 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Slip with Barometric Tactile Sensors and a Temporal Convolutional Neural Network
Feb 19, 2022



The ability to perceive object slip via tactile feedback enables humans to accomplish complex manipulation tasks including maintaining a stable grasp. Despite the utility of tactile information for many applications, tactile sensors have yet to be widely deployed in industrial robotics settings; part of the challenge lies in identifying slip and other events from the tactile data stream. In this paper, we present a learning-based method to detect slip using barometric tactile sensors. These sensors have many desirable properties including high durability and reliability, and are built from inexpensive, off-the-shelf components. We train a temporal convolution neural network to detect slip, achieving high detection accuracies while displaying robustness to the speed and direction of the slip motion. Further, we test our detector on two manipulation tasks involving a variety of common objects and demonstrate successful generalization to real-world scenarios not seen during training. We argue that barometric tactile sensing technology, combined with data-driven learning, is suitable for many manipulation tasks such as slip compensation.
Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Dec 16, 2021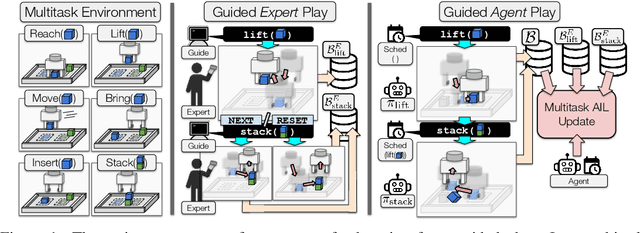
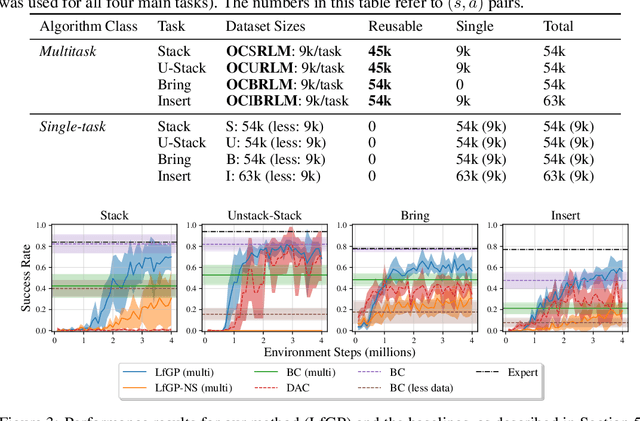

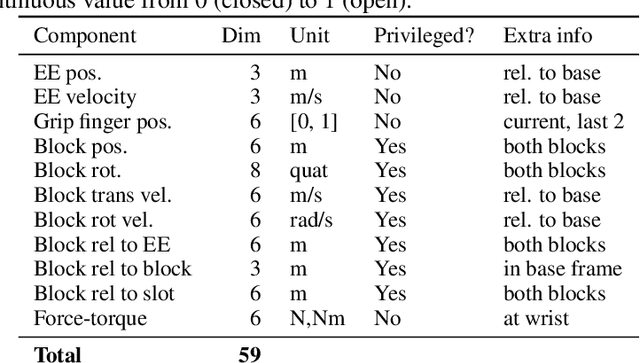
Effective exploration continues to be a significant challenge that prevents the deployment of reinforcement learning for many physical systems. This is particularly true for systems with continuous and high-dimensional state and action spaces, such as robotic manipulators. The challenge is accentuated in the sparse rewards setting, where the low-level state information required for the design of dense rewards is unavailable. Adversarial imitation learning (AIL) can partially overcome this barrier by leveraging expert-generated demonstrations of optimal behaviour and providing, essentially, a replacement for dense reward information. Unfortunately, the availability of expert demonstrations does not necessarily improve an agent's capability to explore effectively and, as we empirically show, can lead to inefficient or stagnated learning. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of, in addition to a main task, multiple auxiliary tasks. Subsequently, a hierarchical model is used to learn each task reward and policy through a modified AIL procedure, in which exploration of all tasks is enforced via a scheduler composing different tasks together. This affords many benefits: learning efficiency is improved for main tasks with challenging bottleneck transitions, expert data becomes reusable between tasks, and transfer learning through the reuse of learned auxiliary task models becomes possible. Our experimental results in a challenging multitask robotic manipulation domain indicate that our method compares favourably to supervised imitation learning and to a state-of-the-art AIL method. Code is available at https://github.com/utiasSTARS/lfgp.
