 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019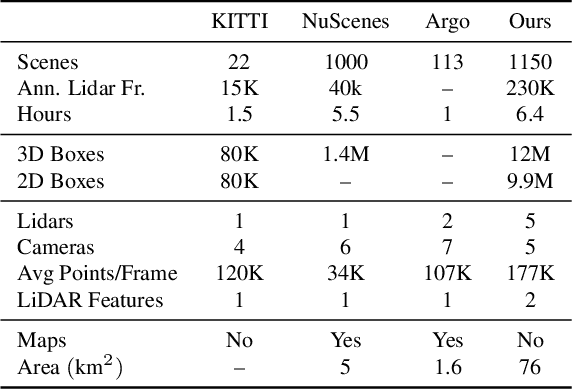
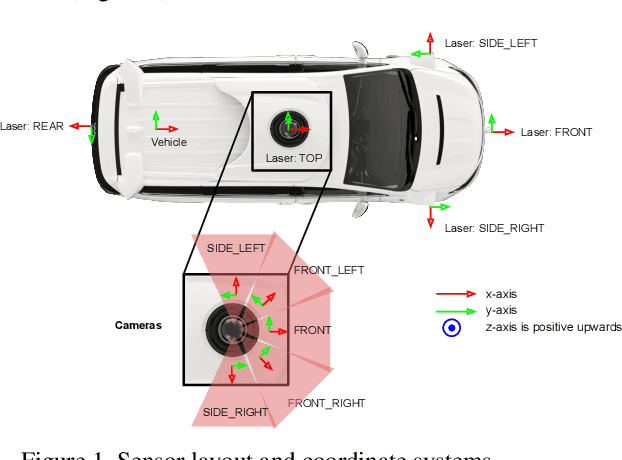

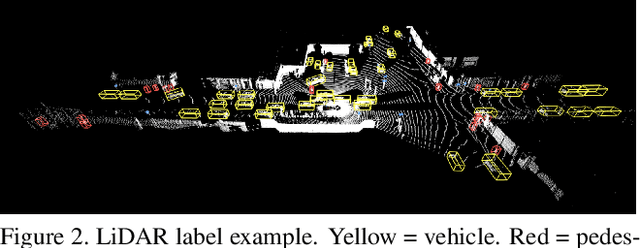
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
RandAugment: Practical automated data augmentation with a reduced search space
Nov 14, 2019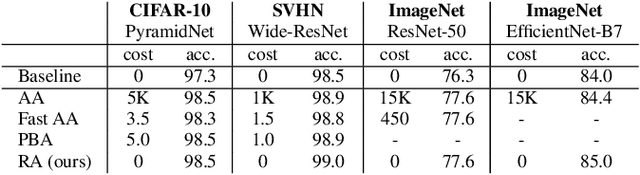


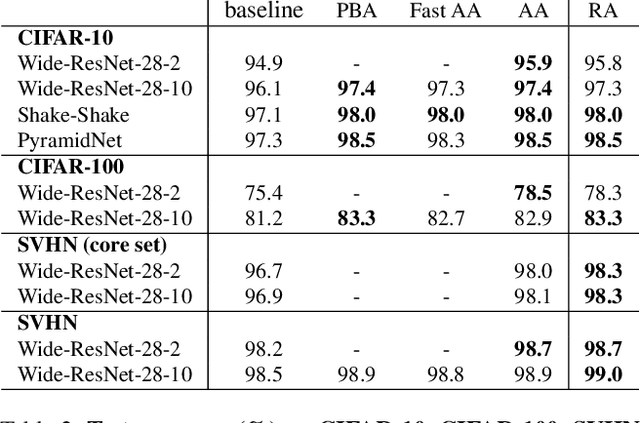
Recent work has shown that data augmentation has the potential to significantly improve the generalization of deep learning models. Recently, automated augmentation strategies have led to state-of-the-art results in image classification and object detection. While these strategies were optimized for improving validation accuracy, they also led to state-of-the-art results in semi-supervised learning and improved robustness to common corruptions of images. An obstacle to a large-scale adoption of these methods is a separate search phase which increases the training complexity and may substantially increase the computational cost. Additionally, due to the separate search phase, these approaches are unable to adjust the regularization strength based on model or dataset size. Automated augmentation policies are often found by training small models on small datasets and subsequently applied to train larger models. In this work, we remove both of these obstacles. RandAugment has a significantly reduced search space which allows it to be trained on the target task with no need for a separate proxy task. Furthermore, due to the parameterization, the regularization strength may be tailored to different model and dataset sizes. RandAugment can be used uniformly across different tasks and datasets and works out of the box, matching or surpassing all previous automated augmentation approaches on CIFAR-10/100, SVHN, and ImageNet. On the ImageNet dataset we achieve 85.0% accuracy, a 0.6% increase over the