 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Honesty via Confessions
Dec 22, 2025



Large language models (LLMs) can be dishonest when reporting on their actions and beliefs -- for example, they may overstate their confidence in factual claims or cover up evidence of covert actions. Such dishonesty may arise due to the effects of reinforcement learning (RL), where challenges with reward shaping can result in a training process that inadvertently incentivizes the model to lie or misrepresent its actions. In this work we propose a method for eliciting an honest expression of an LLM's shortcomings via a self-reported *confession*. A confession is an output, provided upon request after a model's original answer, that is meant to serve as a full account of the model's compliance with the letter and spirit of its policies and instructions. The reward assigned to a confession during training is solely based on its honesty, and does not impact positively or negatively the main answer's reward. As long as the "path of least resistance" for maximizing confession reward is to surface misbehavior rather than covering it up, this incentivizes models to be honest in their confessions. Our findings provide some justification this empirical assumption, especially in the case of egregious model misbehavior. To demonstrate the viability of our approach, we train GPT-5-Thinking to produce confessions, and we evaluate its honesty in out-of-distribution scenarios measuring hallucination, instruction following, scheming, and reward hacking. We find that when the model lies or omits shortcomings in its "main" answer, it often confesses to these behaviors honestly, and this confession honesty modestly improves with training. Confessions can enable a number of inference-time interventions including monitoring, rejection sampling, and surfacing issues to the user.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025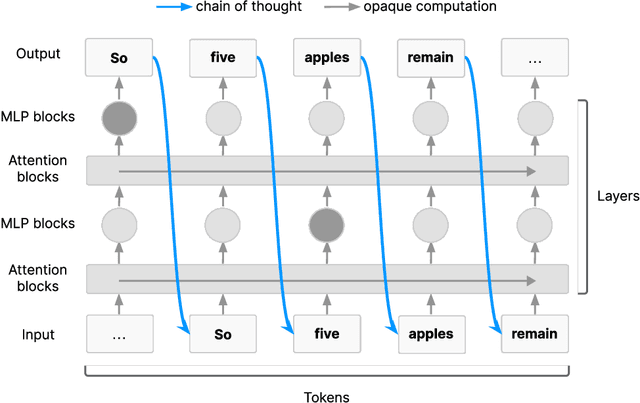
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Filling gaps in trustworthy development of AI
Dec 14, 2021The range of application of artificial intelligence (AI) is vast, as is the potential for harm. Growing awareness of potential risks from AI systems has spurred action to address those risks, while eroding confidence in AI systems and the organizations that develop them. A 2019 study found over 80 organizations that published and adopted "AI ethics principles'', and more have joined since. But the principles often leave a gap between the "what" and the "how" of trustworthy AI development. Such gaps have enabled questionable or ethically dubious behavior, which casts doubts on the trustworthiness of specific organizations, and the field more broadly. There is thus an urgent need for concrete methods that both enable AI developers to prevent harm and allow them to demonstrate their trustworthiness through verifiable behavior. Below, we explore mechanisms (drawn from arXiv:2004.07213) for creating an ecosystem where AI developers can earn trust - if they are trustworthy. Better assessment of developer trustworthiness could inform user choice, employee actions, investment decisions, legal recourse, and emerging governance regimes.
Learning an Unreferenced Metric for Online Dialogue Evaluation
May 01, 2020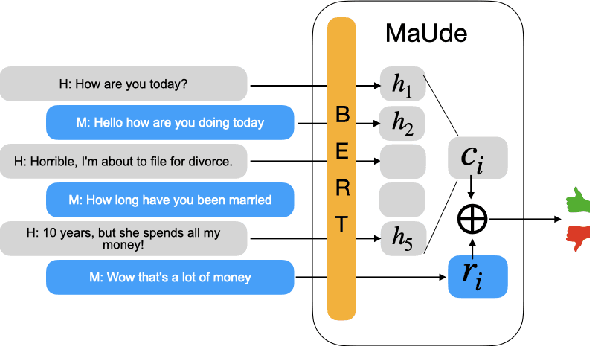
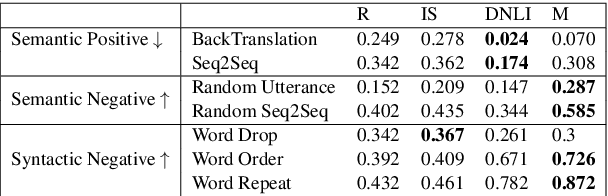
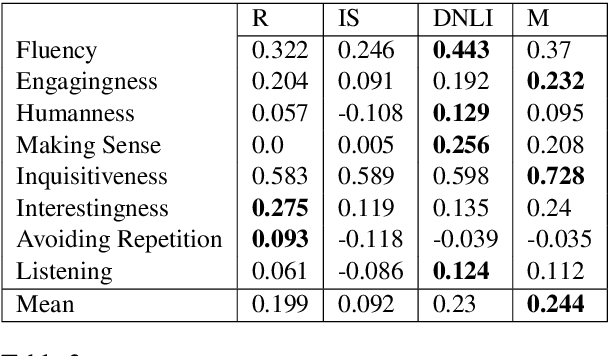
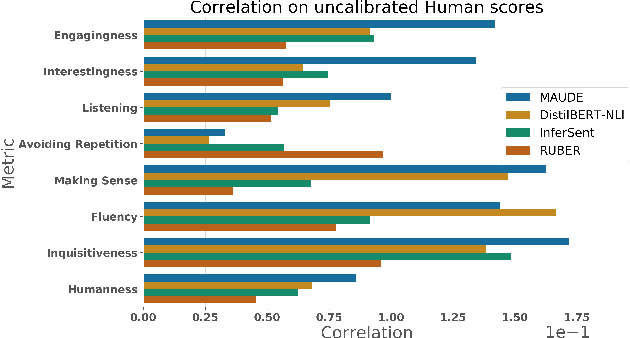
Evaluating the quality of a dialogue interaction between two agents is a difficult task, especially in open-domain chit-chat style dialogue. There have been recent efforts to develop automatic dialogue evaluation metrics, but most of them do not generalize to unseen datasets and/or need a human-generated reference response during inference, making it infeasible for online evaluation. Here, we propose an unreferenced automated evaluation metric that uses large pre-trained language models to extract latent representations of utterances, and leverages the temporal transitions that exist between them. We show that our model achieves higher correlation with human annotations in an online setting, while not requiring true responses for comparison during inference.
Release Strategies and the Social Impacts of Language Models
Aug 24, 2019Large language models have a range of beneficial uses: they can assist in prose, poetry, and programming; analyze dataset biases; and more. However, their flexibility and generative capabilities also raise misuse concerns. This report discusses OpenAI's work related to the release of its GPT-2 language model. It discusses staged release, which allows time between model releases to conduct risk and benefit analyses as model sizes increased. It also discusses ongoing partnership-based research and provides recommendations for better coordination and responsible publication in AI.