 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale, Open-Domain, Mixed-Interface Dialogue-Based ITS for STEM
May 06, 2020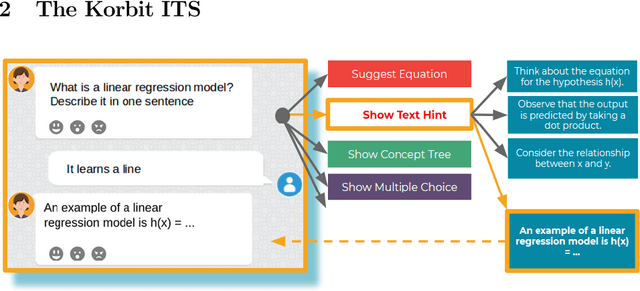
We present Korbit, a large-scale, open-domain, mixed-interface, dialogue-based intelligent tutoring system (ITS). Korbit uses machine learning, natural language processing and reinforcement learning to provide interactive, personalized learning online. Korbit has been designed to easily scale to thousands of subjects, by automating, standardizing and simplifying the content creation process. Unlike other ITS, a teacher can develop new learning modules for Korbit in a matter of hours. To facilitate learning across a widerange of STEM subjects, Korbit uses a mixed-interface, which includes videos, interactive dialogue-based exercises, question-answering, conceptual diagrams, mathematical exercises and gamification elements. Korbit has been built to scale to millions of students, by utilizing a state-of-the-art cloud-based micro-service architecture. Korbit launched its first course in 2019 on machine learning, and since then over 7,000 students have enrolled. Although Korbit was designed to be open-domain and highly scalable, A/B testing experiments with real-world students demonstrate that both student learning outcomes and student motivation are substantially improved compared to typical online courses.
Learning an Unreferenced Metric for Online Dialogue Evaluation
May 01, 2020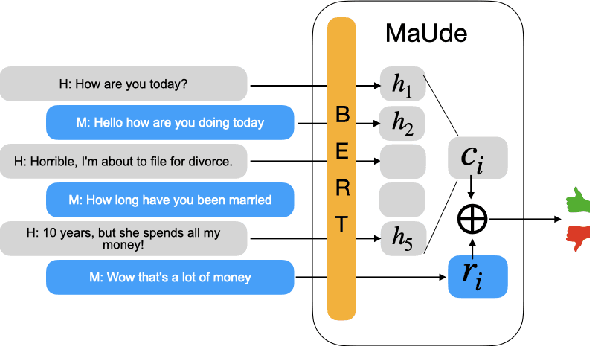
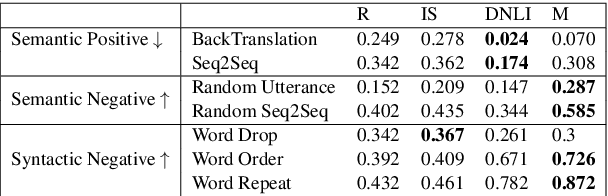
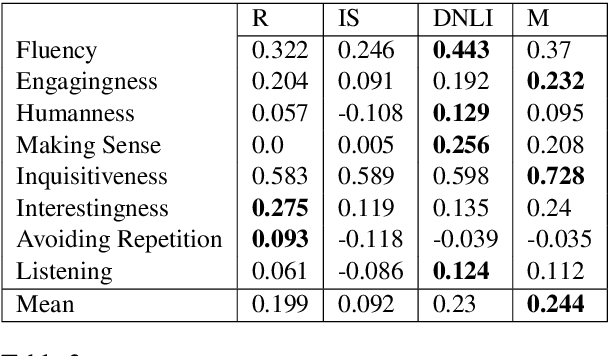
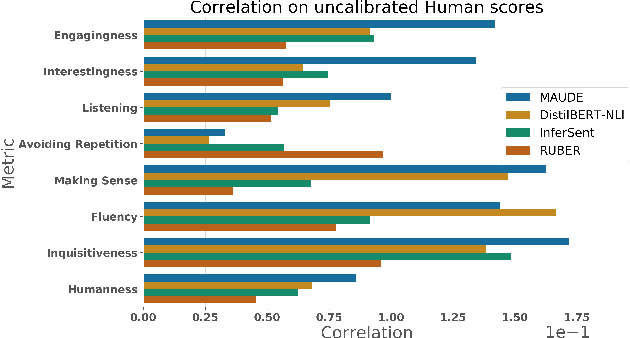
Evaluating the quality of a dialogue interaction between two agents is a difficult task, especially in open-domain chit-chat style dialogue. There have been recent efforts to develop automatic dialogue evaluation metrics, but most of them do not generalize to unseen datasets and/or need a human-generated reference response during inference, making it infeasible for online evaluation. Here, we propose an unreferenced automated evaluation metric that uses large pre-trained language models to extract latent representations of utterances, and leverages the temporal transitions that exist between them. We show that our model achieves higher correlation with human annotations in an online setting, while not requiring true responses for comparison during inference.
Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020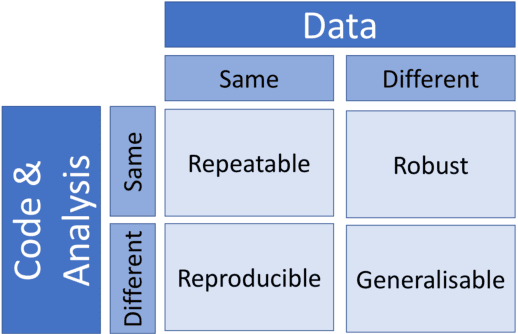
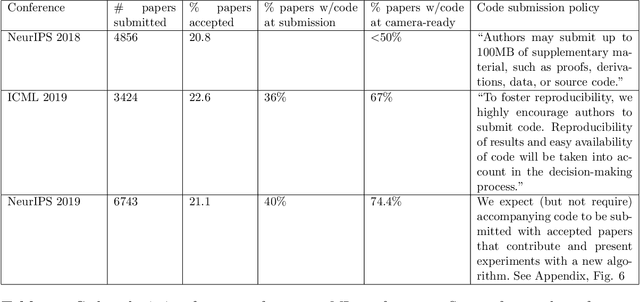
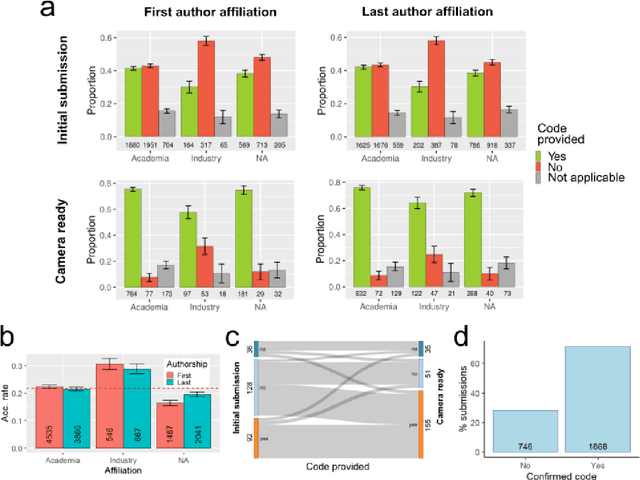
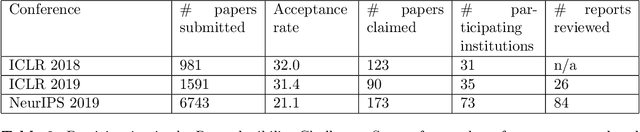
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
Evaluating Logical Generalization in Graph Neural Networks
Mar 14, 2020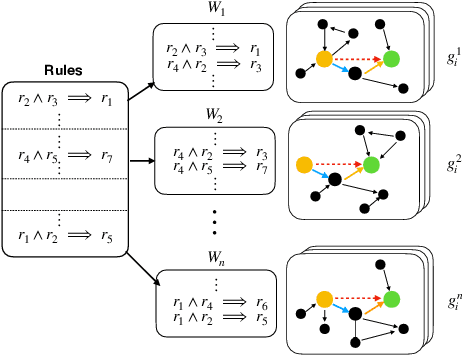
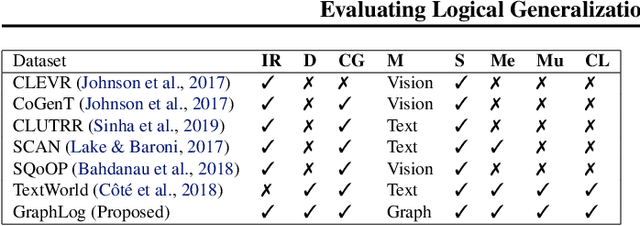
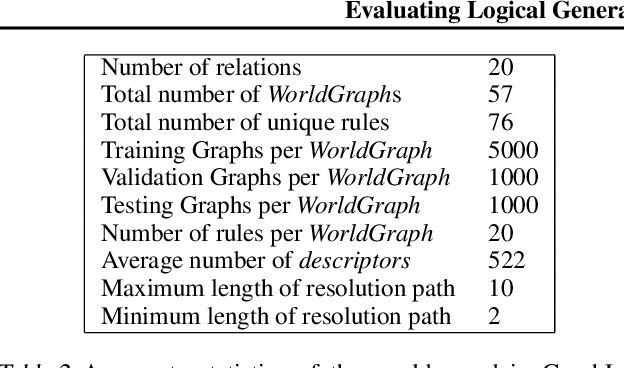
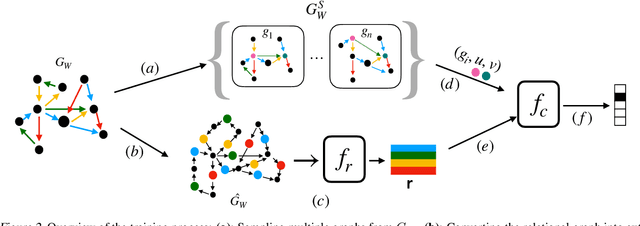
Recent research has highlighted the role of relational inductive biases in building learning agents that can generalize and reason in a compositional manner. However, while relational learning algorithms such as graph neural networks (GNNs) show promise, we do not understand how effectively these approaches can adapt to new tasks. In this work, we study the task of logical generalization using GNNs by designing a benchmark suite grounded in first-order logic. Our benchmark suite, GraphLog, requires that learning algorithms perform rule induction in different synthetic logics, represented as knowledge graphs. GraphLog consists of relation prediction tasks on 57 