 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Sparse Implicit Neural Representations
Nov 07, 2021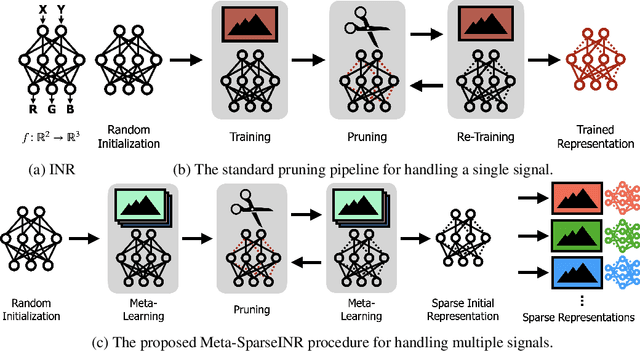

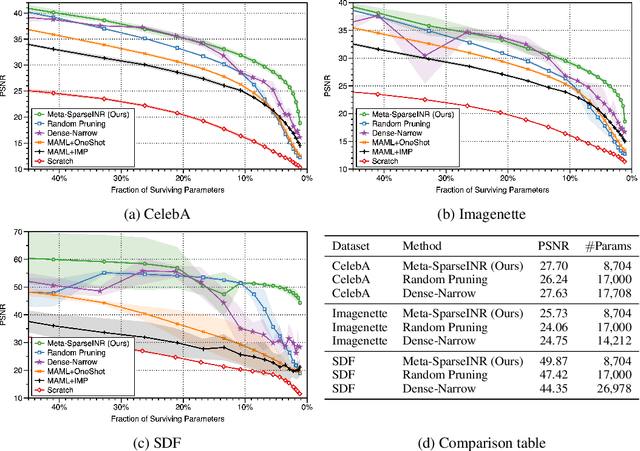
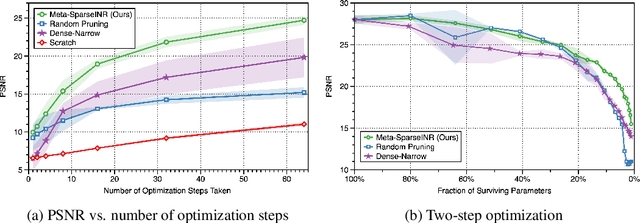
Implicit neural representations are a promising new avenue of representing general signals by learning a continuous function that, parameterized as a neural network, maps the domain of a signal to its codomain; the mapping from spatial coordinates of an image to its pixel values, for example. Being capable of conveying fine details in a high dimensional signal, unboundedly of its domain, implicit neural representations ensure many advantages over conventional discrete representations. However, the current approach is difficult to scale for a large number of signals or a data set, since learning a neural representation -- which is parameter heavy by itself -- for each signal individually requires a lot of memory and computations. To address this issue, we propose to leverage a meta-learning approach in combination with network compression under a sparsity constraint, such that it renders a well-initialized sparse parameterization that evolves quickly to represent a set of unseen signals in the subsequent training. We empirically demonstrate that meta-learned sparse neural representations achieve a much smaller loss than dense meta-learned models with the same number of parameters, when trained to fit each signal using the same number of optimization steps.
