 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsID-Gen: View-Consistent and Identity-Preserving Image-to-Video Generation
Feb 10, 2026Image-to-Video generation (I2V) animates a static image into a temporally coherent video sequence following textual instructions, yet preserving fine-grained object identity under changing viewpoints remains a persistent challenge. Unlike text-to-video models, existing I2V pipelines often suffer from appearance drift and geometric distortion, artifacts we attribute to the sparsity of single-view 2D observations and weak cross-modal alignment. Here we address this problem from both data and model perspectives. First, we curate ConsIDVid, a large-scale object-centric dataset built with a scalable pipeline for high-quality, temporally aligned videos, and establish ConsIDVid-Bench, where we present a novel benchmarking and evaluation framework for multi-view consistency using metrics sensitive to subtle geometric and appearance deviations. We further propose ConsID-Gen, a view-assisted I2V generation framework that augments the first frame with unposed auxiliary views and fuses semantic and structural cues via a dual-stream visual-geometric encoder as well as a text-visual connector, yielding unified conditioning for a Diffusion Transformer backbone. Experiments across ConsIDVid-Bench demonstrate that ConsID-Gen consistently outperforms in multiple metrics, with the best overall performance surpassing leading video generation models like Wan2.1 and HunyuanVideo, delivering superior identity fidelity and temporal coherence under challenging real-world scenarios. We will release our model and dataset at https://myangwu.github.io/ConsID-Gen.
Batch Speculative Decoding Done Right
Oct 26, 2025



Speculative decoding speeds up LLM inference by using a small draft model to propose multiple tokens that a target model verifies in parallel. Extending this idea to batches is essential for production serving, but it introduces the ragged tensor problem: sequences in the same batch accept different numbers of draft tokens, breaking right-alignment and corrupting position IDs, attention masks, and KV-cache state. We show that several existing batch implementations violate output equivalence-the fundamental requirement that speculative decoding must produce identical token sequences to standard autoregressive generation. These violations occur precisely due to improper handling of the ragged tensor problem. In response, we (1) characterize the synchronization requirements that guarantee correctness, (2) present a correctness-first batch speculative decoding EQSPEC that exposes realignment as consuming 40% of overhead, and (3) introduce EXSPEC, which maintains a sliding pool of sequences and dynamically forms same-length groups, to reduce the realignment overhead while preserving per-sequence speculative speedups. On the SpecBench dataset, across Vicuna-7B/68M, Qwen3-8B/0.6B, and GLM-4-9B/0.6B target/draft pairs, our approach achieves up to 3$\times$ throughput improvement at batch size 8 compared to batch size 1, with efficient scaling through batch size 8, while maintaining 95% output equivalence. Our method requires no custom kernels and integrates cleanly with existing inference stacks. Our code is available at https://github.com/eBay/spec_dec.
BroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
May 25, 2025



In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.3 billion items.
To Judge or not to Judge: Using LLM Judgements for Advertiser Keyphrase Relevance at eBay
May 07, 2025



E-commerce sellers are recommended keyphrases based on their inventory on which they advertise to increase buyer engagement (clicks/sales). The relevance of advertiser keyphrases plays an important role in preventing the inundation of search systems with numerous irrelevant items that compete for attention in auctions, in addition to maintaining a healthy seller perception. In this work, we describe the shortcomings of training Advertiser keyphrase relevance filter models on click/sales/search relevance signals and the importance of aligning with human judgment, as sellers have the power to adopt or reject said keyphrase recommendations. In this study, we frame Advertiser keyphrase relevance as a complex interaction between 3 dynamical systems -- seller judgment, which influences seller adoption of our product, Advertising, which provides the keyphrases to bid on, and Search, who holds the auctions for the same keyphrases. This study discusses the practicalities of using human judgment via a case study at eBay Advertising and demonstrate that using LLM-as-a-judge en-masse as a scalable proxy for seller judgment to train our relevance models achieves a better harmony across the three systems -- provided that they are bound by a meticulous evaluation framework grounded in business metrics.
From Lazy to Prolific: Tackling Missing Labels in Open Vocabulary Extreme Classification by Positive-Unlabeled Sequence Learning
Aug 22, 2024