distinct logical domains. We use GraphLog to evaluate GNNs in three different setups: single-task supervised learning, multi-task pretraining, and continual learning. Unlike previous benchmarks, our approach allows us to precisely control the logical relationship between the different tasks. We find that the ability for models to generalize and adapt is strongly determined by the diversity of the logical rules they encounter during training, and our results highlight new challenges for the design of GNN models. We publicly release the dataset and code used to generate and interact with the dataset at https://www.cs.mcgill.ca/~ksinha4/graphlog.
Interference and Generalization in Temporal Difference Learning
Mar 13, 2020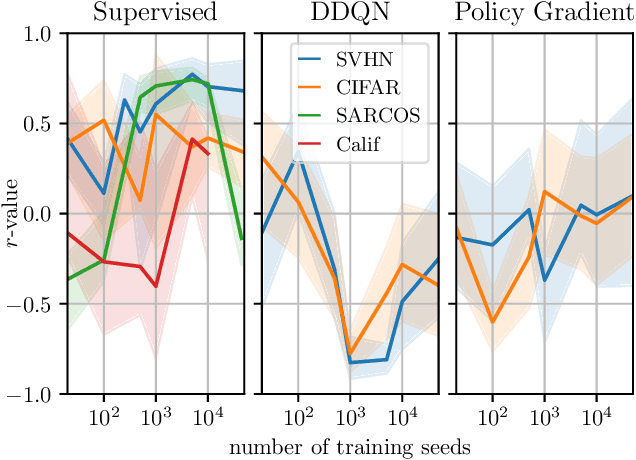
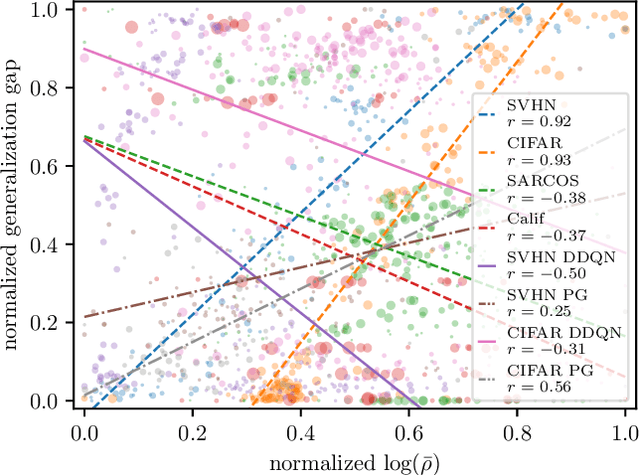
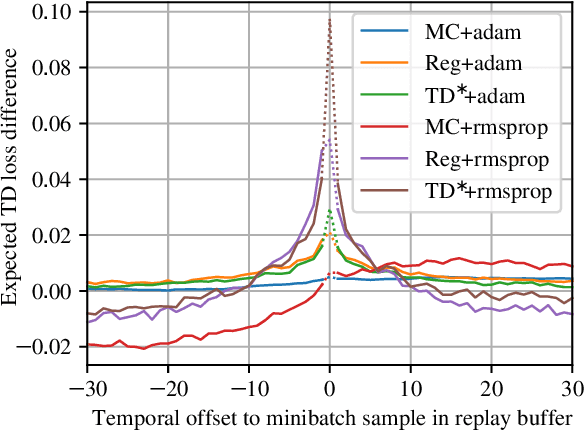
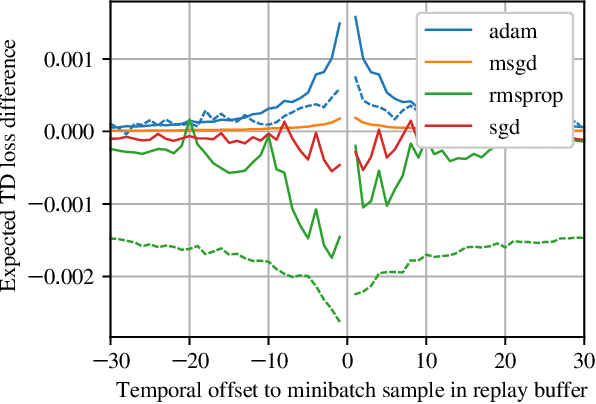
We study the link between generalization and interference in temporal-difference (TD) learning. Interference is defined as the inner product of two different gradients, representing their alignment. This quantity emerges as being of interest from a variety of observations about neural