Landmark-Guided Subgoal Generation in Hierarchical Reinforcement Learning
Oct 27, 2021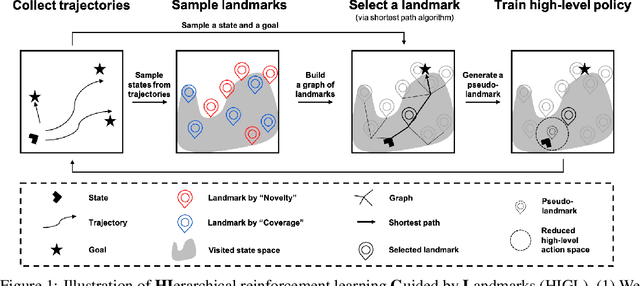
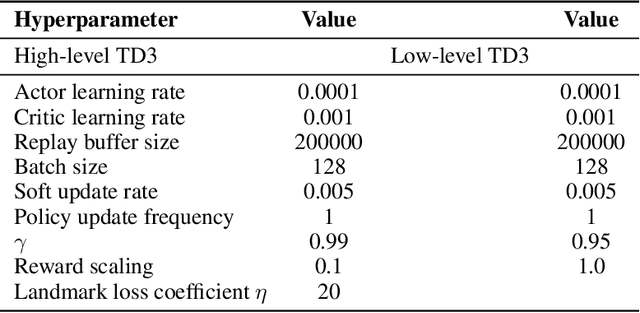
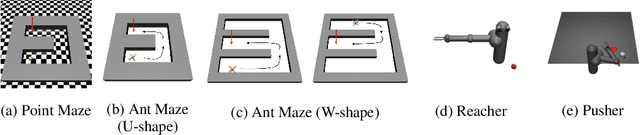
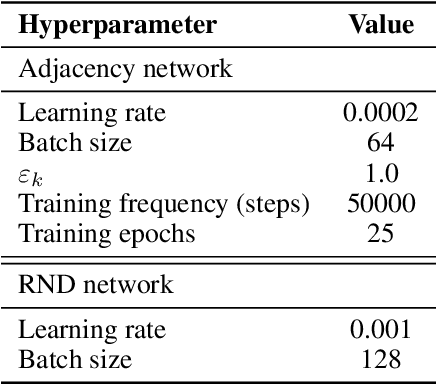
Goal-conditioned hierarchical reinforcement learning (HRL) has shown promising results for solving complex and long-horizon RL tasks. However, the action space of high-level policy in the goal-conditioned HRL is often large, so it results in poor exploration, leading to inefficiency in training. In this paper, we present HIerarchical reinforcement learning Guided by Landmarks (HIGL), a novel framework for training a high-level policy with a reduced action space guided by landmarks, i.e., promising states to explore. The key component of HIGL is twofold: (a) sampling landmarks that are informative for exploration and (b) encouraging the high-level policy to generate a subgoal towards a selected landmark. For (a), we consider two criteria: coverage of the entire visited state space (i.e., dispersion of states) and novelty of states (i.e., prediction error of a state). For (b), we select a landmark as the very first landmark in the shortest path in a graph whose nodes are landmarks. Our experiments demonstrate that our framework outperforms prior-arts across a variety of control tasks, thanks to efficient exploration guided by landmarks.
RoMA: Robust Model Adaptation for Offline Model-based Optimization
Oct 27, 2021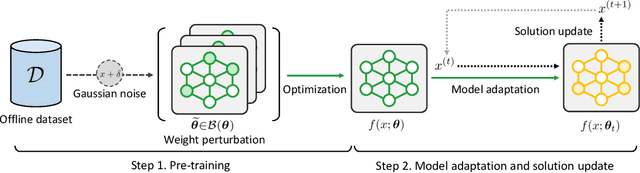
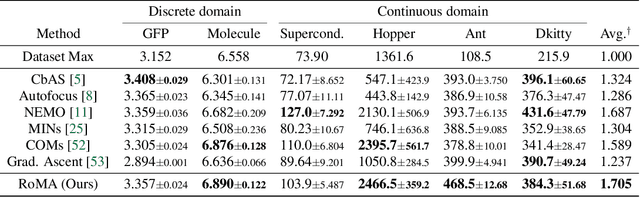
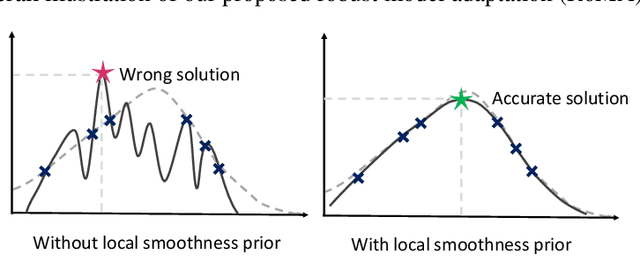
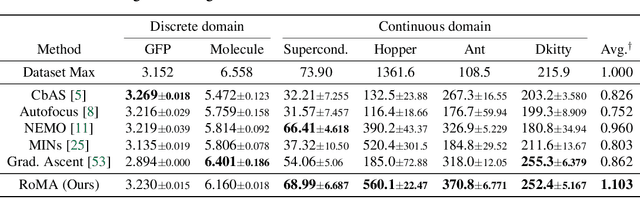