Observability-Aware Trajectory Optimization: Theory, Viability, and State of the Art
Sep 18, 2021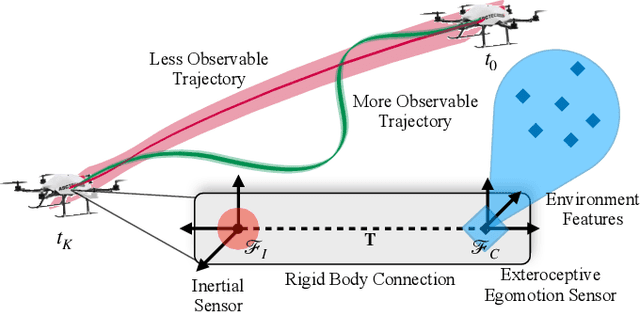

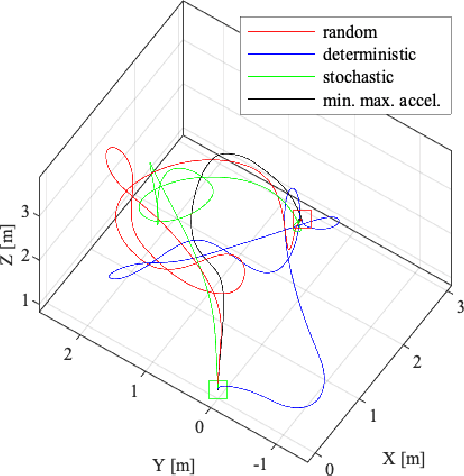
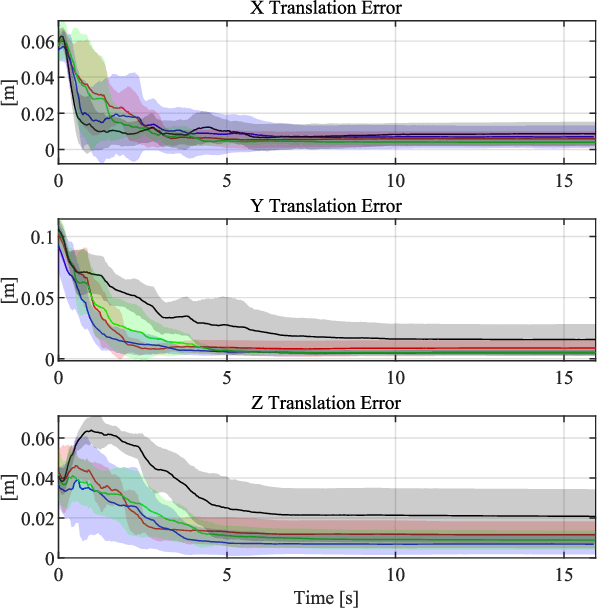
Ideally, robots should move in ways that maximize the knowledge gained about the state of both their internal system and the external operating environment. Trajectory design is a challenging problem that has been investigated from a variety of perspectives, ranging from information-theoretic analyses to leaning-based approaches. Recently, observability-based metrics have been proposed to find trajectories that enable rapid and accurate state and parameter estimation. The viability and efficacy of these methods is not yet well understood in the literature. In this paper, we compare two state-of-the-art methods for observability-aware trajectory optimization and seek to add important theoretical clarifications and valuable discussion about their overall effectiveness. For evaluation, we examine the representative task of sensor-to-sensor extrinsic self-calibration using a realistic physics simulator. We also study the sensitivity of these algorithms to changes in the information content of the exteroceptive sensor measurements.