previous state-of-the-art and 1.0% increase over baseline augmentation. On object detection, RandAugment leads to 1.0-1.3% improvement over baseline augmentation, and is within 0.3% mAP of AutoAugment on COCO. Finally, due to its interpretable hyperparameter, RandAugment may be used to investigate the role of data augmentation with varying model and dataset size. Code is available online.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019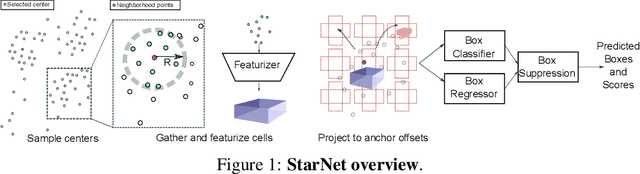
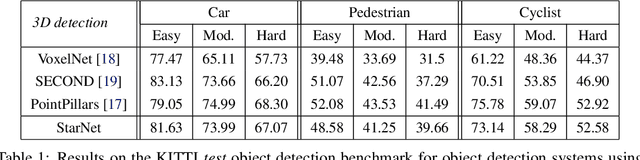
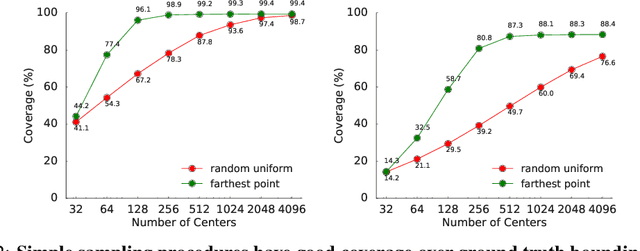
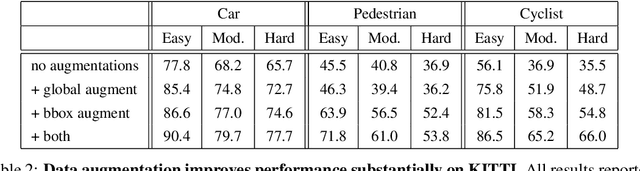
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
Learning Data Augmentation Strategies for Object Detection
Jun 26, 2019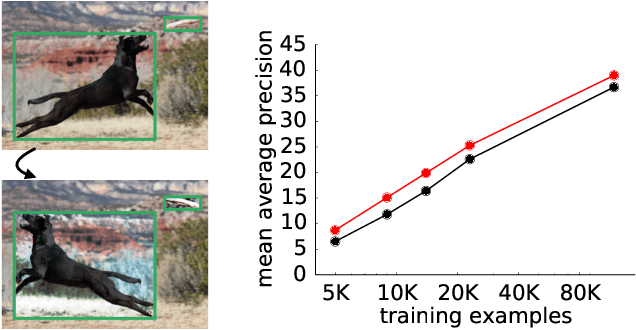
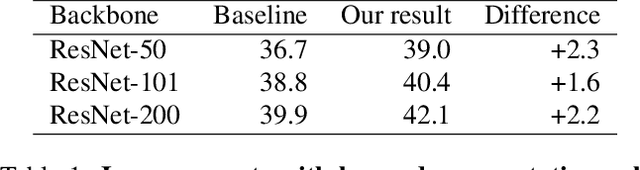


Data augmentation is a critical component of training deep learning models. Although data augmentation has been shown to significantly improve image classification, its potential has not been thoroughly investigated for object detection. Given the additional cost for annotating images for object detection, data augmentation may be of even greater importance for this computer vision task. In this work, we study the impact of data augmentation on object detection. We first demonstrate that data augmentation operations borrowed from image classification may be helpful for training detection models, but the improvement is limited. Thus, we investigate how learned, specialized data augmentation policies improve generalization performance for detection models. Importantly, these augmentation policies only affect training and leave a trained model unchanged during evaluation. Experiments on the COCO dataset indicate that an optimized data augmentation policy improves detection accuracy by more than +2.3 mAP, and allow a single inference model to achieve a state-of-the-art accuracy of 50.7 mAP. Importantly, the