We consider the problem of searching an input maximizing a black-box objective function given a static dataset of input-output queries. A popular approach to solving this problem is maintaining a proxy model, e.g., a deep neural network (DNN), that approximates the true objective function. Here, the main challenge is how to avoid adversarially optimized inputs during the search, i.e., the inputs where the DNN highly overestimates the true objective function. To handle the issue, we propose a new framework, coined robust model adaptation (RoMA), based on gradient-based optimization of inputs over the DNN. Specifically, it consists of two steps: (a) a pre-training strategy to robustly train the proxy model and (b) a novel adaptation procedure of the proxy model to have robust estimates for a specific set of candidate solutions. At a high level, our scheme utilizes the local smoothness prior to overcome the brittleness of the DNN. Experiments under various tasks show the effectiveness of RoMA compared with previous methods, obtaining state-of-the-art results, e.g., RoMA outperforms all at 4 out of 6 tasks and achieves runner-up results at the remaining tasks.
Object-Aware Regularization for Addressing Causal Confusion in Imitation Learning
Oct 27, 2021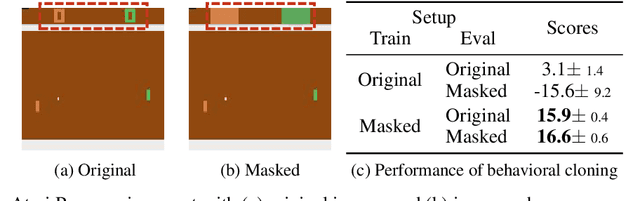
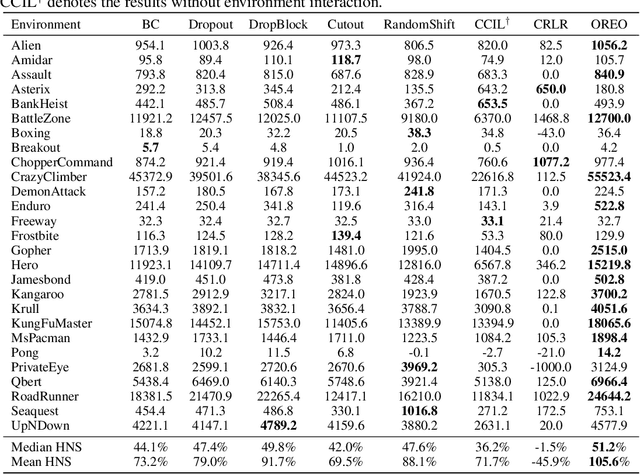
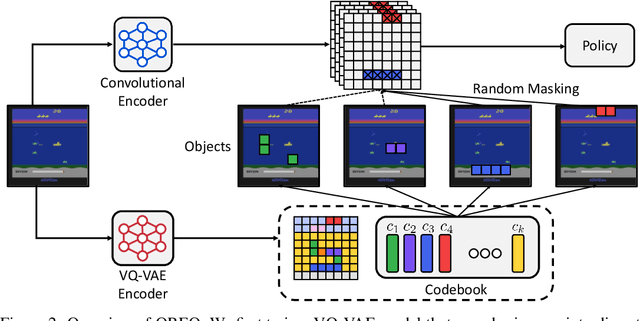
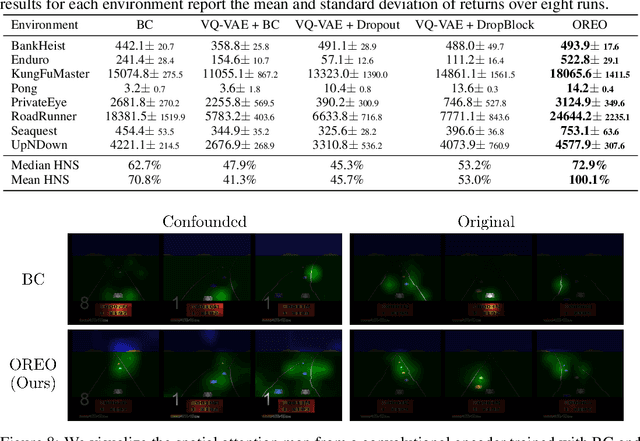
Behavioral cloning has proven to be effective for learning sequential decision-making policies from expert demonstrations. However, behavioral cloning often suffers from the causal confusion problem where a policy relies on the noticeable effect of expert actions due to the strong correlation but not the cause we desire. This paper presents Object-aware REgularizatiOn (OREO), a simple technique that regularizes an imitation policy in an object-aware manner. Our main idea is to encourage a policy to uniformly attend to all semantic objects, in order to prevent the policy from exploiting nuisance variables strongly correlated with expert actions. To this end, we introduce a two-stage approach: (a) we extract semantic objects from images by utilizing discrete codes from a vector-quantized variational autoencoder, and (b) we randomly drop the units that share the same discrete code together, i.e., masking out semantic objects. Our experiments demonstrate that OREO significantly improves the performance of behavioral cloning, outperforming various other regularization and causality-based methods on a variety of Atari environments and a self-driving CARLA environment. We also show that our method even outperforms inverse reinforcement learning methods trained with a considerable amount of environment interaction.
Abstract Reasoning via Logic-guided Generation
Aug 11, 2021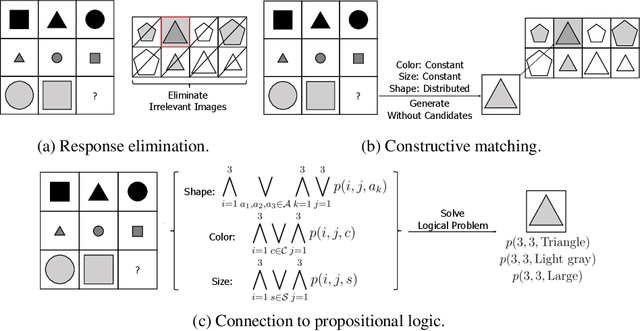
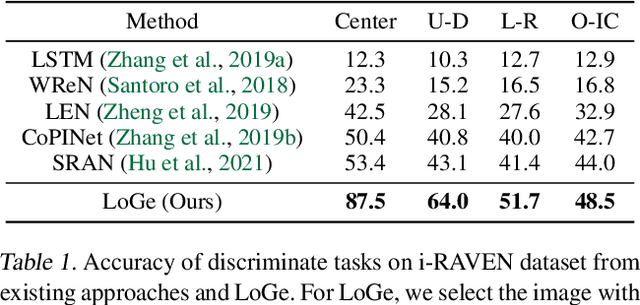
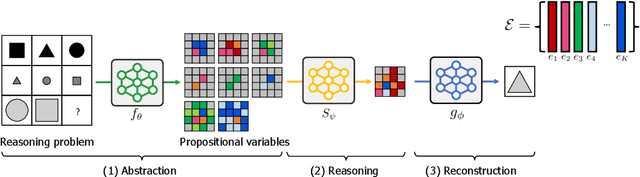
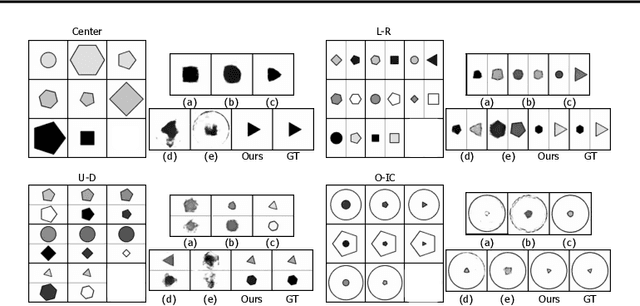
Abstract reasoning, i.e., inferring complicated patterns from given observations, is a central building block of artificial general intelligence. While humans find the answer by either eliminating wrong candidates or first constructing the answer, prior deep neural network (DNN)-based methods focus on the former discriminative approach. This paper aims to design a framework for the latter approach and bridge the gap between artificial and human intelligence. To this end, we propose logic-guided generation (LoGe), a novel generative DNN framework that reduces abstract reasoning as an optimization problem in propositional logic. LoGe is composed of three steps: extract propositional variables from images, reason the answer variables with a logic layer, and reconstruct the answer image from the variables. We demonstrate that LoGe outperforms the black box DNN frameworks for generative abstract reasoning under the RAVEN benchmark, i.e., reconstructing answers based on capturing correct rules of various attributes from observations.
