 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak Stylistic Sophon: Are We Really Meant to Confine the Imagination in Style Transfer?
Jun 18, 2025In this pioneering study, we introduce StyleWallfacer, a groundbreaking unified training and inference framework, which not only addresses various issues encountered in the style transfer process of traditional methods but also unifies the framework for different tasks. This framework is designed to revolutionize the field by enabling artist level style transfer and text driven stylization. First, we propose a semantic-based style injection method that uses BLIP to generate text descriptions strictly aligned with the semantics of the style image in CLIP space. By leveraging a large language model to remove style-related descriptions from these descriptions, we create a semantic gap. This gap is then used to fine-tune the model, enabling efficient and drift-free injection of style knowledge. Second, we propose a data augmentation strategy based on human feedback, incorporating high-quality samples generated early in the fine-tuning process into the training set to facilitate progressive learning and significantly reduce its overfitting. Finally, we design a training-free triple diffusion process using the fine-tuned model, which manipulates the features of self-attention layers in a manner similar to the cross-attention mechanism. Specifically, in the generation process, the key and value of the content-related process are replaced with those of the style-related process to inject style while maintaining text control over the model. We also introduce query preservation to mitigate disruptions to the original content. Under such a design, we have achieved high-quality image-driven style transfer and text-driven stylization, delivering artist-level style transfer results while preserving the original image content. Moreover, we achieve image color editing during the style transfer process for the first time.
BroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
May 25, 2025In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.3 billion items.
GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
Sep 05, 2024



Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
Graphite: A Graph-based Extreme Multi-Label Short Text Classifier for Keyphrase Recommendation
Jul 29, 2024



Keyphrase Recommendation has been a pivotal problem in advertising and e-commerce where advertisers/sellers are recommended keyphrases (search queries) to bid on to increase their sales. It is a challenging task due to the plethora of items shown on online platforms and various possible queries that users search while showing varying interest in the displayed items. Moreover, query/keyphrase recommendations need to be made in real-time and in a resource-constrained environment. This problem can be framed as an Extreme Multi-label (XML) Short text classification by tagging the input text with keywords as labels. Traditional neural network models are either infeasible or have slower inference latency due to large label spaces. We present Graphite, a graph-based classifier model that provides real-time keyphrase recommendations that are on par with standard text classification models. Furthermore, it doesn't utilize GPU resources, which can be limited in production environments. Due to its lightweight nature and smaller footprint, it can train on very large datasets, where state-of-the-art XML models fail due to extreme resource requirements. Graphite is deterministic, transparent, and intrinsically more interpretable than neural network-based models. We present a comprehensive analysis of our model's performance across forty categories spanning eBay's English-speaking sites.
Polarimetric PatchMatch Multi-View Stereo
Nov 11, 2023



PatchMatch Multi-View Stereo (PatchMatch MVS) is one of the popular MVS approaches, owing to its balanced accuracy and efficiency. In this paper, we propose Polarimetric PatchMatch multi-view Stereo (PolarPMS), which is the first method exploiting polarization cues to PatchMatch MVS. The key of PatchMatch MVS is to generate depth and normal hypotheses, which form local 3D planes and slanted stereo matching windows, and efficiently search for the best hypothesis based on the consistency among multi-view images. In addition to standard photometric consistency, our PolarPMS evaluates polarimetric consistency to assess the validness of a depth and normal hypothesis, motivated by the physical property that the polarimetric information is related to the object's surface normal. Experimental results demonstrate that our PolarPMS can improve the accuracy and the completeness of reconstructed 3D models, especially for texture-less surfaces, compared with state-of-the-art PatchMatch MVS methods.
Polarimetric Multi-View Inverse Rendering
Dec 24, 2022



