 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Single-shot Detector for Small Object Detection in Remote Sensing Images
May 12, 2022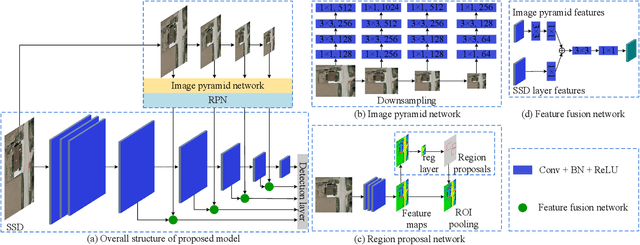

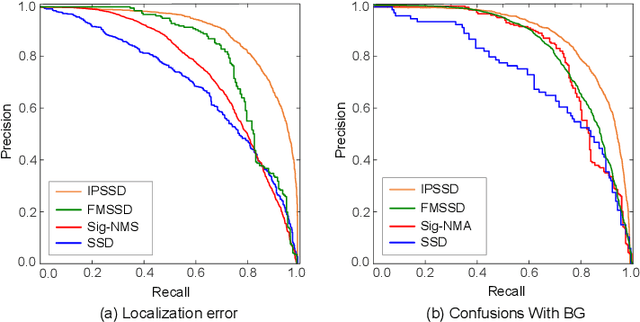
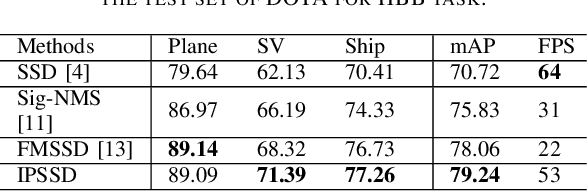
Small-object detection is a challenging problem. In the last few years, the convolution neural networks methods have been achieved considerable progress. However, the current detectors struggle with effective features extraction for small-scale objects. To address this challenge, we propose image pyramid single-shot detector (IPSSD). In IPSSD, single-shot detector is adopted combined with an image pyramid network to extract semantically strong features for generating candidate regions. The proposed network can enhance the small-scale features from a feature pyramid network. We evaluated the performance of the proposed model on two public datasets and the results show the superior performance of our model compared to the other state-of-the-art object detectors.
Decoupled-and-Coupled Networks: Self-Supervised Hyperspectral Image Super-Resolution with Subpixel Fusion
May 07, 2022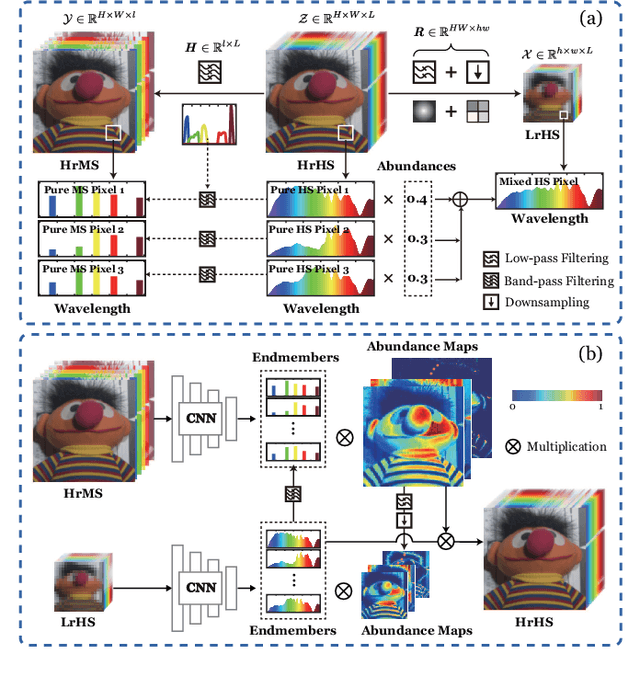
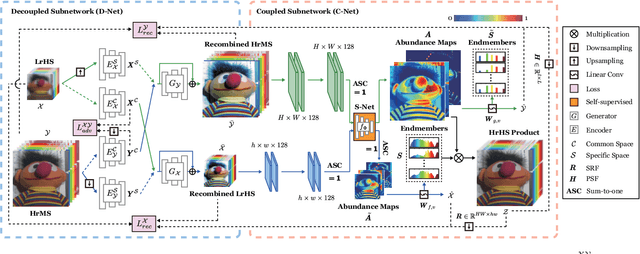
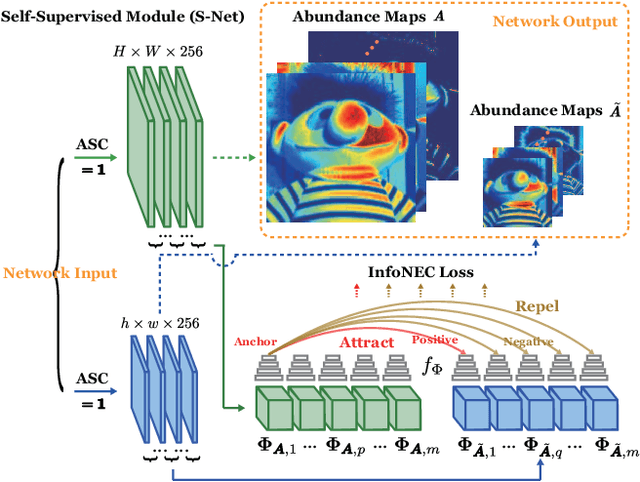
Enormous efforts have been recently made to super-resolve hyperspectral (HS) images with the aid of high spatial resolution multispectral (MS) images. Most prior works usually perform the fusion task by means of multifarious pixel-level priors. Yet the intrinsic effects of a large distribution gap between HS-MS data due to differences in the spatial and spectral resolution are less investigated. The gap might be caused