Convex Iteration for Distance-Geometric Inverse Kinematics
Sep 08, 2021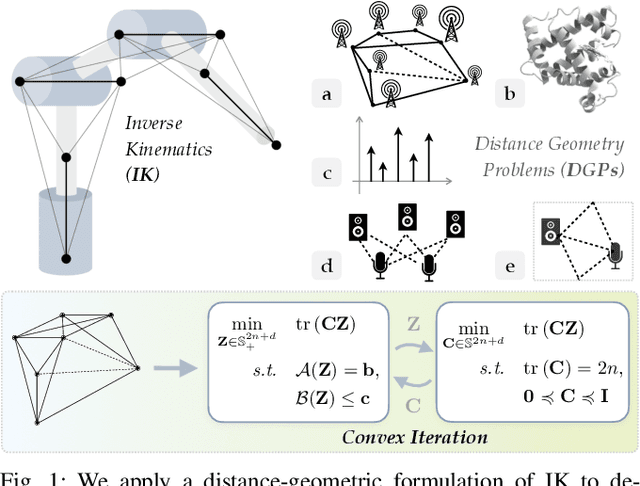
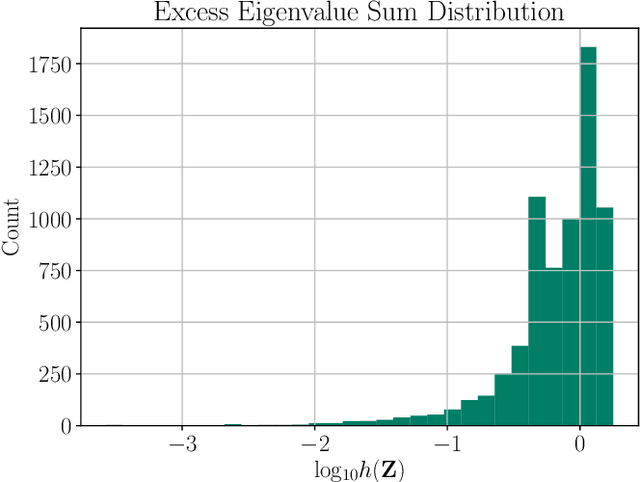
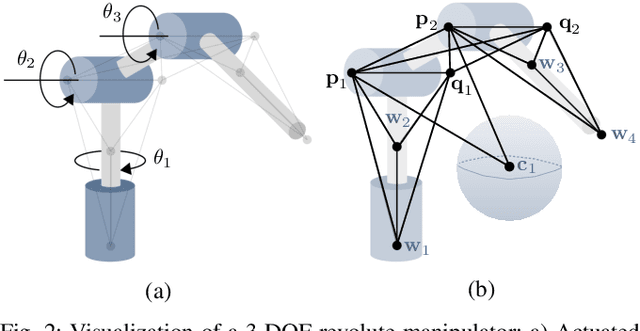
Inverse kinematics (IK) is the problem of finding robot joint configurations that satisfy constraints on the position or pose of one or more end-effectors. For robots with redundant degrees of freedom, there is often an infinite, nonconvex set of solutions. The IK problem is further complicated when collision avoidance constraints are imposed by obstacles in the workspace. In general, closed-form expressions yielding feasible configurations do not exist, motivating the use of numerical solution methods. However, these approaches rely on local optimization of nonconvex problems, often requiring an accurate initialization or numerous re-initializations to converge to a valid solution. In this work, we first formulate complicated inverse kinematics problems as convex feasibility problems whose low-rank feasible points provide exact IK solutions. We then present CIDGIK (Convex Iteration for Distance-Geometric Inverse Kinematics), an algorithm that solves these feasibility problems with a sequence of semidefinite programs whose objectives are designed to encourage low-rank minimizers. Our problem formulation elegantly unifies the configuration space and workspace constraints of a robot: intrinsic robot geometry and obstacle avoidance are both expressed as simple linear matrix equations and inequalities. Our experimental results for a variety of popular manipulator models demonstrate faster and more accurate convergence than a conventional nonlinear optimization-based approach, especially in environments with many obstacles.
