 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Aug 06, 2025
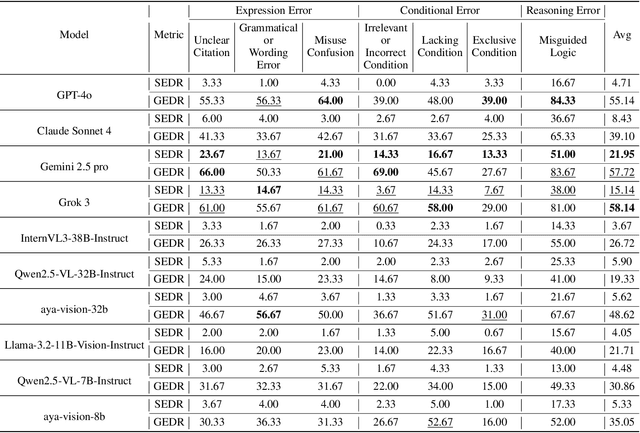
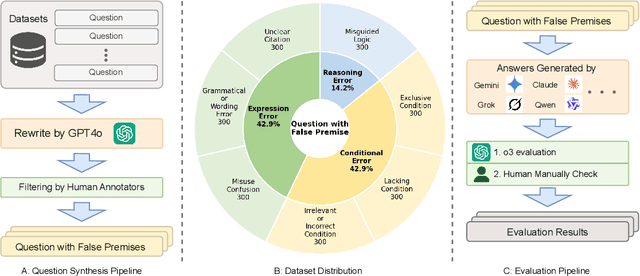
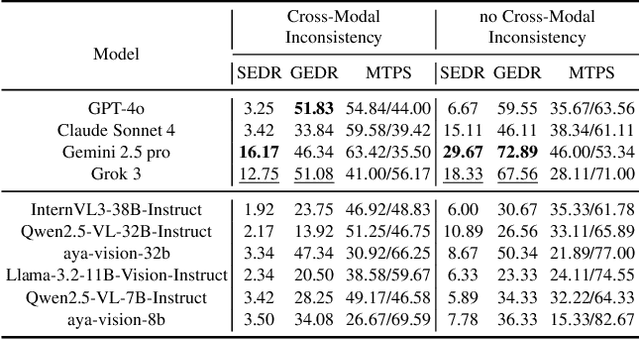
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at https://github.com/MLGroupJLU/LMM_ISEval.
Don't Take the Premise for Granted: Evaluating the Premise Critique Ability of Large Language Models
May 29, 2025Large language models (LLMs) have witnessed rapid advancements, demonstrating remarkable capabilities. However, a notable vulnerability persists: LLMs often uncritically accept flawed or contradictory premises, leading to inefficient reasoning and unreliable outputs. This emphasizes the significance of possessing the \textbf{Premise Critique Ability} for LLMs, defined as the capacity to proactively identify and articulate errors in input premises. Most existing studies assess LLMs' reasoning ability in ideal settings, largely ignoring their vulnerabilities when faced with flawed premises. Thus, we introduce the \textbf{Premise Critique Bench (PCBench)}, designed by incorporating four error types across three difficulty levels, paired with multi-faceted evaluation metrics. We conducted systematic evaluations of 15 representative LLMs. Our findings reveal: (1) Most models rely heavily on explicit prompts to detect errors, with limited autonomous critique; (2) Premise critique ability depends on question difficulty and error type, with direct contradictions being easier to detect than complex or procedural errors; (3) Reasoning ability does not consistently correlate with the premise critique ability; (4) Flawed premises trigger overthinking in reasoning models, markedly lengthening responses due to repeated attempts at resolving conflicts. These insights underscore the urgent need to enhance LLMs' proactive evaluation of input validity, positioning premise critique as a foundational capability for developing reliable, human-centric systems. The code is available at https://github.com/MLGroupJLU/Premise_Critique.
GraphGen: Enhancing Supervised Fine-Tuning for LLMs with Knowledge-Driven Synthetic Data Generation
May 26, 2025Fine-tuning for large language models (LLMs) typically requires substantial amounts of high-quality supervised data, which is both costly and labor-intensive to acquire. While synthetic data generation has emerged as a promising solution, existing approaches frequently suffer from factual inaccuracies, insufficient long-tail coverage, simplistic knowledge structures, and homogenized outputs. To address these challenges, we introduce GraphGen, a knowledge graph-guided framework designed for three key question-answering (QA) scenarios: atomic QA, aggregated QA, and multi-hop QA. It begins by constructing a fine-grained knowledge graph from the source text. It then identifies knowledge gaps in LLMs using the expected calibration error metric, prioritizing the generation of QA pairs that target high-value, long-tail knowledge. Furthermore, GraphGen incorporates multi-hop neighborhood sampling to capture complex relational information and employs style-controlled generation to diversify the resulting QA data. Experimental results on knowledge-intensive tasks under closed-book settings demonstrate that GraphGen outperforms conventional synthetic data methods, offering a more reliable and comprehensive solution to the data scarcity challenge in supervised fine-tuning. The code and data are publicly available at https://github.com/open-sciencelab/GraphGen.
