 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Causal State Representations of Partially Observable Environments
Jun 25, 2019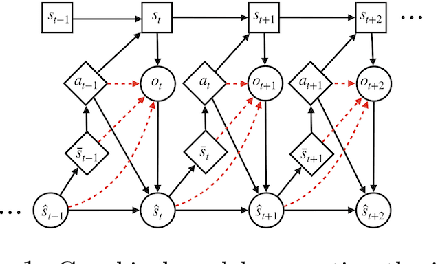
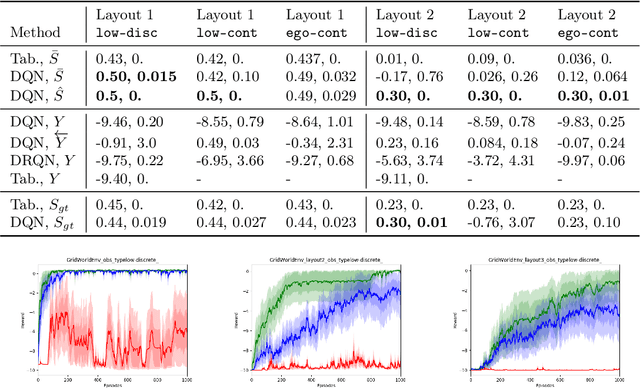
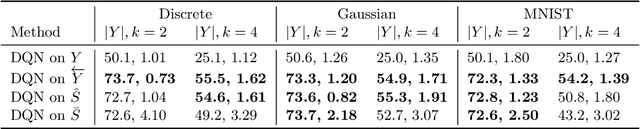

Intelligent agents can cope with sensory-rich environments by learning task-agnostic state abstractions. In this paper, we propose mechanisms to approximate causal states, which optimally compress the joint history of actions and observations in partially-observable Markov decision processes. Our proposed algorithm extracts causal state representations from RNNs that are trained to predict subsequent observations given the history. We demonstrate that these learned task-agnostic state abstractions can be used to efficiently learn policies for reinforcement learning problems with rich observation spaces. We evaluate agents using multiple partially observable navigation tasks with both discrete (GridWorld) and continuous (VizDoom, ALE) observation processes that cannot be solved by traditional memory-limited methods. Our experiments demonstrate systematic improvement of the DQN and tabular models using approximate causal state representations with respect to recurrent-DQN baselines trained with raw inputs.