Open-vocabulary Extreme Multi-label Classification (OXMC) extends traditional XMC by allowing prediction beyond an extremely large, predefined label set (typically $10^3$ to $10^{12}$ labels), addressing the dynamic nature of real-world labeling tasks. However, self-selection bias in data annotation leads to significant missing labels in both training and test data, particularly for less popular inputs. This creates two critical challenges: generation models learn to be "lazy'" by under-generating labels, and evaluation becomes unreliable due to insufficient annotation in the test set. In this work, we introduce Positive-Unlabeled Sequence Learning (PUSL), which reframes OXMC as an infinite keyphrase generation task, addressing the generation model's laziness. Additionally, we propose to adopt a suite of evaluation metrics, F1@$\mathcal{O}$ and newly proposed B@$k$, to reliably assess OXMC models with incomplete ground truths. In a highly imbalanced e-commerce dataset with substantial missing labels, PUSL generates 30% more unique labels, and 72% of its predictions align with actual user queries. On the less skewed EURLex-4.3k dataset, PUSL demonstrates superior F1 scores, especially as label counts increase from 15 to 30. Our approach effectively tackles both the modeling and evaluation challenges in OXMC with missing labels.
Human Mobility Prediction with Causal and Spatial-constrained Multi-task Network
Jun 12, 2022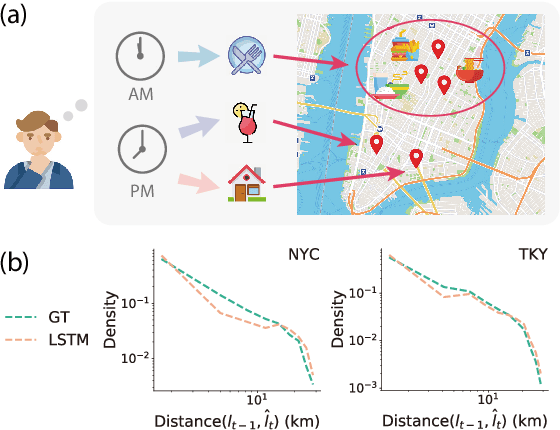
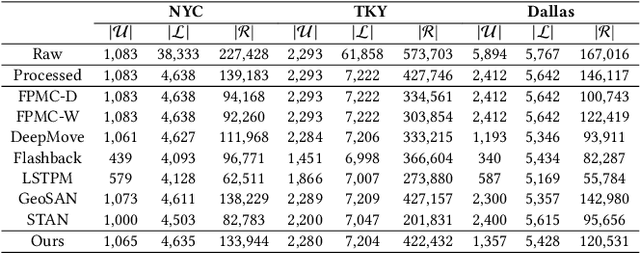
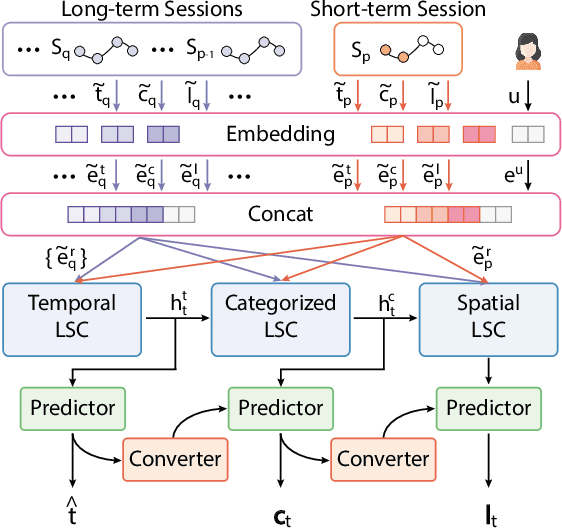
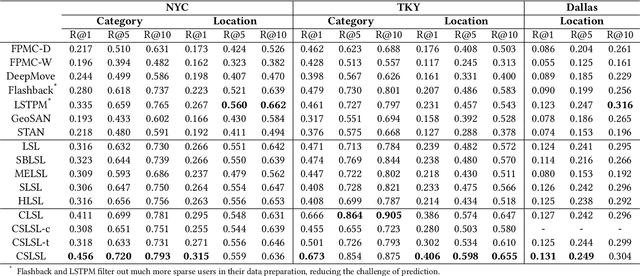
Modeling human mobility helps to understand how people are accessing resources and physically contacting with each other in cities, and thus contributes to various applications such as urban planning, epidemic control, and location-based advertisement. Next location prediction is one decisive task in individual human mobility modeling and is usually viewed as sequence modeling, solved with Markov or RNN-based methods. However, the existing models paid little attention to the logic of individual travel decisions and the reproducibility of the collective behavior of population. To this end, we propose a Causal and Spatial-constrained Long and Short-term Learner (CSLSL) for next location prediction. CSLSL utilizes a causal structure based on multi-task learning to explicitly model the "when$\rightarrow$what$\rightarrow$where", a.k.a. "time$\rightarrow$activity$\rightarrow$location" decision logic. We next propose a spatial-constrained loss function as an auxiliary task, to ensure the consistency between the predicted and actual spatial distribution of travelers' destinations. Moreover, CSLSL adopts modules named Long and Short-term Capturer (LSC) to learn the transition regularities across different time spans. Extensive experiments on three real-world datasets show a 33.4% performance improvement of CSLSL over baselines and confirm the effectiveness of introducing the causality and consistency constraints. The implementation is available at https://github.com/urbanmobility/CSLSL.