A polarization camera has great potential for 3D reconstruction since the angle of polarization (AoP) and the degree of polarization (DoP) of reflected light are related to an object's surface normal. In this paper, we propose a novel 3D reconstruction method called Polarimetric Multi-View Inverse Rendering (Polarimetric MVIR) that effectively exploits geometric, photometric, and polarimetric cues extracted from input multi-view color-polarization images. We first estimate camera poses and an initial 3D model by geometric reconstruction with a standard structure-from-motion and multi-view stereo pipeline. We then refine the initial model by optimizing photometric rendering errors and polarimetric errors using multi-view RGB, AoP, and DoP images, where we propose a novel polarimetric cost function that enables an effective constraint on the estimated surface normal of each vertex, while considering four possible ambiguous azimuth angles revealed from the AoP measurement. The weight for the polarimetric cost is effectively determined based on the DoP measurement, which is regarded as the reliability of polarimetric information. Experimental results using both synthetic and real data demonstrate that our Polarimetric MVIR can reconstruct a detailed 3D shape without assuming a specific surface material and lighting condition.
A new method incorporating deep learning with shape priors for left ventricular segmentation in myocardial perfusion SPECT images
Jun 07, 2022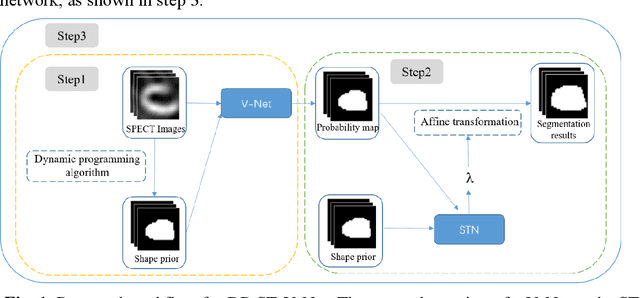


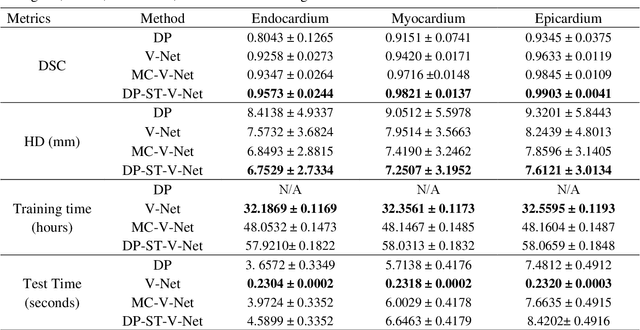
Background: The assessment of left ventricular (LV) function by myocardial perfusion SPECT (MPS) relies on accurate myocardial segmentation. The purpose of this paper is to develop and validate a new method incorporating deep learning with shape priors to accurately extract the LV myocardium for automatic measurement of LV functional parameters. Methods: A segmentation architecture that integrates a three-dimensional (3D) V-Net with a shape deformation module was developed. Using the shape priors generated by a dynamic programming (DP) algorithm, the model output was then constrained and guided during the model training for quick convergence and improved performance. A stratified 5-fold cross-validation was used to train and validate our models. Results: Results of our proposed method agree well with those from the ground truth. Our proposed model achieved a Dice similarity coefficient (DSC) of 0.9573(0.0244), 0.9821(0.0137), and 0.9903(0.0041), a Hausdorff distances (HD) of 6.7529(2.7334) mm, 7.2507(3.1952) mm, and 7.6121(3.0134) mm in extracting the endocardium, myocardium, and epicardium, respectively. Conclusion: Our proposed method achieved a high accuracy in extracting LV myocardial contours and assessing LV function.
Unsupervised Embedding of Hierarchical Structure in Euclidean Space
Oct 30, 2020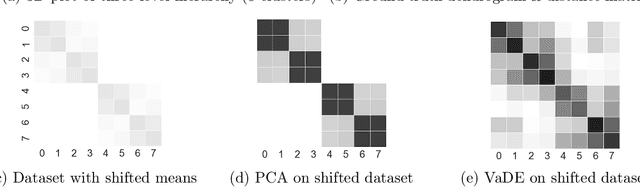