Gossip-based Actor-Learner Architectures for Deep Reinforcement Learning
Jun 09, 2019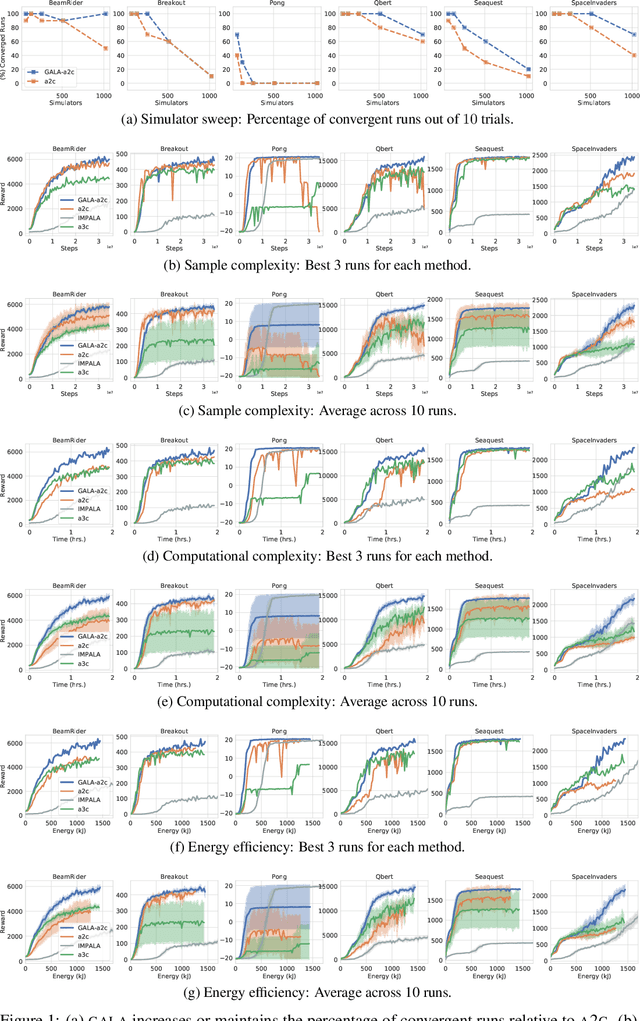
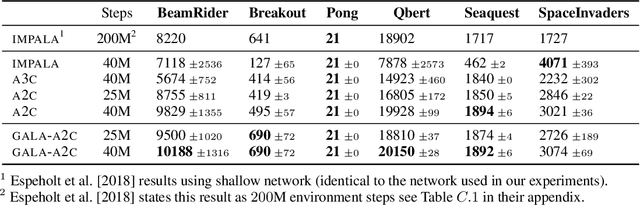
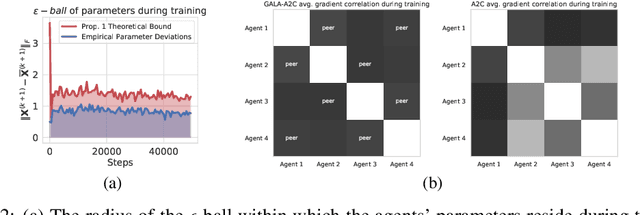
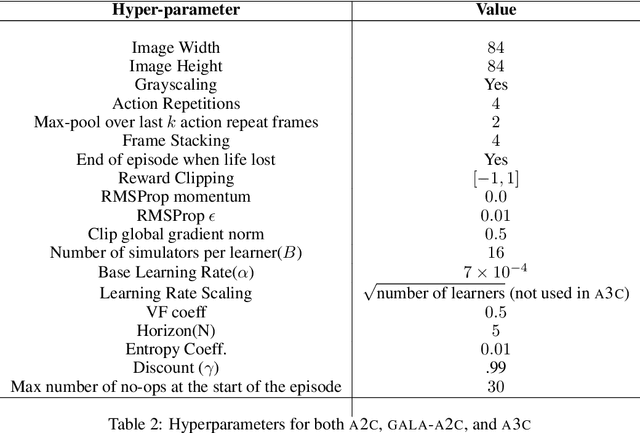
Multi-simulator training has contributed to the recent success of Deep Reinforcement Learning by stabilizing learning and allowing for higher training throughputs. We propose Gossip-based Actor-Learner Architectures (GALA) where several actor-learners (such as A2C agents) are organized in a peer-to-peer communication topology, and exchange information through asynchronous gossip in order to take advantage of a large number of distributed simulators. We prove that GALA agents remain within an epsilon-ball of one-another during training when using loosely coupled asynchronous communication. By reducing the amount of synchronization between agents, GALA is more computationally efficient and scalable compared to A2C, its fully-synchronous counterpart. GALA also outperforms A2C, being more robust and sample efficient. We show that we can run several loosely coupled GALA agents in parallel on a single GPU and achieve significantly higher hardware utilization and frame-rates than vanilla A2C at comparable power draws.