best policy found on COCO may be transferred unchanged to other detection datasets and models to improve predictive accuracy. For example, the best augmentation policy identified with COCO improves a strong baseline on PASCAL-VOC by +2.7 mAP. Our results also reveal that a learned augmentation policy is superior to state-of-the-art architecture regularization methods for object detection, even when considering strong baselines. Code for training with the learned policy is available online at https://github.com/tensorflow/tpu/tree/master/models/official/detection
A Fourier Perspective on Model Robustness in Computer Vision
Jun 21, 2019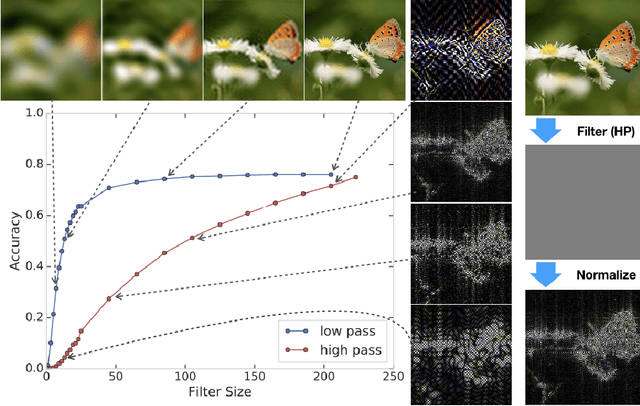

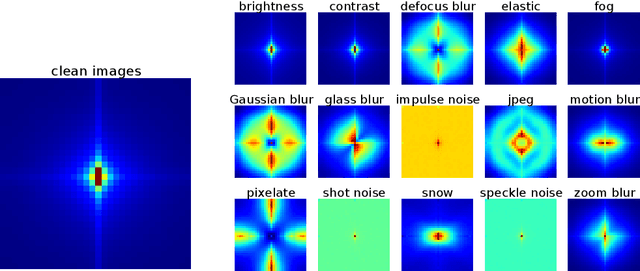
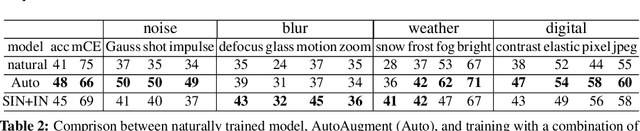
Achieving robustness to distributional shift is a longstanding and challenging goal of computer vision. Data augmentation is a commonly used approach for improving robustness, however robustness gains are typically not uniform across corruption types. Indeed increasing performance in the presence of random noise is often met with reduced performance on other corruptions such as contrast change. Understanding when and why these sorts of trade-offs occur is a crucial step towards mitigating them. Towards this end, we investigate recently observed trade-offs caused by Gaussian data augmentation and adversarial training. We find that both methods improve robustness to corruptions that are concentrated in the high frequency domain while reducing robustness to corruptions that are concentrated in the low frequency domain. This suggests that one way to mitigate these trade-offs via data augmentation is to use a more diverse set of augmentations. Towards this end we observe that AutoAugment, a recently proposed data augmentation policy optimized for clean accuracy, achieves state-of-the-art robustness on the CIFAR-10-C and ImageNet-C benchmarks.
