 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPID: An Aggregation Method for Federated Learning
Nov 04, 2024This paper presents FedPID, our submission to the Federated Tumor Segmentation Challenge 2024 (FETS24). Inspired by FedCostWAvg and FedPIDAvg, our winning contributions to FETS21 and FETS2022, we propose an improved aggregation strategy for federated and collaborative learning. FedCostWAvg is a method that averages results by considering both the number of training samples in each group and how much the cost function decreased in the last round of training. This is similar to how the derivative part of a PID controller works. In FedPIDAvg, we also included the integral part that was missing. Another challenge we faced were vastly differing dataset sizes at each center. We solved this by assuming the sizes follow a Poisson distribution and adjusting the training iterations for each center accordingly. Essentially, this part of the method controls that outliers that require too much training time are less frequently used. Based on these contributions we now adapted FedPIDAvg by changing how the integral part is computed. Instead of integrating the loss function we measure the global drop in cost since the first round.
Detecting Unforeseen Data Properties with Diffusion Autoencoder Embeddings using Spine MRI data
Oct 14, 2024



Deep learning has made significant strides in medical imaging, leveraging the use of large datasets to improve diagnostics and prognostics. However, large datasets often come with inherent errors through subject selection and acquisition. In this paper, we investigate the use of Diffusion Autoencoder (DAE) embeddings for uncovering and understanding data characteristics and biases, including biases for protected variables like sex and data abnormalities indicative of unwanted protocol variations. We use sagittal T2-weighted magnetic resonance (MR) images of the neck, chest, and lumbar region from 11186 German National Cohort (NAKO) participants. We compare DAE embeddings with existing generative models like StyleGAN and Variational Autoencoder. Evaluations on a large-scale dataset consisting of sagittal T2-weighted MR images of three spine regions show that DAE embeddings effectively separate protected variables such as sex and age. Furthermore, we used t-SNE visualization to identify unwanted variations in imaging protocols, revealing differences in head positioning. Our embedding can identify samples where a sex predictor will have issues learning the correct sex. Our findings highlight the potential of using advanced embedding techniques like DAEs to detect data quality issues and biases in medical imaging datasets. Identifying such hidden relations can enhance the reliability and fairness of deep learning models in healthcare applications, ultimately improving patient care and outcomes.
Physics-Regularized Multi-Modal Image Assimilation for Brain Tumor Localization
Sep 30, 2024



Physical models in the form of partial differential equations represent an important prior for many under-constrained problems. One example is tumor treatment planning, which heavily depends on accurate estimates of the spatial distribution of tumor cells in a patient's anatomy. Medical imaging scans can identify the bulk of the tumor, but they cannot reveal its full spatial distribution. Tumor cells at low concentrations remain undetectable, for example, in the most frequent type of primary brain tumors, glioblastoma. Deep-learning-based approaches fail to estimate the complete tumor cell distribution due to a lack of reliable training data. Most existing works therefore rely on physics-based simulations to match observed tumors, providing anatomically and physiologically plausible estimations. However, these approaches struggle with complex and unknown initial conditions and are limited by overly rigid physical models. In this work, we present a novel method that balances data-driven and physics-based cost functions. In particular, we propose a unique discretization scheme that quantifies the adherence of our learned spatiotemporal tumor and brain tissue distributions to their corresponding growth and elasticity equations. This quantification, serving as a regularization term rather than a hard constraint, enables greater flexibility and proficiency in assimilating patient data than existing models. We demonstrate improved coverage of tumor recurrence areas compared to existing techniques on real-world data from a cohort of patients. The method holds the potential to enhance clinical adoption of model-driven treatment planning for glioblastoma.
3D Vessel Graph Generation Using Denoising Diffusion
Jul 08, 2024



Blood vessel networks, represented as 3D graphs, help predict disease biomarkers, simulate blood flow, and aid in synthetic image generation, relevant in both clinical and pre-clinical settings. However, generating realistic vessel graphs that correspond to an anatomy of interest is challenging. Previous methods aimed at generating vessel trees mostly in an autoregressive style and could not be applied to vessel graphs with cycles such as capillaries or specific anatomical structures such as the Circle of Willis. Addressing this gap, we introduce the first application of \textit{denoising diffusion models} in 3D vessel graph generation. Our contributions include a novel, two-stage generation method that sequentially denoises node coordinates and edges. We experiment with two real-world vessel datasets, consisting of microscopic capillaries and major cerebral vessels, and demonstrate the generalizability of our method for producing diverse, novel, and anatomically plausible vessel graphs.
Efficient Betti Matching Enables Topology-Aware 3D Segmentation via Persistent Homology
Jul 05, 2024