Recurrent Value Functions
May 23, 2019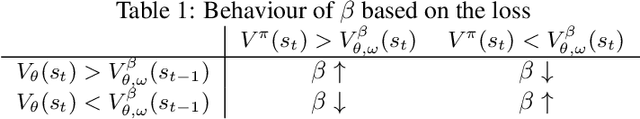
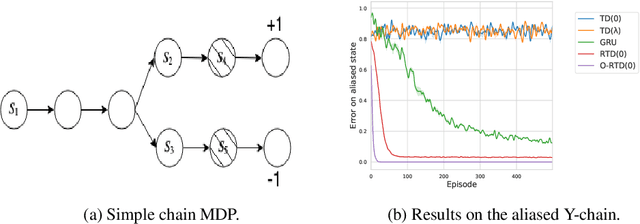
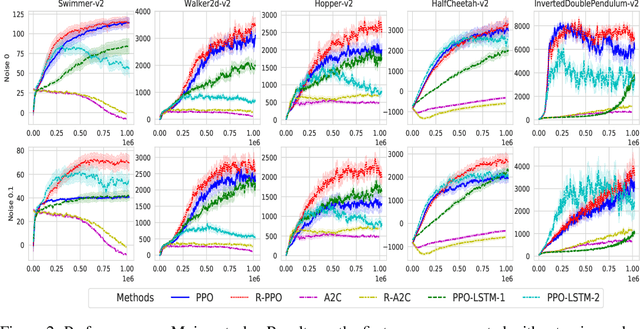
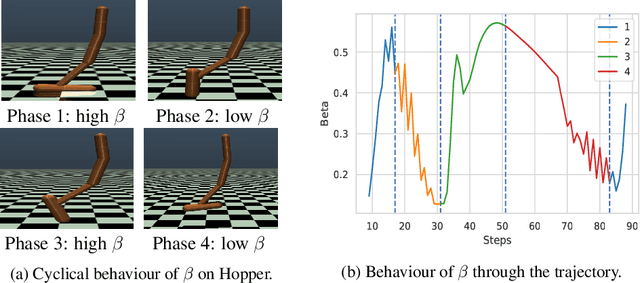
Despite recent successes in Reinforcement Learning, value-based methods often suffer from high variance hindering performance. In this paper, we illustrate this in a continuous control setting where state of the art methods perform poorly whenever sensor noise is introduced. To overcome this issue, we introduce Recurrent Value Functions (RVFs) as an alternative to estimate the value function of a state. We propose to estimate the value function of the current state using the value function of past states visited along the trajectory. Due to the nature of their formulation, RVFs have a natural way of learning an emphasis function that selectively emphasizes important states. First, we establish RVF's asymptotic convergence properties in tabular settings. We then demonstrate their robustness on a partially observable domain and continuous control tasks. Finally, we provide a qualitative interpretation of the learned emphasis function.
Leveraging exploration in off-policy algorithms via normalizing flows
May 16, 2019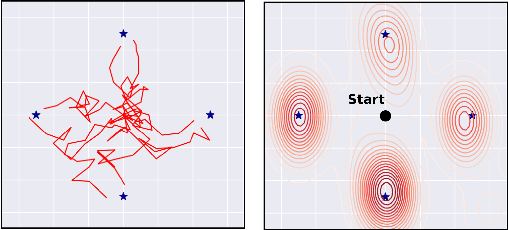
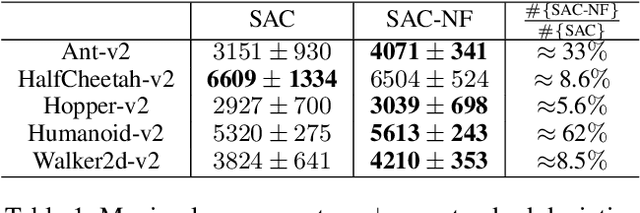
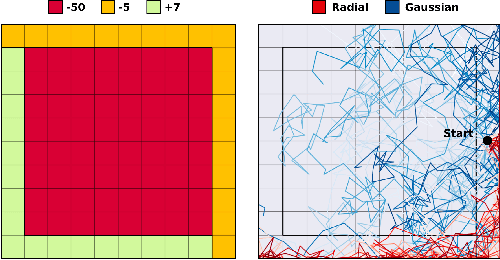
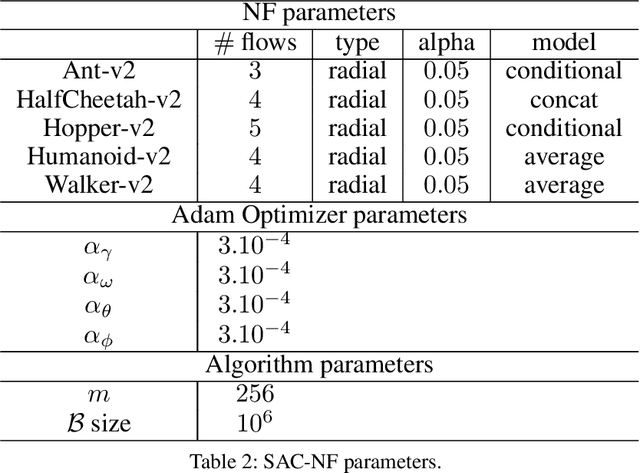
Exploration is a crucial component for discovering approximately optimal policies in most high-dimensional reinforcement learning (RL) settings with sparse rewards. Approaches such as neural density models and continuous exploration (e.g., Go-Explore) have been instrumental in recent advances. Soft actor-critic (SAC) is a method for improving exploration that aims to combine off-policy updates while maximizing the policy entropy. We extend SAC to a richer class of probability distributions through normalizing