Riemannian Optimization for Distance Geometric Inverse Kinematics
Aug 31, 2021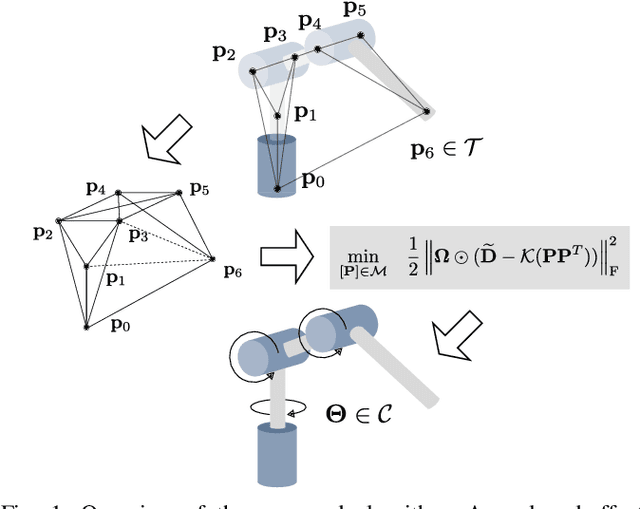
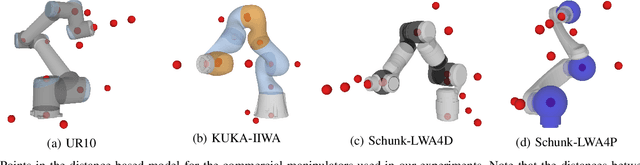
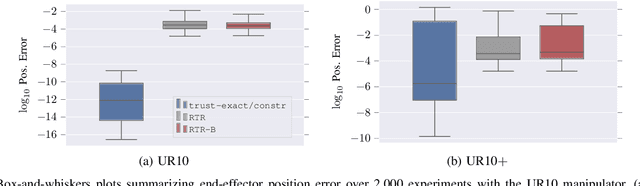
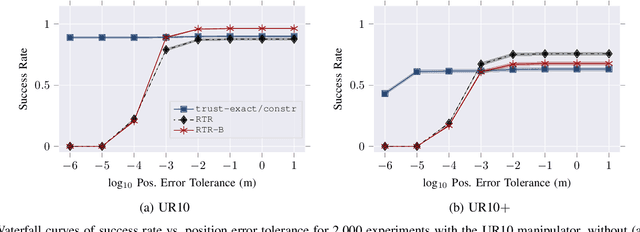
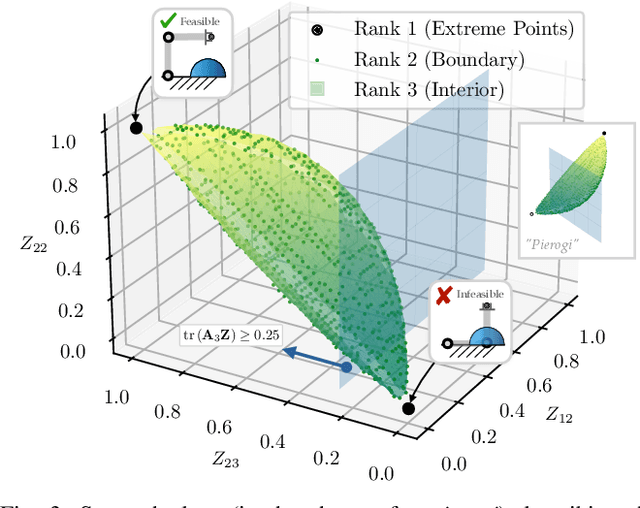
Solving the inverse kinematics problem is a fundamental challenge in motion planning, control, and calibration for articulated robots. Kinematic models for these robots are typically parameterized by joint angles, generating a complicated mapping between a robot's configuration and end-effector pose. Alternatively, the kinematic model and task constraints can be represented using invariant distances between points attached to the robot. In this paper, we formalize the equivalence of distance-based inverse kinematics and the distance geometry problem for a large class of articulated robots and task constraints. Unlike previous approaches, we use the connection between distance geometry and low-rank matrix completion to find inverse kinematics solutions by completing a partial Euclidean distance matrix through local optimization. Furthermore, we parameterize