networks, parameter sharing and the dynamics of learning. We find that TD easily leads to low-interference, under-generalizing parameters, while the effect seems reversed in supervised learning. We hypothesize that the cause can be traced back to the interplay between the dynamics of interference and bootstrapping. This is supported empirically by several observations: the negative relationship between the generalization gap and interference in TD, the negative effect of bootstrapping on interference and the local coherence of targets, and the contrast between the propagation rate of information in TD(0) versus TD($\lambda$) and regression tasks such as Monte-Carlo policy evaluation. We hope that these new findings can guide the future discovery of better bootstrapping methods.
Invariant Causal Prediction for Block MDPs
Mar 12, 2020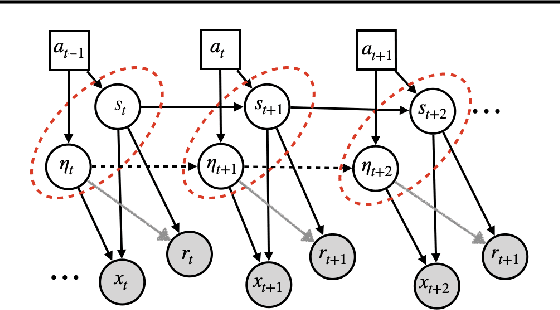
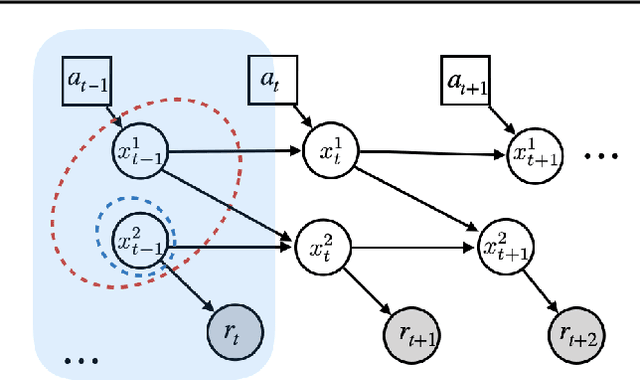
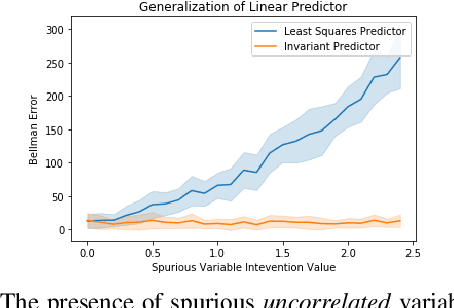
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give empirical evidence that our methods work in both linear and nonlinear settings, attaining improved generalization over single- and multi-task baselines.