by unknown sensor-specific properties or highly-mixed spectral information within one pixel (due to low spatial resolution). To this end, we propose a subpixel-level HS super-resolution framework by devising a novel decoupled-and-coupled network, called DC-Net, to progressively fuse HS-MS information from the pixel- to subpixel-level, from the image- to feature-level. As the name suggests, DC-Net first decouples the input into common (or cross-sensor) and sensor-specific components to eliminate the gap between HS-MS images before further fusion, and then fully blends them by a model-guided coupled spectral unmixing (CSU) net. More significantly, we append a self-supervised learning module behind the CSU net by guaranteeing the material consistency to enhance the detailed appearances of the restored HS product. Extensive experimental results show the superiority of our method both visually and quantitatively and achieve a significant improvement in comparison with the state-of-the-arts. Furthermore, the codes and datasets will be available at https://sites.google.com/view/danfeng-hong for the sake of reproducibility.
Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review
May 03, 2022
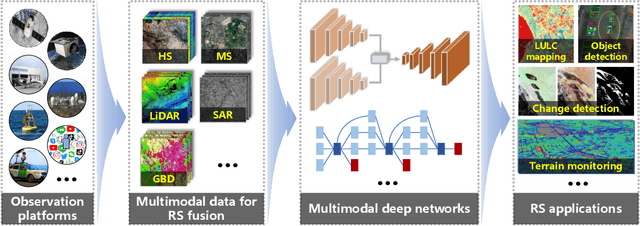
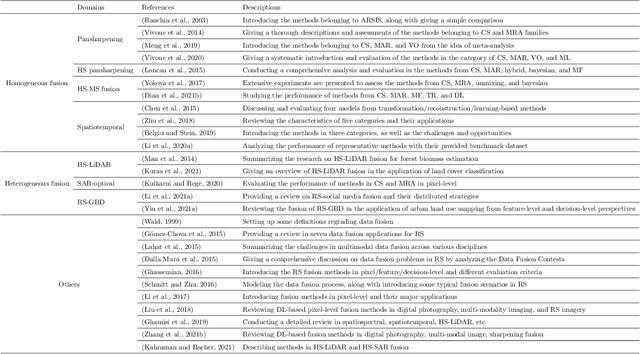
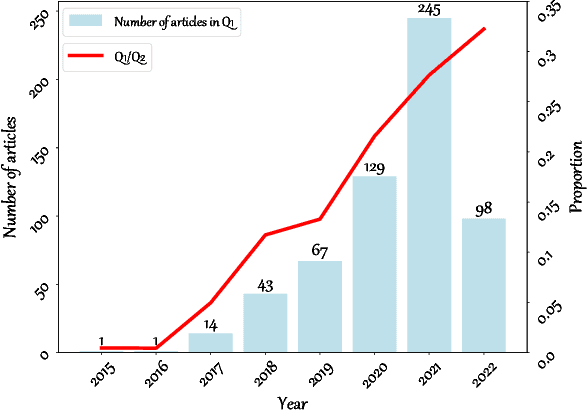
With the extremely rapid advances in remote sensing (RS) technology, a great quantity of Earth observation (EO) data featuring considerable and complicated heterogeneity is readily available nowadays, which renders researchers an opportunity to tackle current geoscience applications in a fresh way. With the joint utilization of EO data, much research on multimodal