flows, which we show improves performance in exploration, sample complexity, and convergence. Finally, we show that not only the normalizing flow policy outperforms SAC on MuJoCo domains, it is also significantly lighter, using as low as 5.6% of the original network's parameters for similar performance.
On the Pitfalls of Measuring Emergent Communication
Mar 12, 2019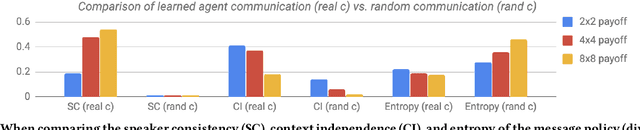
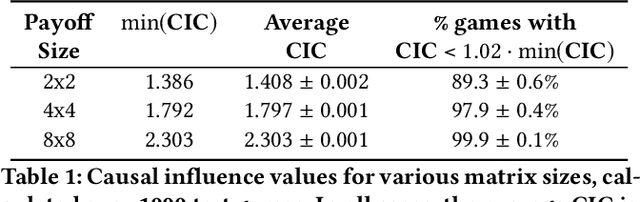
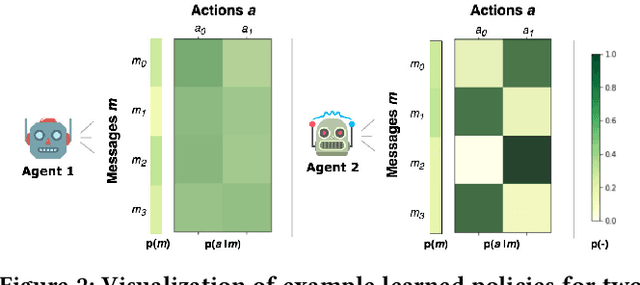
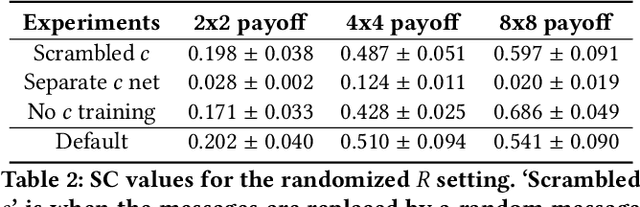
How do we know if communication is emerging in a multi-agent system? The vast majority of recent papers on emergent communication show that adding a communication channel leads to an increase in reward or task success. This is a useful indicator, but provides only a coarse measure of the agent's learned communication abilities. As we move towards more complex environments, it becomes imperative to have a set of finer tools that allow qualitative and quantitative insights into the emergence of communication. This may be especially useful to allow humans to monitor agents' behaviour, whether for fault detection, assessing performance, or even building trust. In this paper, we examine a few intuitive existing metrics for measuring communication, and show that they can be misleading. Specifically, by training deep reinforcement learning agents to play simple matrix games augmented with a communication channel, we find a scenario where agents appear to communicate (their messages provide information about their subsequent action), and yet the messages do not impact the environment or other agent in any way. We explain this phenomenon using ablation studies and by visualizing the representations of the learned policies. We also survey some commonly used metrics for measuring emergent communication, and provide recommendations as to when these metrics should be used.