Stable Policy Optimization via Off-Policy Divergence Regularization
Mar 09, 2020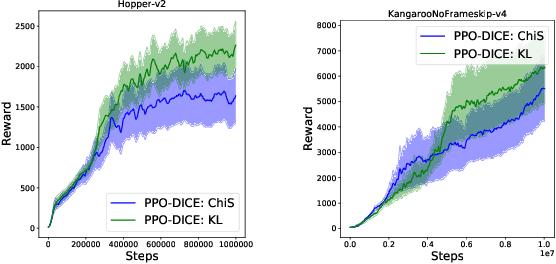
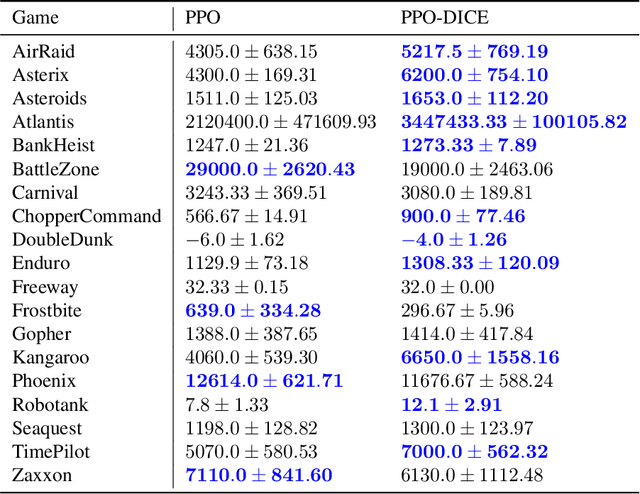
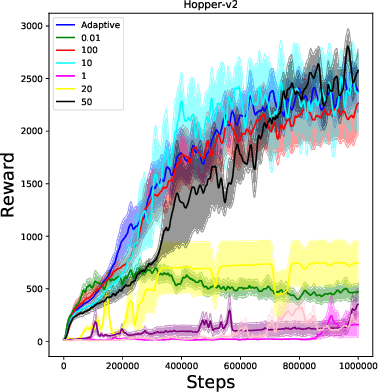
Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO) are among the most successful policy gradient approaches in deep reinforcement learning (RL). While these methods achieve state-of-the-art performance across a wide range of challenging tasks, there is room for improvement in the stabilization of the policy learning and how the off-policy data are used. In this paper we revisit the theoretical foundations of these algorithms and propose a new algorithm which stabilizes the policy improvement through a proximity term that constrains the discounted state-action visitation distribution induced by consecutive policies to be close to one another. This proximity term, expressed in terms of the divergence between the visitation distributions, is learned in an off-policy and adversarial manner. We empirically show that our proposed method can have a beneficial effect on stability and improve final performance in benchmark high-dimensional control tasks.