the space of Euclidean distance matrices with the Riemannian manifold of fixed-rank Gram matrices, allowing us to leverage a variety of mature Riemannian optimization methods. Finally, we show that bound smoothing can be used to generate informed initializations without significant computational overhead, improving convergence. We demonstrate that our novel inverse kinematics solver achieves higher success rates than traditional techniques, and significantly outperforms them on problems that involve many workspace constraints.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021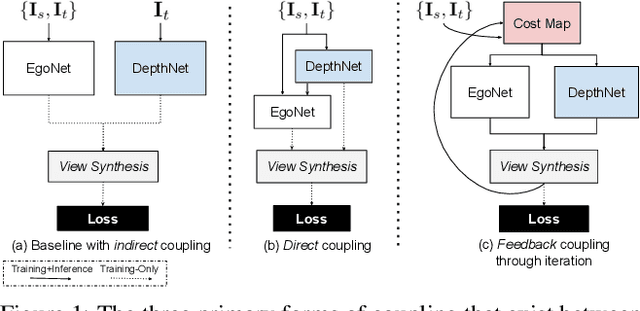
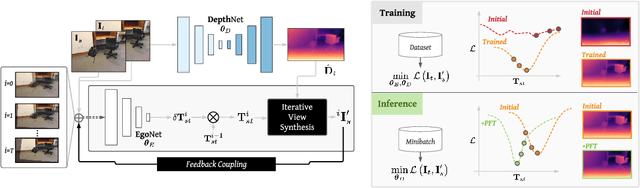

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
A Question of Time: Revisiting the Use of Recursive Filtering for Temporal Calibration of Multisensor Systems
Jun 01, 2021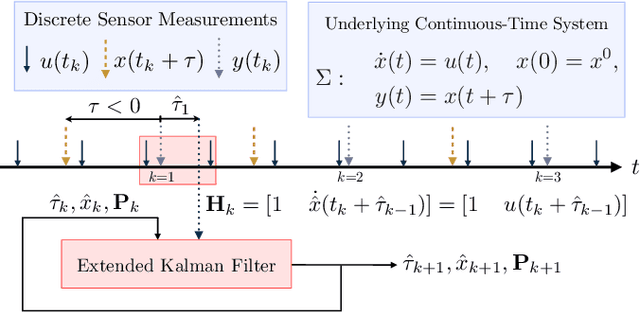
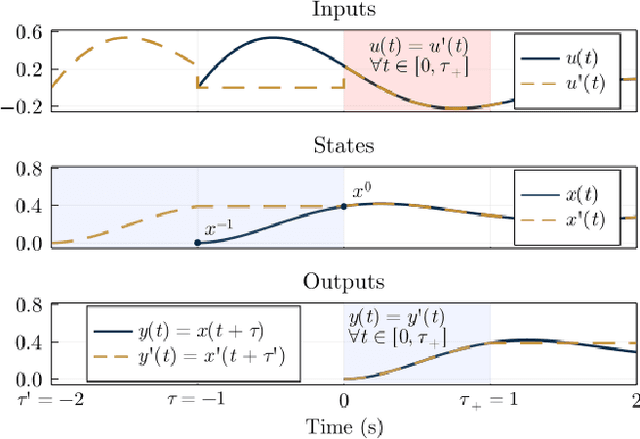
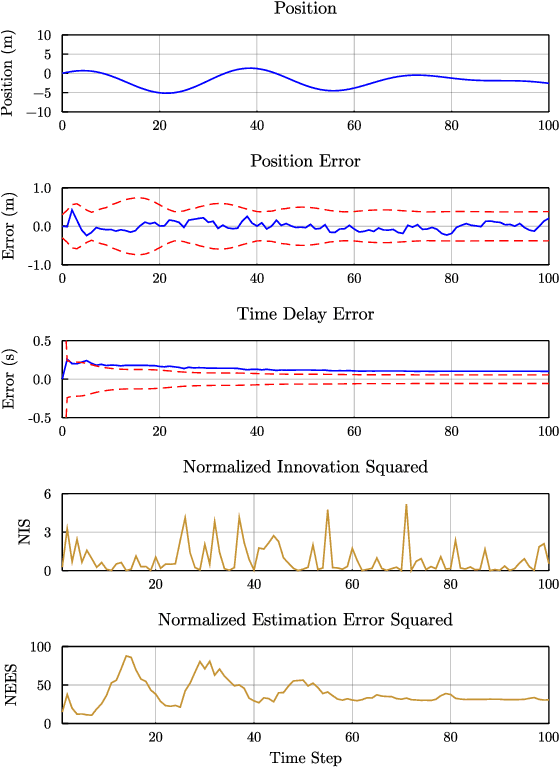
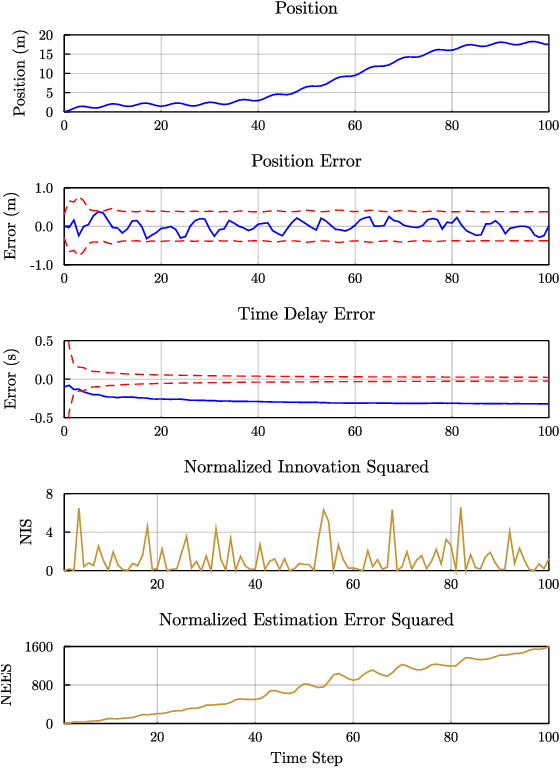
We examine the problem of time delay estimation, or temporal calibration, in the context of multisensor data fusion. Differences in processing intervals and other factors typically lead to a relative delay between measurement from two disparate sensors. Correct (optimal) data fusion demands that the relative delay must either be known in advance or identified online. There have been several recent proposals in the literature to determine the delay parameter using recursive, causal filters such as the extended Kalman filter (EKF). We carefully review this formulation and show that there are fundamental issues with the structure of the EKF (and related algorithms) when the delay is included in the filter state vector as a value to be estimated. These structural issues, in turn, leave recursive filters prone to bias and inconsistency. Our theoretical analysis is supported by simulation studies that demonstrate the implications in terms of filter performance; although tuning of the filter noise variances may reduce the chance of inconsistency or divergence, the underlying structural concerns remain. We offer brief suggestions for ways to maintain the computational efficiency of recursive filtering for temporal calibration while avoiding the drawbacks of the standard algorithms.