Separating value functions across time-scales
Feb 08, 2019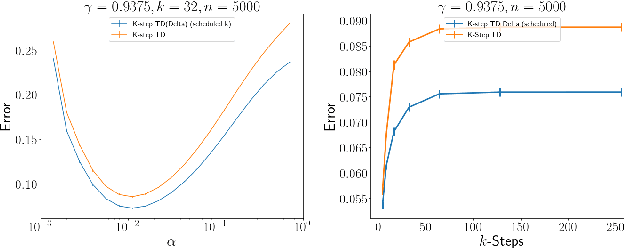

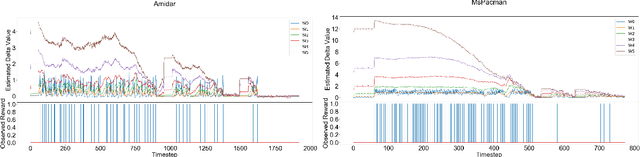
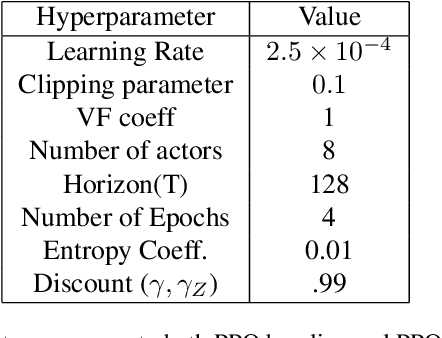
In many finite horizon episodic reinforcement learning (RL) settings, it is desirable to optimize for the undiscounted return - in settings like Atari, for instance, the goal is to collect the most points while staying alive in the long run. Yet, it may be difficult (or even intractable) mathematically to learn with this target. As such, temporal discounting is often applied to optimize over a shorter effective planning horizon. This comes at the cost of potentially biasing the optimization target away from the undiscounted goal. In settings where this bias is unacceptable - where the system must optimize for longer horizons at higher discounts - the