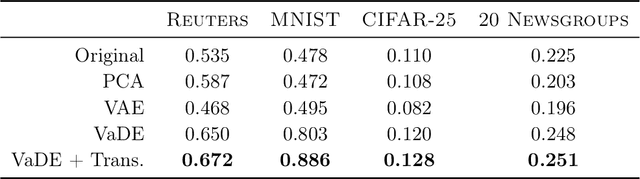
Deep embedding methods have influenced many areas of unsupervised learning. However, the best methods for learning hierarchical structure use non-Euclidean representations, whereas Euclidean geometry underlies the theory behind many hierarchical clustering algorithms. To bridge the gap between these two areas, we consider learning a non-linear embedding of data into Euclidean space as a way to improve the hierarchical clustering produced by agglomerative algorithms. To learn the embedding, we revisit using a variational autoencoder with a Gaussian mixture prior, and we show that rescaling the latent space embedding and then applying Ward's linkage-based algorithm leads to improved results for both dendrogram purity and the Moseley-Wang cost function. Finally, we complement our empirical results with a theoretical explanation of the success of this approach. We study a synthetic model of the embedded vectors and prove that Ward's method exactly recovers the planted hierarchical clustering with high probability.
COVID-CT-Dataset: A CT Scan Dataset about COVID-19
Mar 30, 2020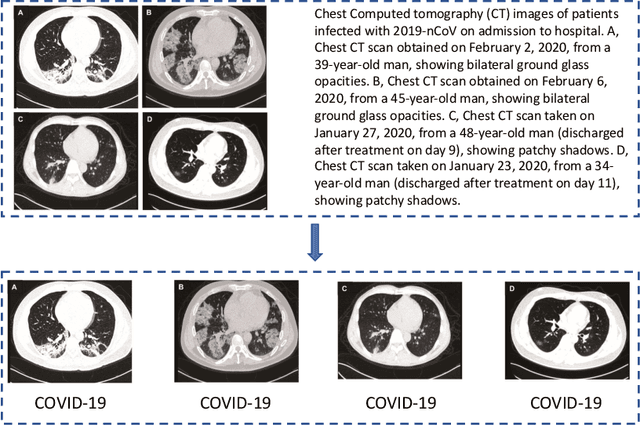
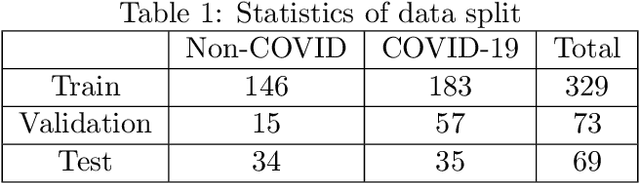
CT scans are promising in providing accurate, fast, and cheap screening and testing of COVID-19. In this paper, we build a publicly available COVID-CT dataset, containing 275 CT scans that are positive for COVID-19, to foster the research and development of deep learning methods which predict whether a person is affected with COVID-19 by analyzing his/her CTs. We train a deep convolutional neural network on this dataset and achieve an F1 of 0.85 which is a promising performance but yet to be further improved. The data and code are available at https://github.com/UCSD-AI4H/COVID-CT
Melodic Phrase Segmentation By Deep Neural Networks
Nov 14, 2018
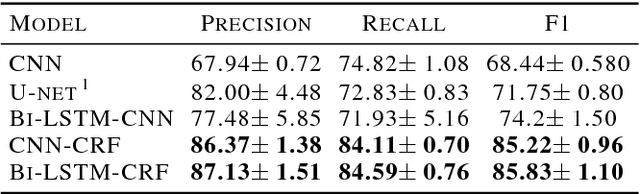
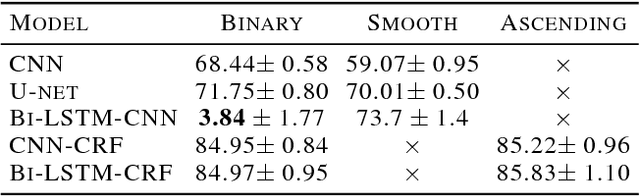
Automated melodic phrase detection and segmentation is a classical task in content-based music information retrieval and also the key towards automated music structure analysis. However, traditional methods still cannot satisfy practical requirements. In this paper, we explore and adapt various neural network architectures to see if they can be generalized to work with the symbolic representation of music and produce satisfactory melodic phrase segmentation. The main issue of applying deep-learning methods to phrase detection is the sparse labeling problem of training sets. We proposed two tailored label engineering with corresponding training techniques for different neural networks in order to make decisions at a sequential level. Experiment results show that the CNN-CRF architecture performs the best, being able to offer finer segmentation and faster to train, while CNN, Bi-LSTM-CNN and Bi-LSTM-CRF are acceptable alternatives.