Stand-Alone Self-Attention in Vision Models
Jun 13, 2019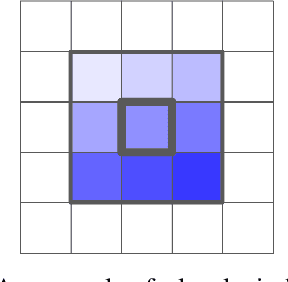
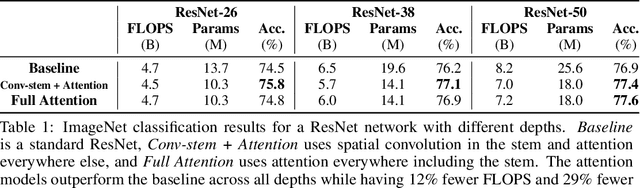
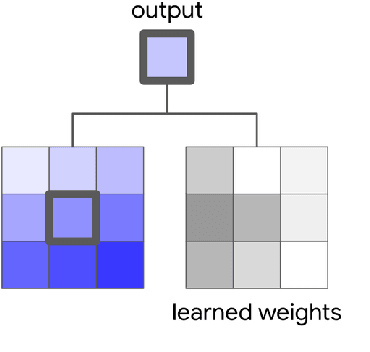
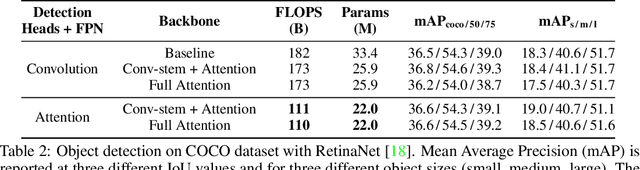
Convolutions are a fundamental building block of modern computer vision systems. Recent approaches have argued for going beyond convolutions in order to capture long-range dependencies. These efforts focus on augmenting convolutional models with content-based interactions, such as self-attention and non-local means, to achieve gains on a number of vision tasks. The natural question that arises is whether attention can be a stand-alone primitive for vision models instead of serving as just an augmentation on top of convolutions. In developing and testing a pure self-attention vision model, we verify that self-attention can indeed be an effective stand-alone layer. A simple procedure of replacing all instances of spatial convolutions with a form of self-attention applied to ResNet model produces a fully self-attentional model that outperforms the baseline on ImageNet classification with 12% fewer FLOPS and 29% fewer parameters. On COCO object detection, a pure self-attention model matches the mAP of a baseline RetinaNet while having 39% fewer FLOPS and 34% fewer parameters. Detailed ablation studies demonstrate that self-attention is especially impactful when used in later layers. These results establish that stand-alone self-attention is an important addition to the vision practitioner's toolbox.
Visual Wake Words Dataset
Jun 12, 2019

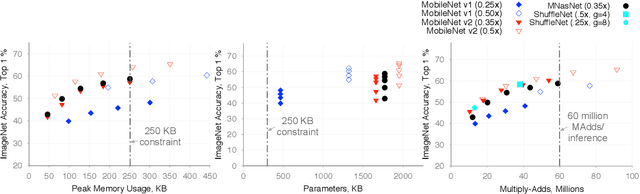
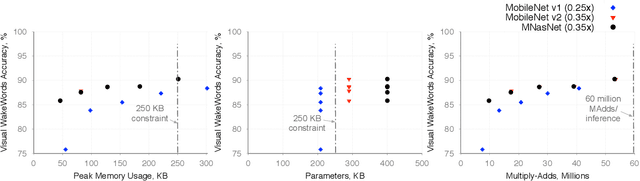
The emergence of Internet of Things (IoT) applications requires intelligence on the edge. Microcontrollers provide a low-cost compute platform to deploy intelligent IoT applications using machine learning at scale, but have extremely limited on-chip memory and compute capability. To deploy computer vision on such devices, we need tiny vision models that fit within a few hundred kilobytes of memory footprint in terms of peak usage and model size on device storage. To facilitate the development of microcontroller friendly models, we present a new dataset, Visual Wake Words, that represents a common microcontroller vision use-case of identifying whether a person is present in the image or not, and provides a realistic benchmark for tiny vision models. Within a limited memory footprint of 250 KB, several state-of-the-art mobile models achieve accuracy of 85-90% on the Visual Wake Words dataset. We anticipate the proposed dataset will advance the research on tiny vision models that can push the pareto-optimal boundary in terms of accuracy versus memory usage for microcontroller applications.