target of the value function approximator may increase in variance leading to difficulties in learning. We present an extension of temporal difference (TD) learning, which we call TD($\Delta$), that breaks down a value function into a series of components based on the differences between value functions with smaller discount factors. The separation of a longer horizon value function into these components has useful properties in scalability and performance. We discuss these properties and show theoretic and empirical improvements over standard TD learning in certain settings.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019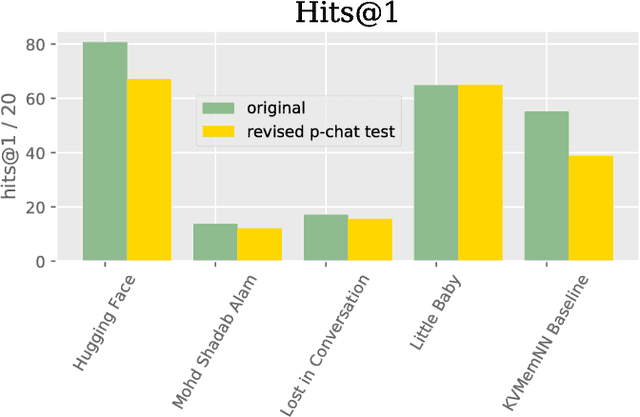

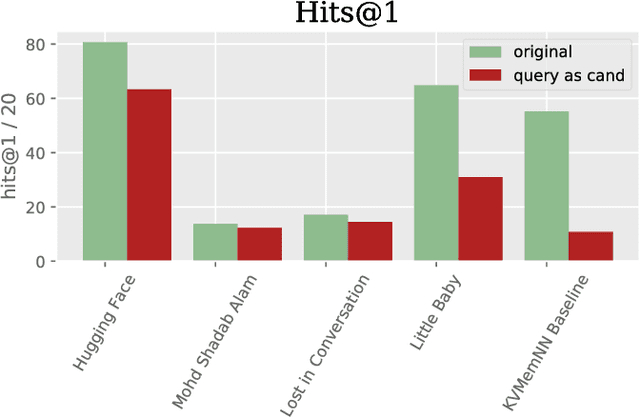
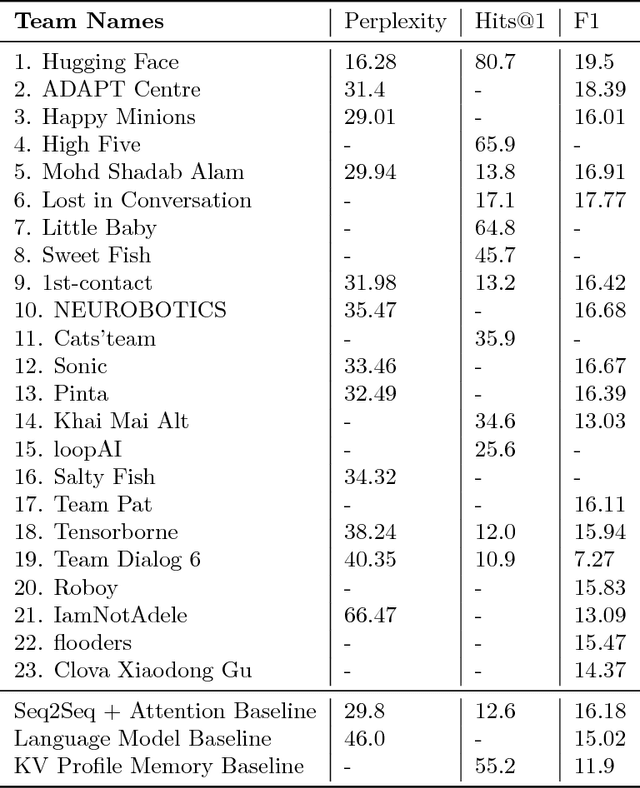
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Deep Generative Modeling of LiDAR Data