RS data fusion has made tremendous progress in recent years, yet these developed traditional algorithms inevitably meet the performance bottleneck due to the lack of the ability to comprehensively analyse and interpret these strongly heterogeneous data. Hence, this non-negligible limitation further arouses an intense demand for an alternative tool with powerful processing competence. Deep learning (DL), as a cutting-edge technology, has witnessed remarkable breakthroughs in numerous computer vision tasks owing to its impressive ability in data representation and reconstruction. Naturally, it has been successfully applied to the field of multimodal RS data fusion, yielding great improvement compared with traditional methods. This survey aims to present a systematic overview in DL-based multimodal RS data fusion. More specifically, some essential knowledge about this topic is first given. Subsequently, a literature survey is conducted to analyse the trends of this field. Some prevalent sub-fields in the multimodal RS data fusion are then reviewed in terms of the to-be-fused data modalities, i.e., spatiospectral, spatiotemporal, light detection and ranging-optical, synthetic aperture radar-optical, and RS-Geospatial Big Data fusion. Furthermore, We collect and summarize some valuable resources for the sake of the development in multimodal RS data fusion. Finally, the remaining challenges and potential future directions are highlighted.
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022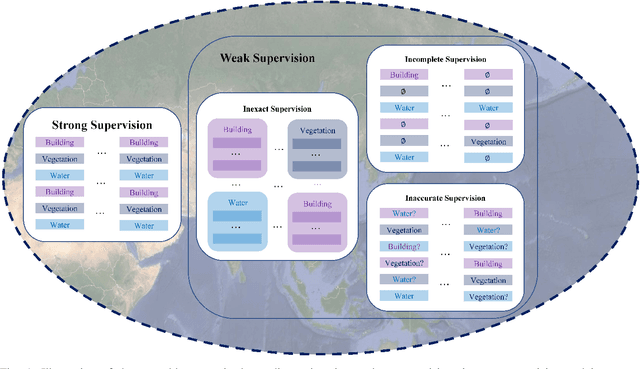
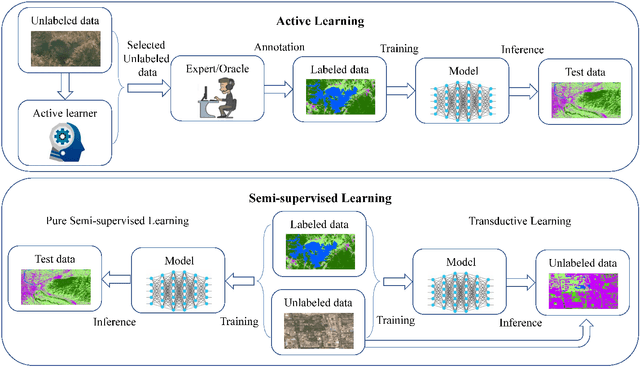
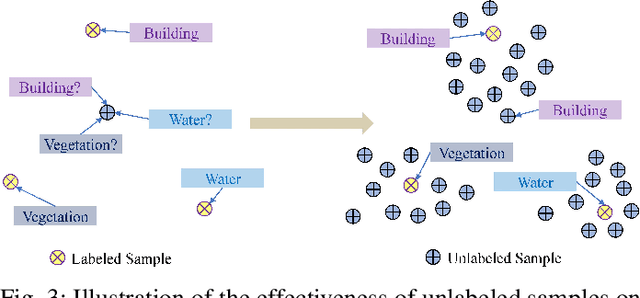

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.