Object-aware Contrastive Learning for Debiased Scene Representation
Jul 30, 2021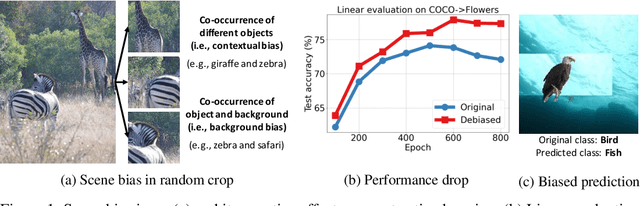

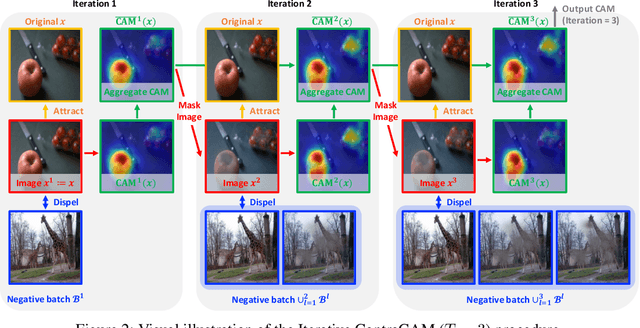

Contrastive self-supervised learning has shown impressive results in learning visual representations from unlabeled images by enforcing invariance against different data augmentations. However, the learned representations are often contextually biased to the spurious scene correlations of different objects or object and background, which may harm their generalization on the downstream tasks. To tackle the issue, we develop a novel object-aware contrastive learning framework that first (a) localizes objects in a self-supervised manner and then (b) debias scene correlations via appropriate data augmentations considering the inferred object locations. For (a), we propose the contrastive class activation map (ContraCAM), which finds the most discriminative regions (e.g., objects) in the image compared to the other images using the contrastively trained models. We further improve the ContraCAM to detect multiple objects and entire shapes via an iterative refinement procedure. For (b), we introduce two data augmentations based on ContraCAM, object-aware random crop and background mixup, which reduce contextual and background biases during contrastive self-supervised learning, respectively. Our experiments demonstrate the effectiveness of our representation learning framework, particularly when trained under multi-object images or evaluated under the background (and distribution) shifted images.
Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble
Jul 01, 2021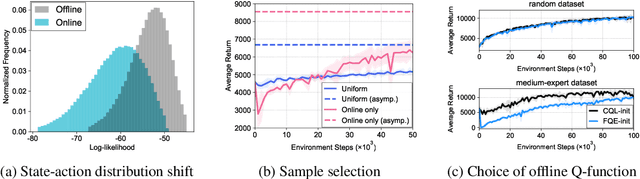
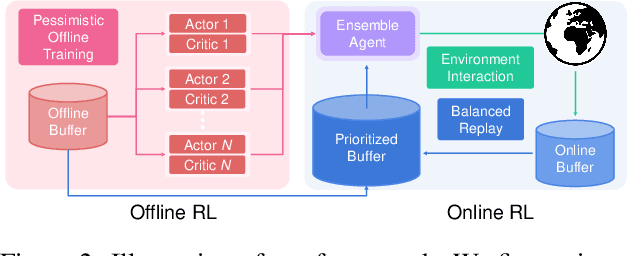
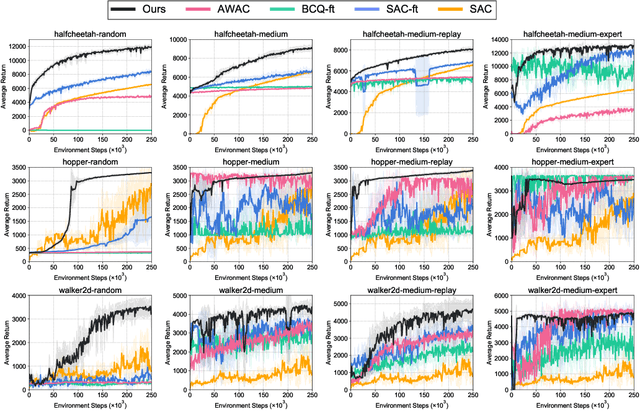
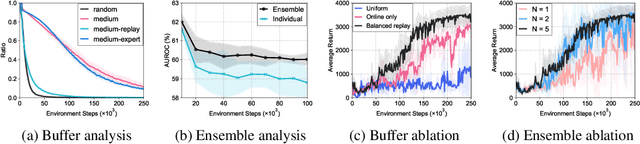
Recent advance in deep offline reinforcement learning (RL) has made it possible to train strong robotic agents from offline datasets. However, depending on the quality of the trained agents and the application being considered, it is often desirable to fine-tune such agents via further online interactions. In this paper, we observe that state-action distribution shift may lead to severe bootstrap error during fine-tuning, which destroys the good initial policy obtained via offline RL. To address this issue, we first propose a balanced replay scheme that prioritizes samples encountered online while also encouraging the use of near-on-policy samples from the offline dataset. Furthermore, we leverage multiple Q-functions trained pessimistically offline, thereby preventing overoptimism concerning unfamiliar actions at novel states during the initial training phase. We show that the proposed method improves sample-efficiency and final performance of the fine-tuned robotic agents on various locomotion and manipulation tasks. Our code is available at: https://github.com/shlee94/Off2OnRL.
OpenCoS: Contrastive Semi-supervised Learning for Handling Open-set Unlabeled Data