Dec 17, 2018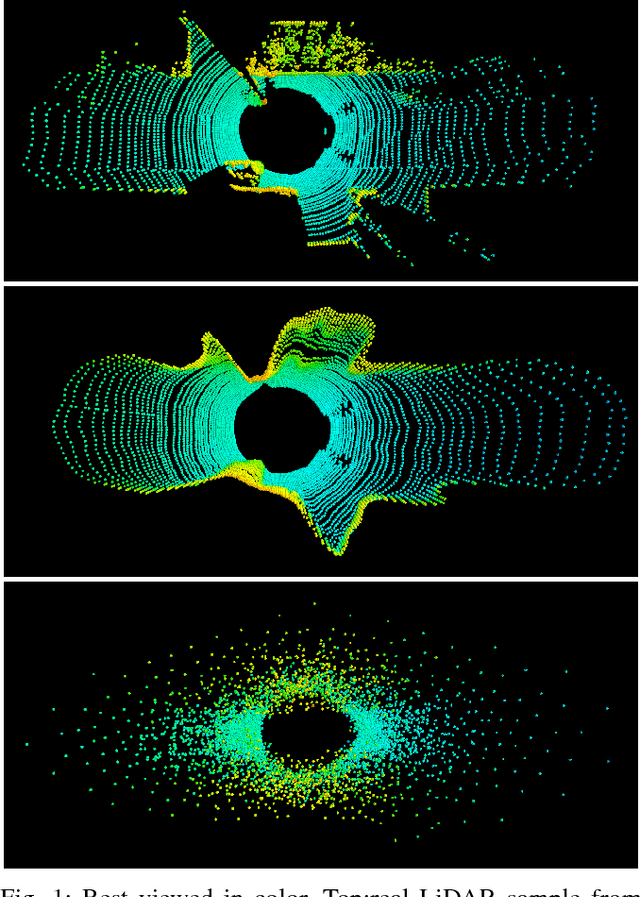

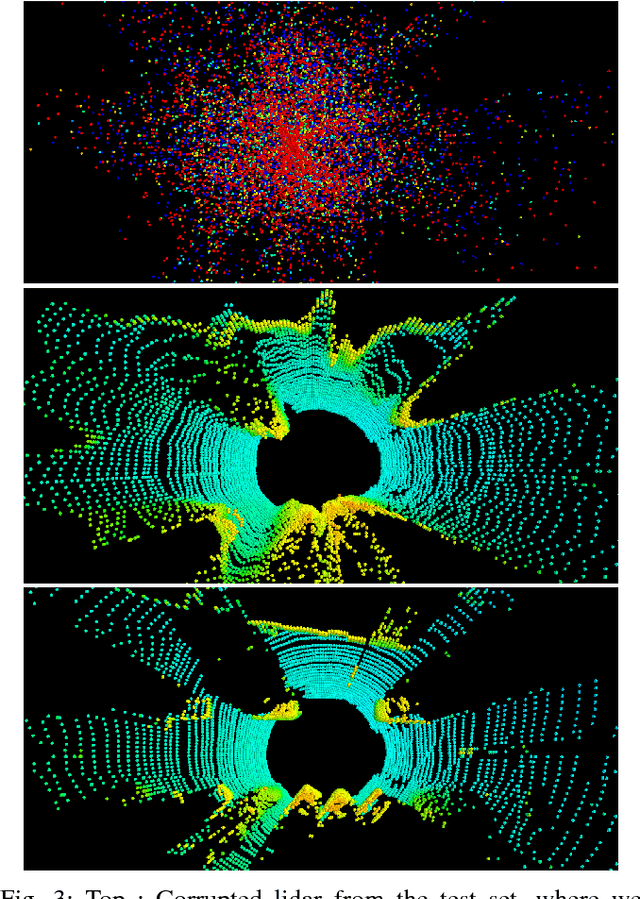
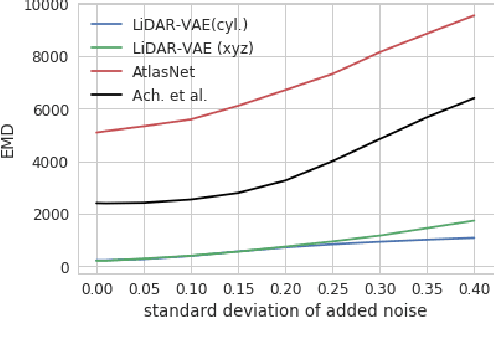
Building models capable of generating structured output is a key challenge for AI and robotics. While generative models have been explored on many types of data, little work has been done on synthesizing lidar scans, which play a key role in robot mapping and localization. In this work, we show that one can adapt deep generative models for this task by unravelling lidar scans into a multi-channel 2D signal. Our approach can generate high quality samples, while simultaneously learning a meaningful latent representation of the data. Furthermore, we demonstrate that our method is robust to noisy input - the learned model can recover the underlying lidar scan from seemingly uninformative data.