Multimodal Fusion Transformer for Remote Sensing Image Classification
Mar 31, 2022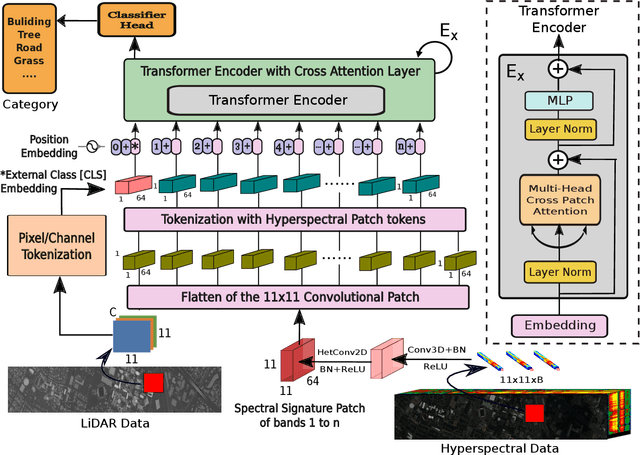


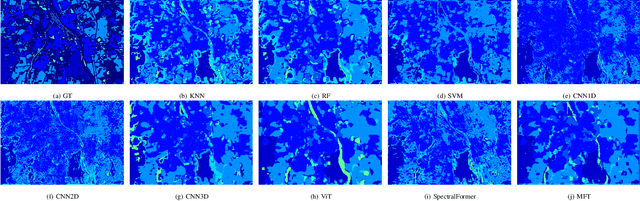
Vision transformer (ViT) has been trending in image classification tasks due to its promising performance when compared to convolutional neural networks (CNNs). As a result, many researchers have tried to incorporate ViT models in hyperspectral image (HSI) classification tasks, but without achieving satisfactory performance. To this paper, we introduce a new multimodal fusion transformer (MFT) network for HSI land-cover classification, which utilizes other sources of multimodal data in addition to HSI. Instead of using conventional feature fusion techniques, other multimodal data are used as an external classification (CLS) token in the transformer encoder, which helps achieving better generalization. ViT and other similar transformer models use a randomly initialized external classification token {and fail to generalize well}. However, the use of a feature embedding derived from other sources of multimodal data, such as light detection and ranging (LiDAR), offers the potential to improve those models by means of a CLS. The concept of tokenization is used in our work to generate CLS and HSI patch tokens, helping to learn key features in a reduced feature space. We also introduce a new attention mechanism for improving the exchange of information between HSI tokens and the CLS (e.g., LiDAR) token. Extensive experiments are carried out on widely used and benchmark datasets i.e., the University of Houston, Trento, University of Southern Mississippi Gulfpark (MUUFL), and Augsburg. In the results section, we compare the proposed MFT model with other state-of-the-art transformer models, classical CNN models, as well as conventional classifiers. The superior performance achieved by the proposed model is due to the use of multimodal information as external classification tokens.
A Triple-Double Convolutional Neural Network for Panchromatic Sharpening
Dec 04, 2021
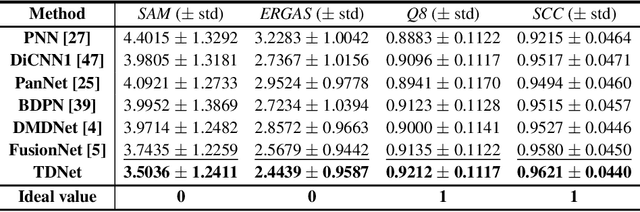
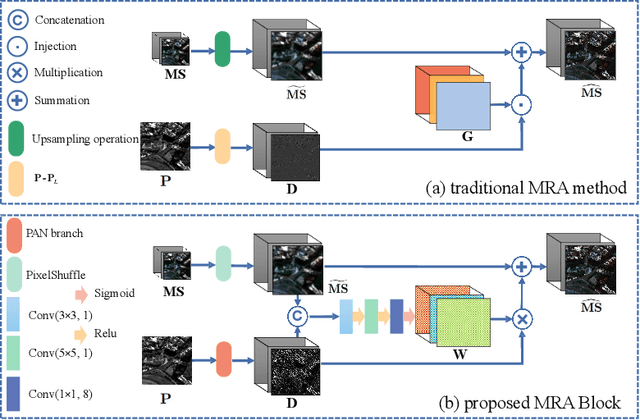
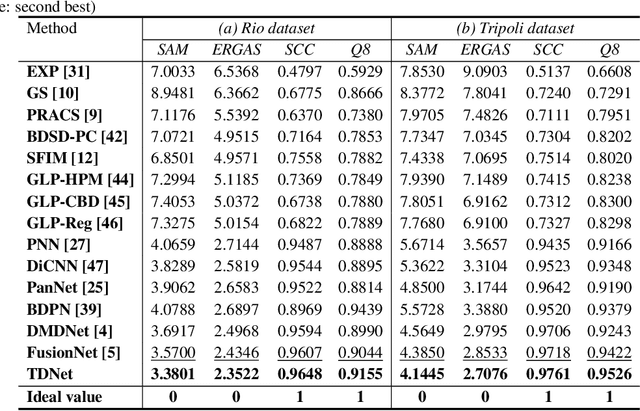
Pansharpening refers to the fusion of a panchromatic image with a high spatial resolution and a multispectral image with a low spatial resolution, aiming to obtain a high spatial resolution multispectral image. In this paper, we propose a novel deep neural network architecture with level-domain based loss function for pansharpening by taking into account the following double-type structures, \emph{i.e.,} double-level, double-branch, and double-direction, called as triple-double network (TDNet). By using the structure of TDNet, the spatial details of the panchromatic image can be fully exploited and utilized to