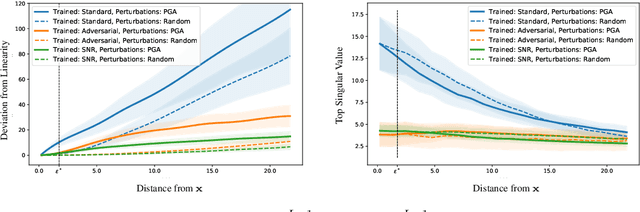
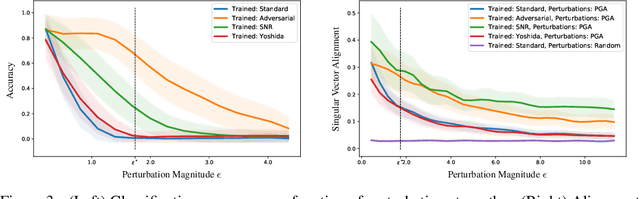
We establish a theoretical link between adversarial training and operator norm regularization for deep neural networks. Specifically, we show that adversarial training is a data-dependent generalization of spectral norm regularization. This intriguing connection provides fundamental insights into the origin of adversarial vulnerability and hints at novel ways to robustify and defend against adversarial attacks. We provide extensive empirical evidence to support our theoretical results.
The Odds are Odd: A Statistical Test for Detecting Adversarial Examples
Feb 13, 2019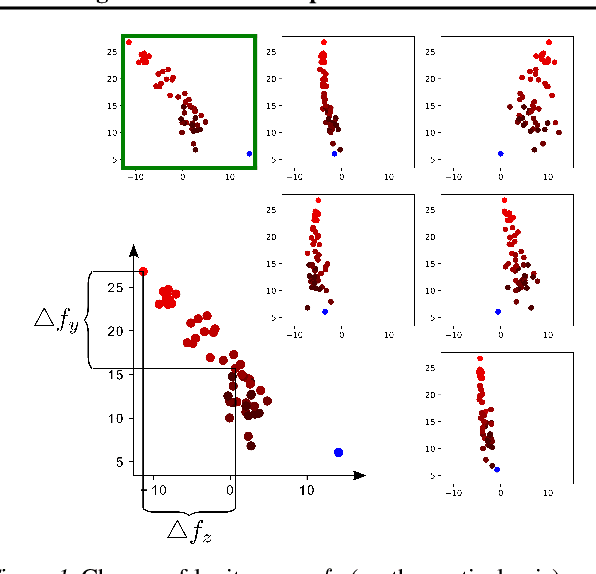
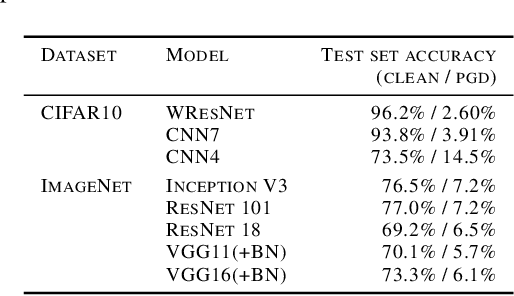

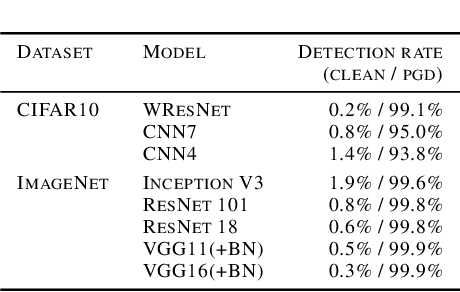
We investigate conditions under which test statistics exist that can reliably detect examples, which have been adversarially manipulated in a white-box attack. These statistics can be easily computed and calibrated by randomly corrupting inputs. They exploit certain anomalies that adversarial attacks introduce, in particular if they follow the paradigm of choosing perturbations optimally under p-norm constraints. Access to the log-odds is the only requirement to defend models. We justify our approach empirically, but also provide conditions under which detectability via the suggested test statistics is guaranteed to be effective. In our experiments, we show that it is even possible to correct test time predictions for adversarial attacks with high accuracy.
Semantic Interpolation in Implicit Models
Feb 02, 2018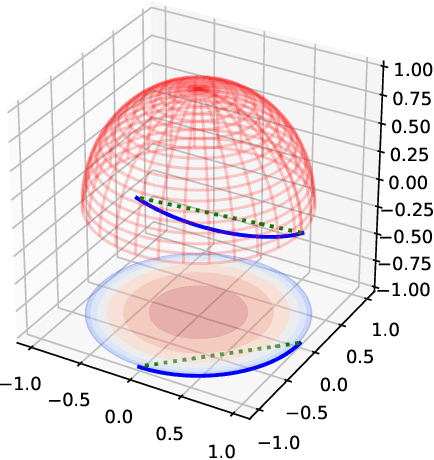
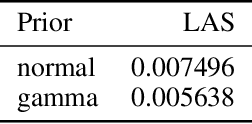