Seeing All the Angles: Learning Multiview Manipulation Policies for Contact-Rich Tasks from Demonstrations
Apr 28, 2021
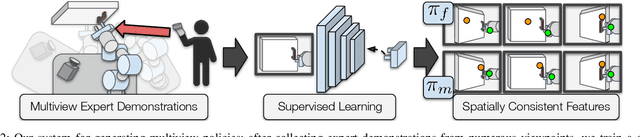
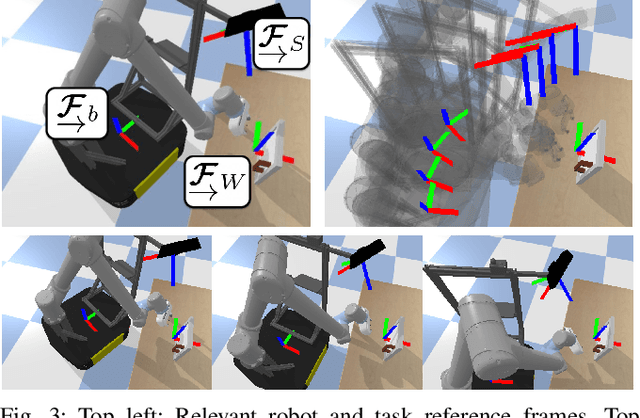
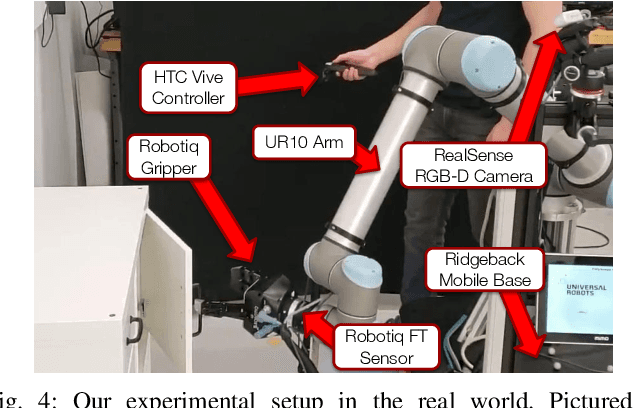
Learned visuomotor policies have shown considerable success as an alternative to traditional, hand-crafted frameworks for robotic manipulation tasks. Surprisingly, the extension of these methods to the multiview domain is relatively unexplored. A successful multiview policy could be deployed on a mobile manipulation platform, allowing it to complete a task regardless of its view of the scene. In this work, we demonstrate that a multiview policy can be found through imitation learning by collecting data from a variety of viewpoints. We illustrate the general applicability of the method by learning to complete several challenging multi-stage and contact-rich tasks, from numerous viewpoints, both in a simulated environment and on a real mobile manipulation platform. Furthermore, we analyze our policies to determine the benefits of learning from multiview data compared to learning with data from a fixed perspective. We show that learning from multiview data has little, if any, penalty to performance for a fixed-view task compared to learning with an equivalent amount of fixed-view data. Finally, we examine the visual features learned by the multiview and fixed-view policies. Our results indicate that multiview policies implicitly learn to identify spatially correlated features with a degree of view-invariance.
Under Pressure: Learning to Detect Slip with Barometric Tactile Sensors
Mar 24, 2021



The ability to perceive object slip through tactile feedback allows humans to accomplish complex manipulation tasks including maintaining a stable grasp. Despite the utility of tactile information for many robotics applications, tactile sensors have yet to be widely deployed in industrial settings -- part of the challenge lies in identifying slip and other key events from the tactile data stream. In this paper, we present a learning-based method to detect slip using barometric tactile sensors. These sensors have many desirable properties including high reliability and durability, and are built from very inexpensive components. We are able to achieve slip detection accuracies of greater than 91% while displaying robustness to the speed and direction of the slip motion. Further, we test our detector on two robot manipulation tasks involving a variety of common objects and demonstrate successful generalization to real-world scenarios not seen during training. We show that barometric tactile sensing technology, combined with data-driven learning, is potentially suitable for many complex manipulation tasks such as slip compensation.