Scalable Multi-Agent Inverse Reinforcement Learning via Actor-Attention-Critic
Feb 24, 2020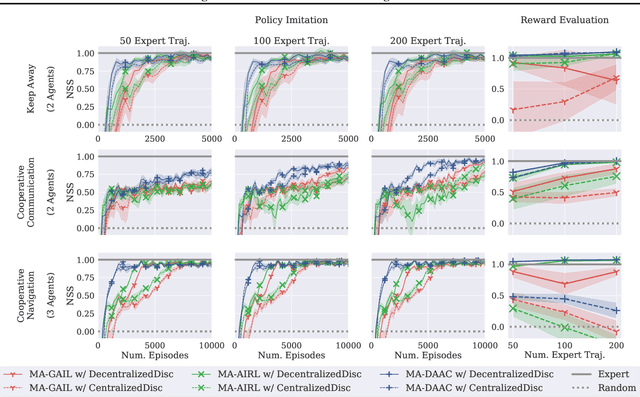
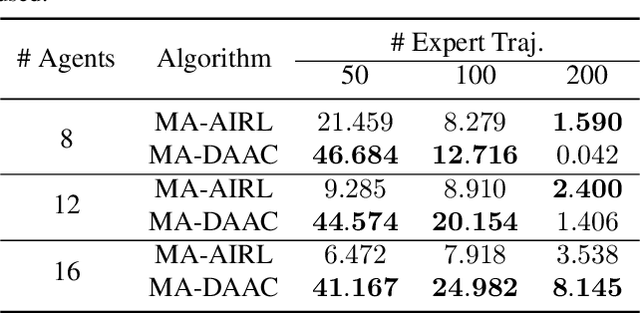
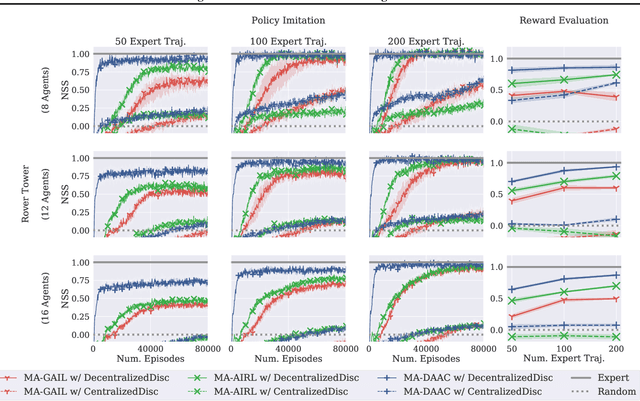
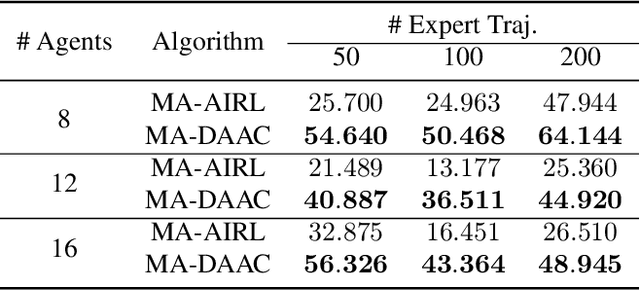
Multi-agent adversarial inverse reinforcement learning (MA-AIRL) is a recent approach that applies single-agent AIRL to multi-agent problems where we seek to recover both policies for our agents and reward functions that promote expert-like behavior. While MA-AIRL has promising results on cooperative and competitive tasks, it is sample-inefficient and has only been validated empirically for small numbers of agents -- its ability to scale to many agents remains an open question. We propose a multi-agent inverse RL algorithm that is more sample-efficient and scalable than previous works. Specifically, we employ multi-agent actor-attention-critic (MAAC) -- an off-policy multi-agent RL (MARL) method -- for the RL inner loop of the inverse RL procedure. In doing so, we are able to increase sample efficiency compared to state-of-the-art baselines, across both small- and large-scale tasks. Moreover, the RL agents trained on the rewards recovered by our method better match the experts than those trained on the rewards derived from the baselines. Finally, our method requires far fewer agent-environment interactions, particularly as the number of agents increases.