JurisCTC: Enhancing Legal Judgment Prediction via Cross-Domain Transfer and Contrastive Learning
Apr 24, 2025In recent years, Unsupervised Domain Adaptation (UDA) has gained significant attention in the field of Natural Language Processing (NLP) owing to its ability to enhance model generalization across diverse domains. However, its application for knowledge transfer between distinct legal domains remains largely unexplored. To address the challenges posed by lengthy and complex legal texts and the limited availability of large-scale annotated datasets, we propose JurisCTC, a novel model designed to improve the accuracy of Legal Judgment Prediction (LJP) tasks. Unlike existing approaches, JurisCTC facilitates effective knowledge transfer across various legal domains and employs contrastive learning to distinguish samples from different domains. Specifically, for the LJP task, we enable knowledge transfer between civil and criminal law domains. Compared to other models and specific large language models (LLMs), JurisCTC demonstrates notable advancements, achieving peak accuracies of 76.59% and 78.83%, respectively.
AlignRAG: An Adaptable Framework for Resolving Misalignments in Retrieval-Aware Reasoning of RAG
Apr 21, 2025Retrieval-augmented generation (RAG) has emerged as a foundational paradigm for knowledge-grounded text generation. However, existing RAG pipelines often fail to ensure that the reasoning trajectories align with the evidential constraints imposed by retrieved content. In this paper, we reframe RAG as a problem of retrieval-aware reasoning and identify a core challenge: reasoning misalignment-the mismatch between a model's reasoning trajectory and the retrieved evidence. To address this challenge, we propose AlignRAG, a novel test-time framework that mitigates reasoning misalignment through iterative Critique-Driven Alignment (CDA) steps. In contrast to prior approaches that rely on static training or post-hoc selection, AlignRAG actively refines reasoning trajectories during inference by enforcing fine-grained alignment with evidence. Our framework introduces a new paradigm for retrieval-aware reasoning by: (1) constructing context-rich training corpora; (2) generating contrastive critiques from preference-aware reasoning trajectories; (3) training a dedicated \textit{Critic Language Model (CLM)} to identify reasoning misalignments; and (4) applying CDA steps to optimize reasoning trajectories iteratively. Empirical results demonstrate that AlignRAG consistently outperforms all baselines and could integrate as a plug-and-play module into existing RAG pipelines without further changes. By reconceptualizing RAG as a structured reasoning trajectory and establishing the test-time framework for correcting reasoning misalignments in RAG, AlignRAG provides practical advancements for retrieval-aware generation.
StructFlowBench: A Structured Flow Benchmark for Multi-turn Instruction Following
Feb 20, 2025



Multi-turn instruction following capability constitutes a core competency of large language models (LLMs) in real-world applications. Existing evaluation benchmarks predominantly focus on fine-grained constraint satisfaction and domain-specific capability assessment, yet overlook the crucial structural dependency between dialogue turns that distinguishes multi-turn from single-turn interactions. This structural dependency not only reflects user intent but also establishes a second dimension for instruction following evaluation beyond constraint satisfaction. To address this gap, we propose StructFlowBench, a multi-turn instruction following benchmark with structural flow modeling. The benchmark innovatively defines a structural flow framework comprising six fundamental inter-turn relationships, which not only introduces novel structural constraints for model evaluation but also serves as generation parameters for creating customized dialogue flows tailored to specific scenarios. Adopting established LLM-based automatic evaluation methodologies, we conduct systematic evaluations of 13 leading open-source and closed-source LLMs. Experimental results reveal significant deficiencies in current models' comprehension of multi-turn dialogue structures. The code is available at \url{https://github.com/MLGroupJLU/StructFlowBench}.
Towards Efficient and Intelligent Laser Weeding: Method and Dataset for Weed Stem Detection
Feb 10, 2025



Weed control is a critical challenge in modern agriculture, as weeds compete with crops for essential nutrient resources, significantly reducing crop yield and quality. Traditional weed control methods, including chemical and mechanical approaches, have real-life limitations such as associated environmental impact and efficiency. An emerging yet effective approach is laser weeding, which uses a laser beam as the stem cutter. Although there have been studies that use deep learning in weed recognition, its application in intelligent laser weeding still requires a comprehensive understanding. Thus, this study represents the first empirical investigation of weed recognition for laser weeding. To increase the efficiency of laser beam cut and avoid damaging the crops of interest, the laser beam shall be directly aimed at the weed root. Yet, weed stem detection remains an under-explored problem. We integrate the detection of crop and weed with the localization of weed stem into one end-to-end system. To train and validate the proposed system in a real-life scenario, we curate and construct a high-quality weed stem detection dataset with human annotations. The dataset consists of 7,161 high-resolution pictures collected in the field with annotations of 11,151 instances of weed. Experimental results show that the proposed system improves weeding accuracy by 6.7% and reduces energy cost by 32.3% compared to existing weed recognition systems.