progressively inject into the low spatial resolution multispectral image, thus yielding the high spatial resolution output. The specific network design is motivated by the physical formula of the traditional multi-resolution analysis (MRA) methods. Hence, an effective MRA fusion module is also integrated into the TDNet. Besides, we adopt a few ResNet blocks and some multi-scale convolution kernels to deepen and widen the network to effectively enhance the feature extraction and the robustness of the proposed TDNet. Extensive experiments on reduced- and full-resolution datasets acquired by WorldView-3, QuickBird, and GaoFen-2 sensors demonstrate the superiority of the proposed TDNet compared with some recent state-of-the-art pansharpening approaches. An ablation study has also corroborated the effectiveness of the proposed approach.
Geometric Multimodal Deep Learning with Multi-Scaled Graph Wavelet Convolutional Network
Nov 26, 2021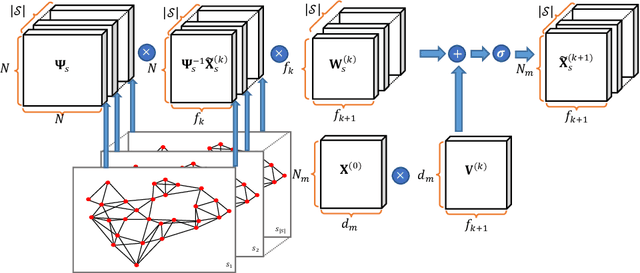
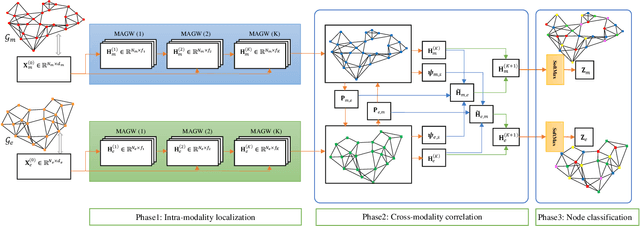
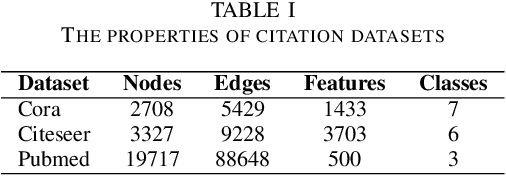

Multimodal data provide complementary information of a natural phenomenon by integrating data from various domains with very different statistical properties. Capturing the intra-modality and cross-modality information of multimodal data is the essential capability of multimodal learning methods. The geometry-aware data analysis approaches provide these capabilities by implicitly representing data in various modalities based on their geometric underlying structures. Also, in many applications, data are explicitly defined on an intrinsic geometric structure. Generalizing deep learning methods to the non-Euclidean domains is an emerging research field, which has recently been investigated in many studies. Most of those popular methods are developed for unimodal data. In this paper, a multimodal multi-scaled graph wavelet convolutional network (M-GWCN) is proposed as an end-to-end network. M-GWCN simultaneously finds intra-modality representation by applying the multiscale graph wavelet transform to provide helpful localization properties in the graph domain of each modality, and cross-modality representation by learning permutations that encode correlations among various modalities. M-GWCN is not limited to either the homogeneous modalities with the same number of data, or any prior knowledge indicating correspondences between modalities. Several semi-supervised node classification experiments have been conducted on three popular unimodal explicit graph-based datasets and five multimodal implicit ones. The experimental results indicate the superiority and effectiveness of the proposed methods compared with both spectral graph domain convolutional neural networks and state-of-the-art multimodal methods.