In implicit models, one often interpolates between sampled points in latent space. As we show in this paper, care needs to be taken to match-up the distributional assumptions on code vectors with the geometry of the interpolating paths. Otherwise, typical assumptions about the quality and semantics of in-between points may not be justified. Based on our analysis we propose to modify the prior code distribution to put significantly more probability mass closer to the origin. As a result, linear interpolation paths are not only shortest paths, but they are also guaranteed to pass through high-density regions, irrespective of the dimensionality of the latent space. Experiments on standard benchmark image datasets demonstrate clear visual improvements in the quality of the generated samples and exhibit more meaningful interpolation paths.
Flexible Prior Distributions for Deep Generative Models
Jan 07, 2018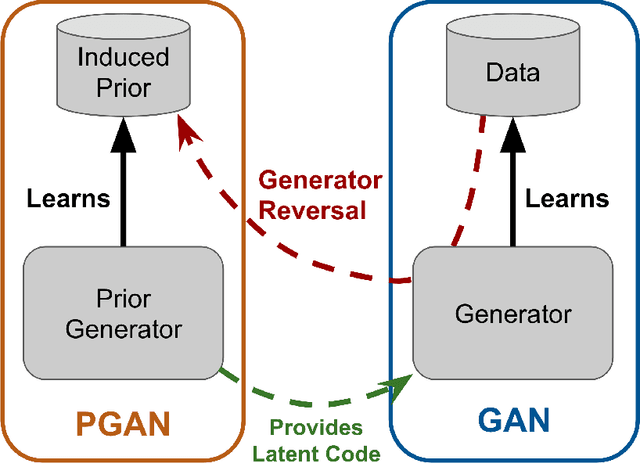



We consider the problem of training generative models with deep neural networks as generators, i.e. to map latent codes to data points. Whereas the dominant paradigm combines simple priors over codes with complex deterministic models, we argue that it might be advantageous to use more flexible code distributions. We demonstrate how these distributions can be induced directly from the data. The benefits include: more powerful generative models, better modeling of latent structure and explicit control of the degree of generalization.
The best defense is a good offense: Countering black box attacks by predicting slightly wrong labels
Nov 15, 2017
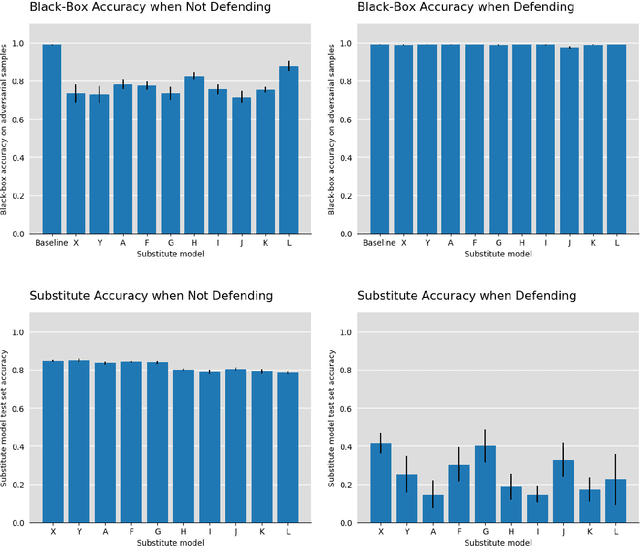

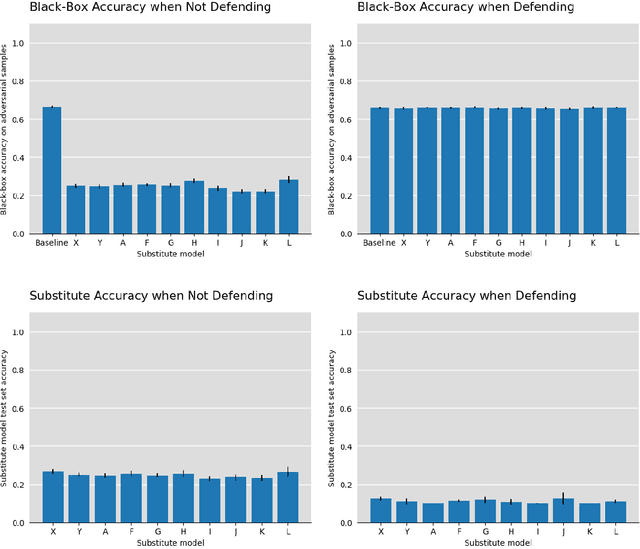
Black-Box attacks on machine learning models occur when an attacker, despite having no access to the inner workings of a model, can successfully craft an attack by means of model theft. The attacker will train an own substitute model that mimics the model to be attacked. The substitute can then be used to design attacks against the original model, for example by means of adversarial samples. We put ourselves in the shoes of the defender and present a method that can successfully avoid model theft by mounting a counter-attack. Specifically, to any incoming query, we slightly perturb our output label distribution in a way that makes substitute training infeasible. We demonstrate that the perturbation does not affect the ordinary use of our model, but results in an effective defense against attacks based on model theft.