Provably efficient reconstruction of policy networks
Feb 07, 2020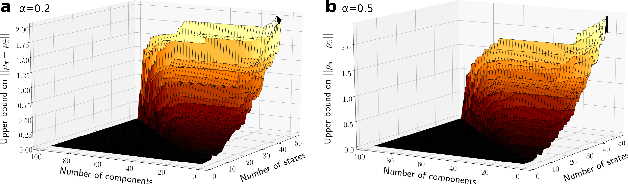
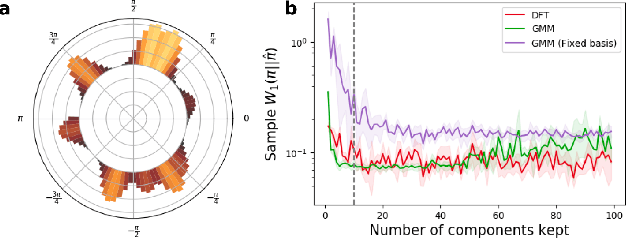
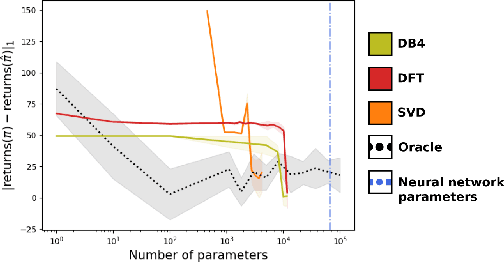
Recent research has shown that learning poli-cies parametrized by large neural networks can achieve significant success on challenging reinforcement learning problems. However, when memory is limited, it is not always possible to store such models exactly for inference, and com-pressing the policy into a compact representation might be necessary. We propose a general framework for policy representation, which reduces this problem to finding a low-dimensional embedding of a given density function in a separable inner product space. Our framework allows us to de-rive strong theoretical guarantees, controlling the error of the reconstructed policies. Such guaran-tees are typically lacking in black-box models, but are very desirable in risk-sensitive tasks. Our experimental results suggest that the reconstructed policies can use less than 10%of the number of parameters in the original networks, while incurring almost no decrease in rewards.
On the interaction between supervision and self-play in emergent communication
Feb 04, 2020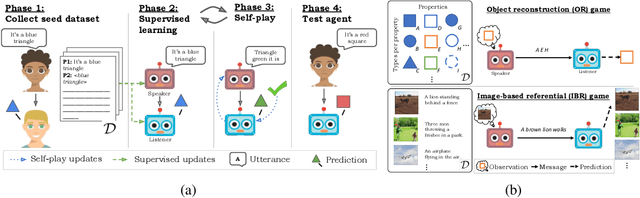
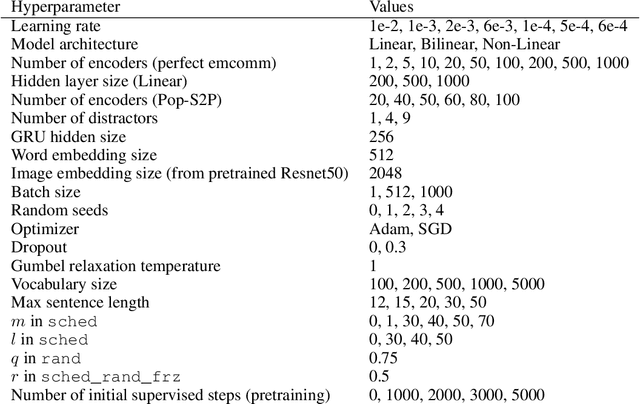
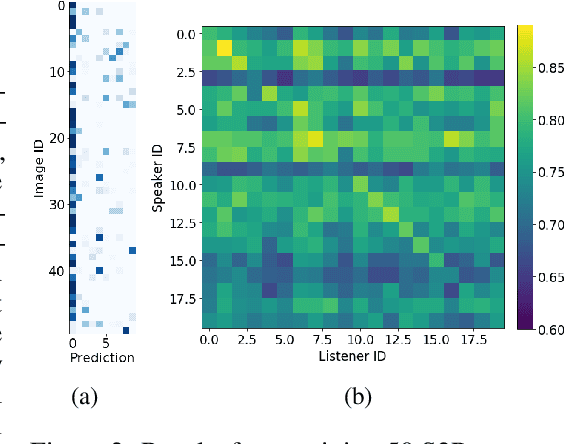
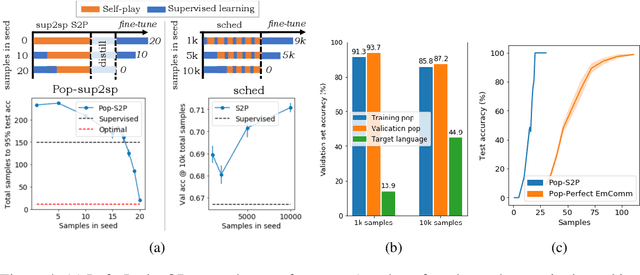
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.