A Trainable Spectral-Spatial Sparse Coding Model for Hyperspectral Image Restoration
Nov 18, 2021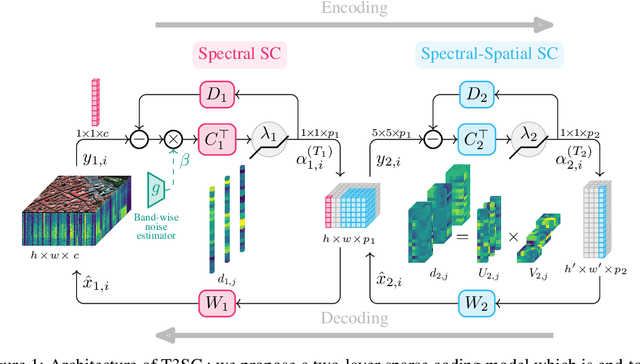

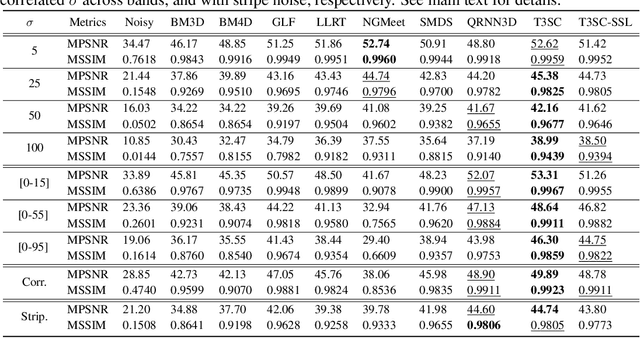

Hyperspectral imaging offers new perspectives for diverse applications, ranging from the monitoring of the environment using airborne or satellite remote sensing, precision farming, food safety, planetary exploration, or astrophysics. Unfortunately, the spectral diversity of information comes at the expense of various sources of degradation, and the lack of accurate ground-truth "clean" hyperspectral signals acquired on the spot makes restoration tasks challenging. In particular, training deep neural networks for restoration is difficult, in contrast to traditional RGB imaging problems where deep models tend to shine. In this paper, we advocate instead for a hybrid approach based on sparse coding principles that retains the interpretability of classical techniques encoding domain knowledge with handcrafted image priors, while allowing to train model parameters end-to-end without massive amounts of data. We show on various denoising benchmarks that our method is computationally efficient and significantly outperforms the state of the art.
Multi-patch Feature Pyramid Network for Weakly Supervised Object Detection in Optical Remote Sensing Images
Aug 18, 2021
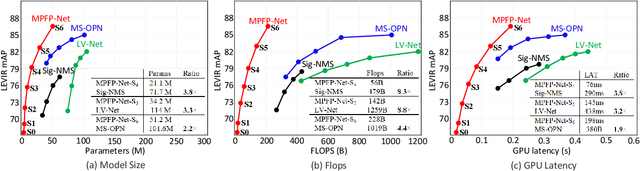
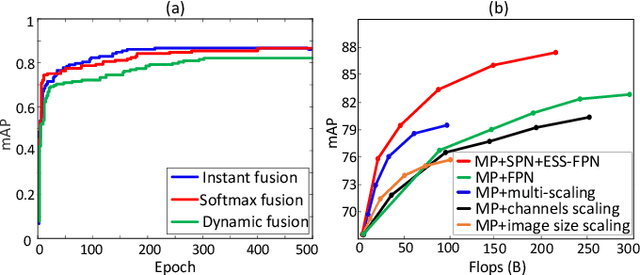
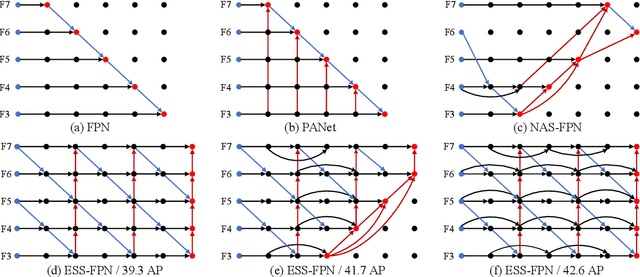
Object detection is a challenging task in remote sensing because objects only occupy a few pixels in the images, and the models are required to simultaneously learn object locations and detection. Even though the established approaches well perform for the objects of regular sizes, they achieve weak performance when analyzing small ones or getting stuck in the local minima (e.g. false object parts). Two possible issues stand in their way. First, the existing methods struggle to perform stably on the detection of small objects because of the complicated background. Second, most of the standard methods used hand-crafted features, and do not work well on the detection of objects parts of which are missing. We here address the above issues and propose a new architecture with a multiple patch feature pyramid network (MPFP-Net). Different from the current models that during training only pursue the most discriminative patches, in MPFPNet the patches are divided into class-affiliated subsets, in which the patches are related and based on the primary loss function, a sequence of smooth loss functions are determined for the subsets to improve the model for collecting small object parts. To enhance the feature representation for patch selection, we introduce an effective method to regularize the residual values and make the fusion transition layers strictly norm-preserving. The network contains bottom-up and crosswise connections to fuse the features of different scales to achieve better accuracy, compared to several state-of-the-art object detection models. Also, the developed architecture is more efficient than the baselines.