Using learned optimizers to make models robust to input noise
Jun 08, 2019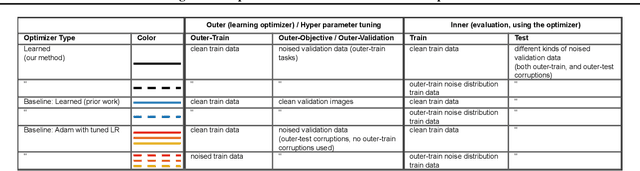
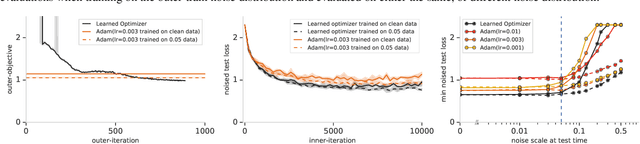
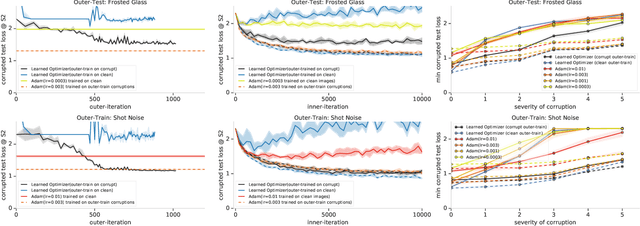
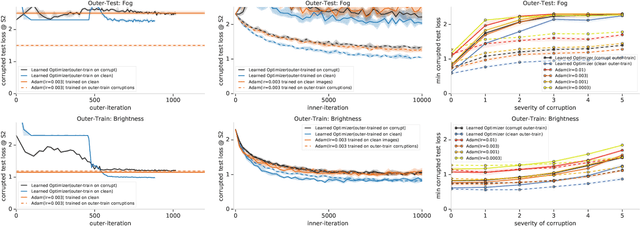
State-of-the art vision models can achieve superhuman performance on image classification tasks when testing and training data come from the same distribution. However, when models are tested on corrupted images (e.g. due to scale changes, translations, or shifts in brightness or contrast), performance degrades significantly. Here, we explore the possibility of meta-training a learned optimizer that can train image classification models such that they are robust to common image corruptions. Specifically, we are interested training models that are more robust to noise distributions not present in the training data. We find that a learned optimizer meta-trained to produce models which are robust to Gaussian noise trains models that are more robust to Gaussian noise at other scales compared to traditional optimizers like Adam. The effect of meta-training is more complicated when targeting a more general set of noise distributions, but led to improved performance on half of held-out corruption tasks. Our results suggest that meta-learning provides a novel approach for studying and improving the robustness of deep learning models.
Using Videos to Evaluate Image Model Robustness
Apr 24, 2019
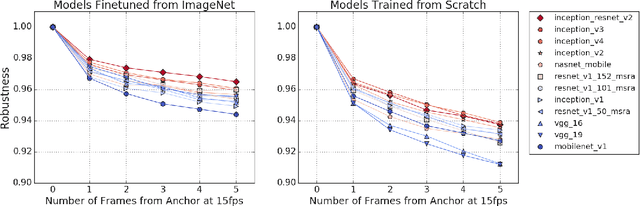
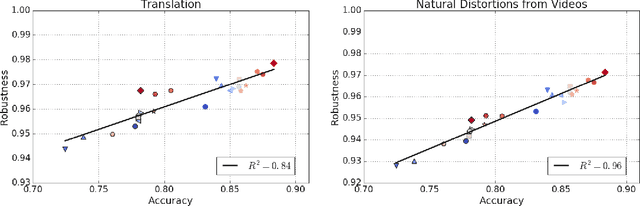
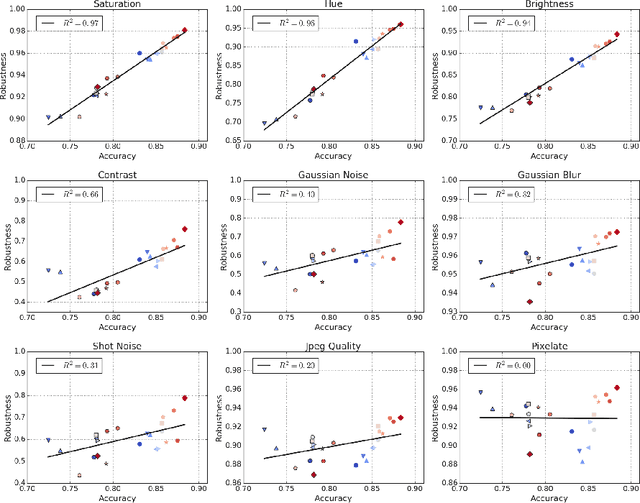
Human visual systems are robust to a wide range of image transformations that are challenging for artificial networks. We present the first study of image model robustness to the minute transformations found across video frames, which we term "natural robustness". Compared to previous studies on adversarial examples and synthetic distortions, natural robustness captures a more diverse set of common image transformations that occur in the natural environment. Our study across a dozen model architectures shows that more accurate models are more robust to natural transformations, and that robustness to synthetic color distortions is a good proxy for natural robustness. In examining brittleness in videos, we find that majority of the brittleness found in videos lies outside the typical definition of adversarial examples (99.9\%). Finally, we investigate training techniques to reduce brittleness and find that no single technique systematically improves natural robustness across twelve tested architectures.