A Continuous-Time Approach for 3D Radar-to-Camera Extrinsic Calibration
Mar 12, 2021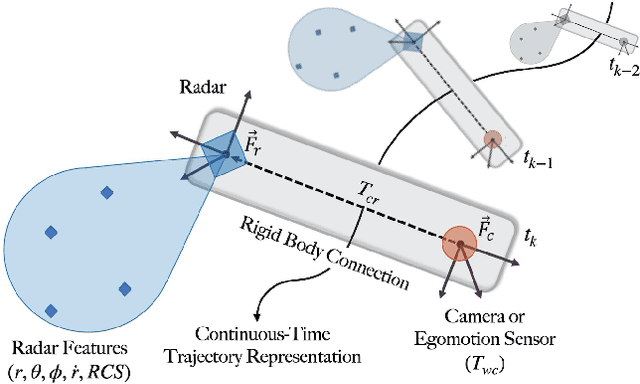
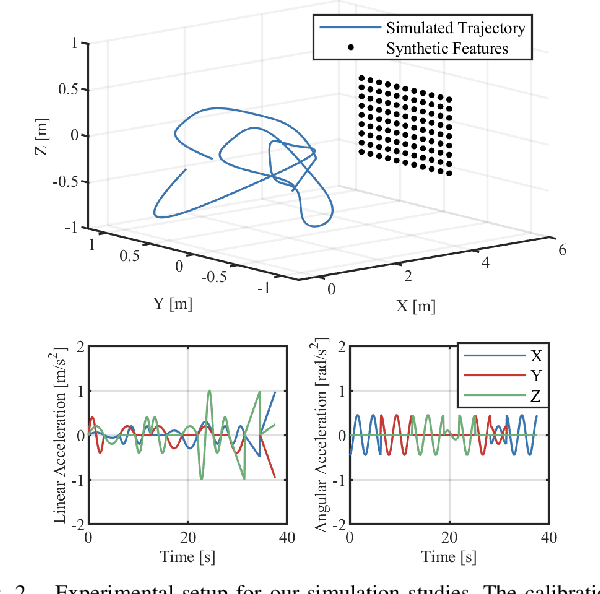
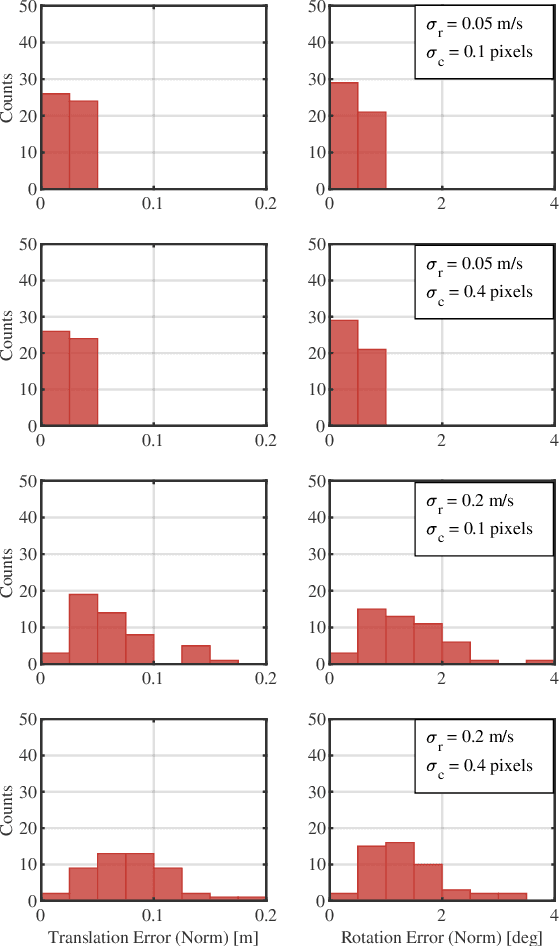

Reliable operation in inclement weather is essential to the deployment of safe autonomous vehicles (AVs). Robustness and reliability can be achieved by fusing data from the standard AV sensor suite (i.e., lidars, cameras) with weather robust sensors, such as millimetre-wavelength radar. Critically, accurate sensor data fusion requires knowledge of the rigid-body transform between sensor pairs, which can be determined through the process of extrinsic calibration. A number of extrinsic calibration algorithms have been designed for 2D (planar) radar sensors - however, recently-developed, low-cost 3D millimetre-wavelength radars are set to displace their 2D counterparts in many applications. In this paper, we present a continuous-time 3D radar-to-camera extrinsic calibration algorithm that utilizes radar velocity measurements and, unlike the majority of existing techniques, does not require specialized radar retroreflectors to be present in the environment. We derive the observability properties of our formulation and demonstrate the efficacy of our algorithm through synthetic and real-world experiments.