Unsupervised Outlier Detection using Memory and Contrastive Learning
Jul 27, 2021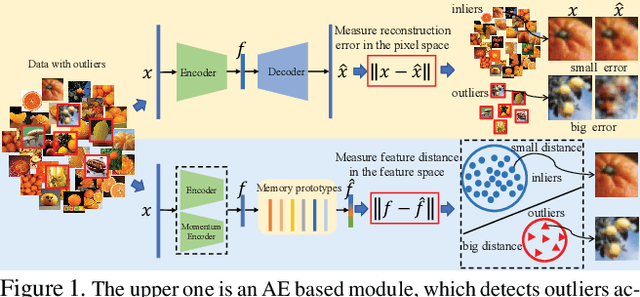
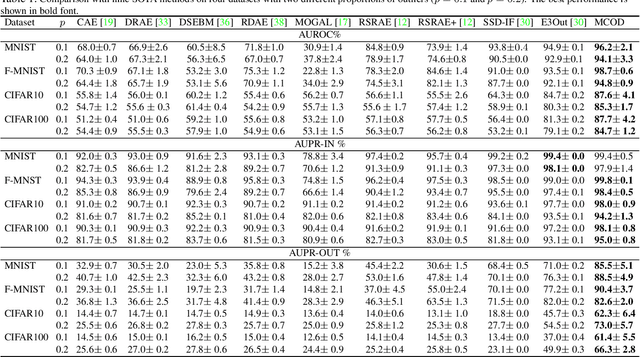
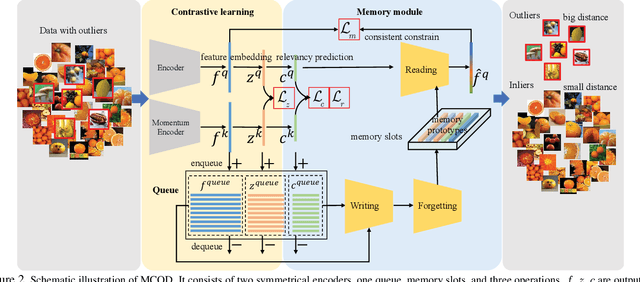
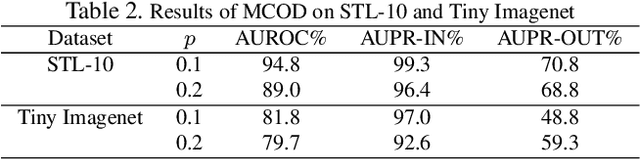
Outlier detection is one of the most important processes taken to create good, reliable data in machine learning. The most methods of outlier detection leverage an auxiliary reconstruction task by assuming that outliers are more difficult to be recovered than normal samples (inliers). However, it is not always true, especially for auto-encoder (AE) based models. They may recover certain outliers even outliers are not in the training data, because they do not constrain the feature learning. Instead, we think outlier detection can be done in the feature space by measuring the feature distance between outliers and inliers. We then propose a framework, MCOD, using a memory module and a contrastive learning module. The memory module constrains the consistency of features, which represent the normal data. The contrastive learning module learns more discriminating features, which boosts the distinction between outliers and inliers. Extensive experiments on four benchmark datasets show that our proposed MCOD achieves a considerable performance and outperforms nine state-of-the-art methods.