An Introduction to Deep Reinforcement Learning
Dec 03, 2018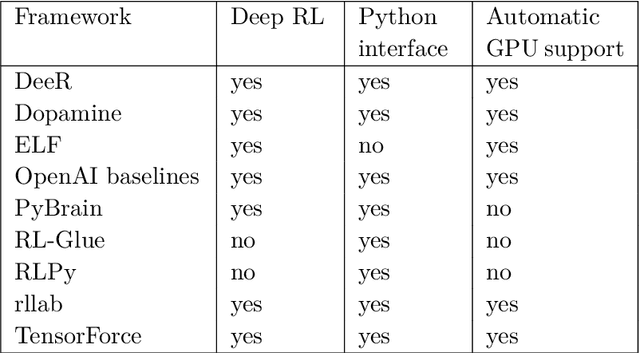
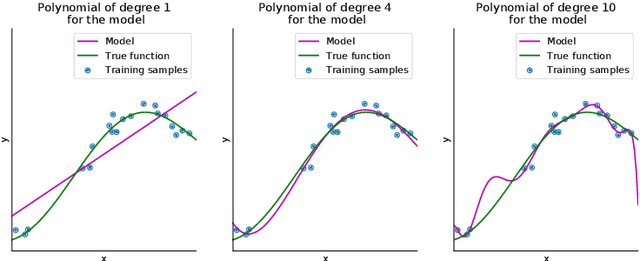
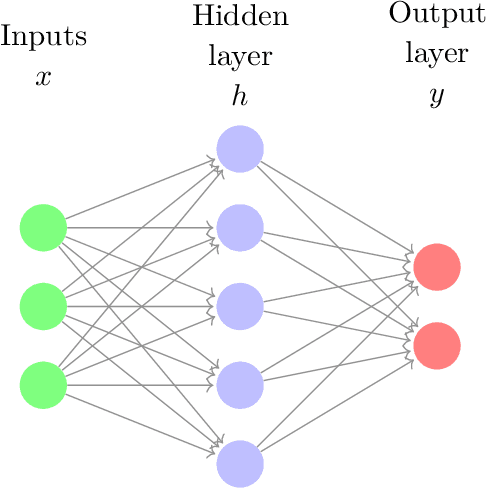
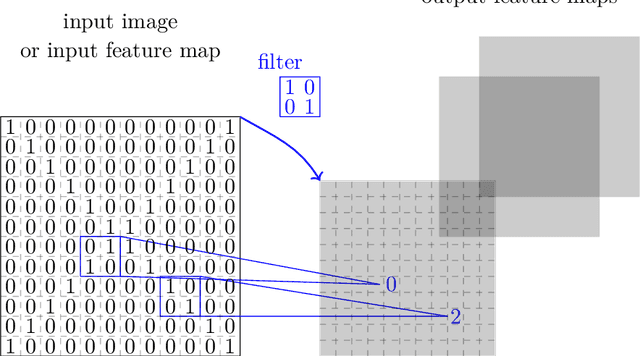
Deep reinforcement learning is the combination of reinforcement learning (RL) and deep learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more. This manuscript provides an introduction to deep reinforcement learning models, algorithms and techniques. Particular focus is on the aspects related to generalization and how deep RL can be used for practical applications. We assume the reader is familiar with basic machine learning concepts.
Natural Environment Benchmarks for Reinforcement Learning
Nov 14, 2018

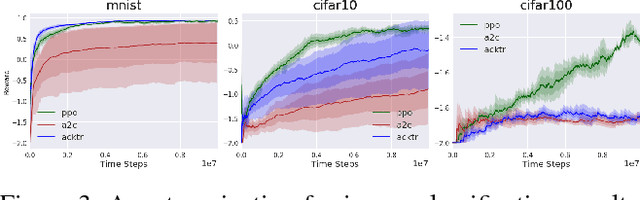
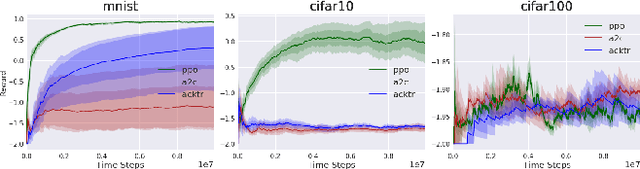
While current benchmark reinforcement learning (RL) tasks have been useful to drive progress in the field, they are in many ways poor substitutes for learning with real-world data. By testing increasingly complex RL algorithms on low-complexity simulation environments, we often end up with brittle RL policies that generalize poorly beyond the very specific domain. To combat this, we propose three new families of benchmark RL domains that contain some of the complexity of the natural world, while still supporting fast and extensive data acquisition. The proposed domains also permit a characterization of generalization through fair train/test separation, and easy comparison and replication of results. Through this work, we challenge the RL research community to develop more robust algorithms that meet high standards of evaluation.