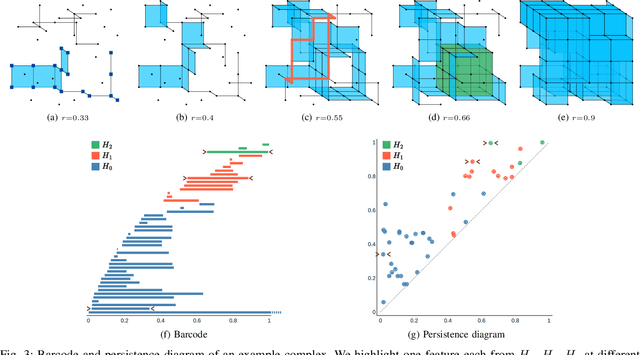

In this work, we propose an efficient algorithm for the calculation of the Betti matching, which can be used as a loss function to train topology aware segmentation networks. Betti matching loss builds on techniques from topological data analysis, specifically persistent homology. A major challenge is the computational cost of computing persistence barcodes. In response to this challenge, we propose a new, highly optimized implementation of Betti matching, implemented in C++ together with a python interface, which achieves significant speedups compared to the state-of-the-art implementation Cubical Ripser. We use Betti matching 3D to train segmentation networks with the Betti matching loss and demonstrate improved topological correctness of predicted segmentations across several datasets. The source code is available at https://github.com/nstucki/Betti-Matching-3D.
TotalVibeSegmentator: Full Torso Segmentation for the NAKO and UK Biobank in Volumetric Interpolated Breath-hold Examination Body Images
May 31, 2024



Objectives: To present a publicly available torso segmentation network for large epidemiology datasets on volumetric interpolated breath-hold examination (VIBE) images. Materials & Methods: We extracted preliminary segmentations from TotalSegmentator, spine, and body composition networks for VIBE images, then improved them iteratively and retrained a nnUNet network. Using subsets of NAKO (85 subjects) and UK Biobank (16 subjects), we evaluated with Dice-score on a holdout set (12 subjects) and existing organ segmentation approach (1000 subjects), generating 71 semantic segmentation types for VIBE images. We provide an additional network for the vertebra segments 22 individual vertebra types. Results: We achieved an average Dice score of 0.89 +- 0.07 overall 71 segmentation labels. We scored > 0.90 Dice-score on the abdominal organs except for the pancreas with a Dice of 0.70. Conclusion: Our work offers a detailed and refined publicly available full torso segmentation on VIBE images.
Topologically faithful multi-class segmentation in medical images
Mar 16, 2024Topological accuracy in medical image segmentation is a highly important property for downstream applications such as network analysis and flow modeling in vessels or cell counting. Recently, significant methodological advancements have brought well-founded concepts from algebraic topology to binary segmentation. However, these approaches have been underexplored in multi-class segmentation scenarios, where topological errors are common. We propose a general loss function for topologically faithful multi-class segmentation extending the recent Betti matching concept, which is based on induced matchings of persistence barcodes. We project the N-class segmentation problem to N single-class segmentation tasks, which allows us to use 1-parameter persistent homology making training of neural networks computationally feasible. We validate our method on a comprehensive set of four medical datasets with highly variant topological characteristics. Our loss formulation significantly enhances topological correctness in cardiac, cell, artery-vein, and Circle of Willis segmentation.
Cross-domain and Cross-dimension Learning for Image-to-Graph Transformers
Mar 11, 2024



Direct image-to-graph transformation is a challenging task that solves object detection and relationship prediction in a single model. Due to the complexity of this task, large training datasets are rare in many domains, which makes the training of large networks challenging. This data sparsity necessitates the establishment of pre-training strategies akin to the state-of-the-art in computer vision. In this work, we introduce a set of methods enabling cross-domain and cross-dimension transfer learning for image-to-graph transformers. We propose (1) a regularized edge sampling loss for sampling the optimal number of object relationships (edges) across domains, (2) a domain adaptation framework for image-to-graph transformers that aligns features from different domains, and (3) a simple projection function that allows us to pretrain 3D transformers on 2D input data. We demonstrate our method's utility in cross-domain and cross-dimension experiments, where we pretrain our models on 2D satellite images before applying them to vastly different target domains in 2D and 3D. Our method consistently outperforms a series of baselines on challenging benchmarks, such as retinal or whole-brain vessel graph extraction.
Simulation-Based Segmentation of Blood Vessels in Cerebral 3D OCTA Images
Mar 11, 2024



Segmentation of blood vessels in murine cerebral 3D OCTA images is foundational for in vivo quantitative analysis of the effects of neurovascular disorders, such as stroke or Alzheimer's, on the vascular network. However, to accurately segment blood vessels with state-of-the-art deep learning methods, a vast amount of voxel-level annotations is required. Since cerebral 3D OCTA images are typically plagued by artifacts and generally have a low signal-to-noise ratio, acquiring manual annotations poses an especially cumbersome and time-consuming task. To alleviate the need for manual annotations, we propose utilizing synthetic data to supervise segmentation algorithms. To this end, we extract patches from vessel graphs and transform them into synthetic cerebral 3D OCTA images paired with their matching ground truth labels by simulating the most dominant 3D OCTA artifacts. In extensive experiments, we demonstrate that our approach achieves competitive results, enabling annotation-free blood vessel segmentation in cerebral 3D OCTA images.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.