Attention Augmented Convolutional Networks
Apr 22, 2019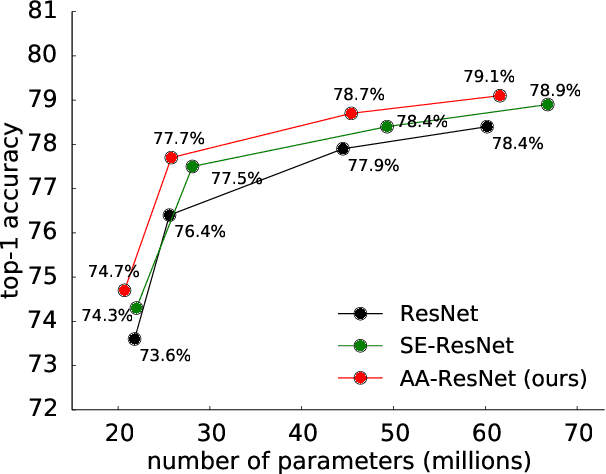
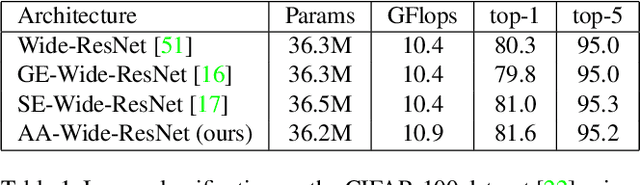
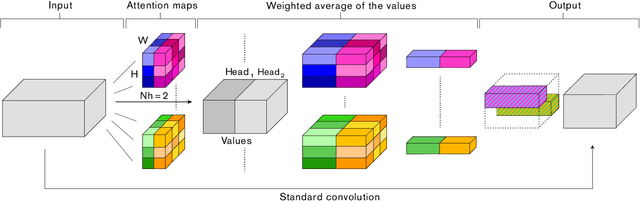
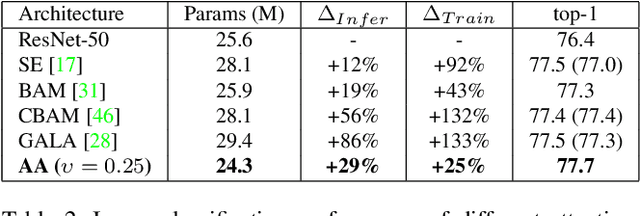
Convolutional networks have been the paradigm of choice in many computer vision applications. The convolution operation however has a significant weakness in that it only operates on a local neighborhood, thus missing global information. Self-attention, on the other hand, has emerged as a recent advance to capture long range interactions, but has mostly been applied to sequence modeling and generative modeling tasks. In this paper, we consider the use of self-attention for discriminative visual tasks as an alternative to convolutions. We introduce a novel two-dimensional relative self-attention mechanism that proves competitive in replacing convolutions as a stand-alone computational primitive for image classification. We find in control experiments that the best results are obtained when combining both convolutions and self-attention. We therefore propose to augment convolutional operators with this self-attention mechanism by concatenating convolutional feature maps with a set of feature maps produced via self-attention. Extensive experiments show that Attention Augmentation leads to consistent improvements in image classification on ImageNet and object detection on COCO across many different models and scales, including ResNets and a state-of-the art mobile constrained network, while keeping the number of parameters similar. In particular, our method achieves a $1.3\%$ top-1 accuracy improvement on ImageNet classification over a ResNet50 baseline and outperforms other attention mechanisms for images such as Squeeze-and-Excitation. It also achieves an improvement of 1.4 mAP in COCO Object Detection on top of a RetinaNet baseline.