Jun 29, 2021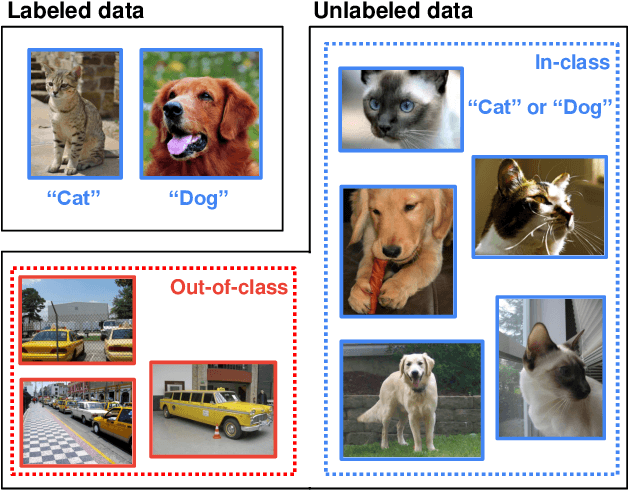
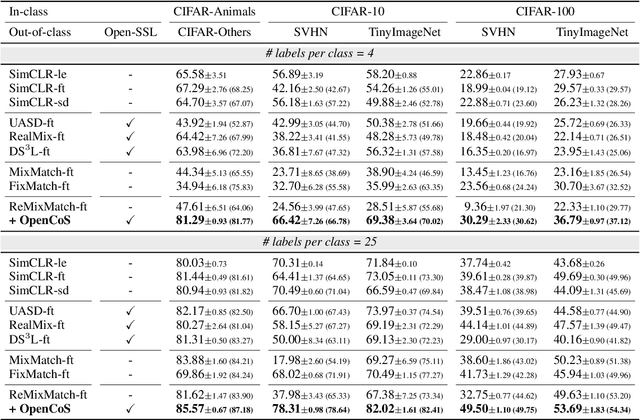
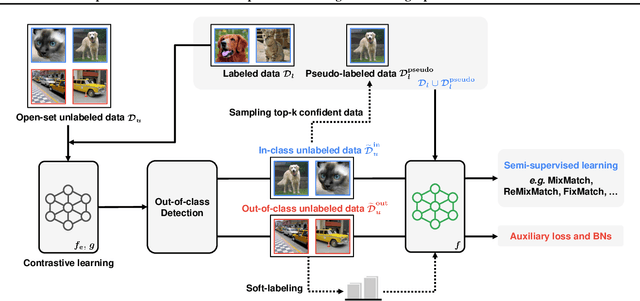
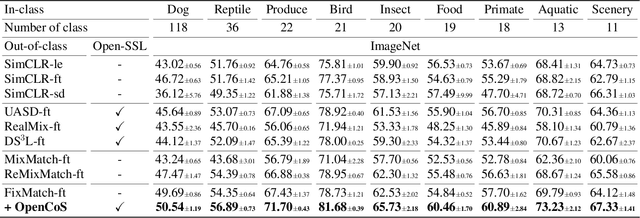
Modern semi-supervised learning methods conventionally assume both labeled and unlabeled data have the same class distribution. However, unlabeled data may include out-of-class samples in practice; those that cannot have one-hot encoded labels from a closed-set of classes in label data, i.e., unlabeled data is an open-set. In this paper, we introduce OpenCoS, a method for handling this realistic semi-supervised learning scenario based on a recent framework of contrastive learning. One of our key findings is that out-of-class samples in the unlabeled dataset can be identified effectively via (unsupervised) contrastive learning. OpenCoS utilizes this information to overcome the failure modes in the existing state-of-the-art semi-supervised methods, e.g., ReMixMatch or FixMatch. It further improves the semi-supervised performance by utilizing soft- and pseudo-labels on open-set unlabeled data, learned from contrastive learning. Our extensive experimental results show the effectiveness of OpenCoS, fixing the state-of-the-art semi-supervised methods to be suitable for diverse scenarios involving open-set unlabeled data.
Co$^2$L: Contrastive Continual Learning
Jun 28, 2021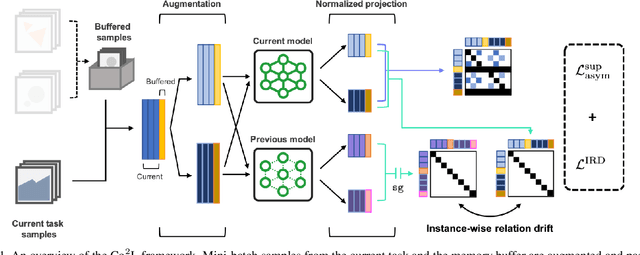
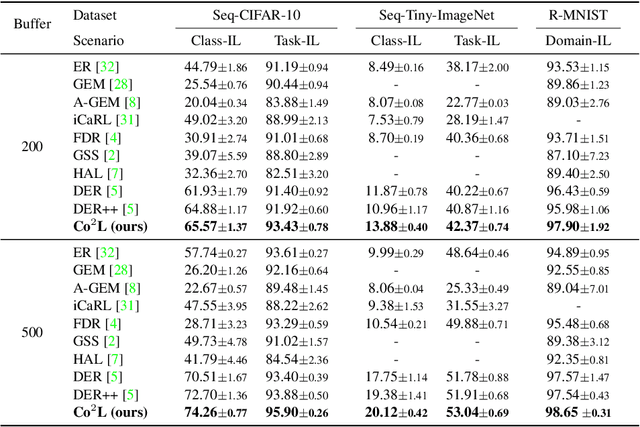
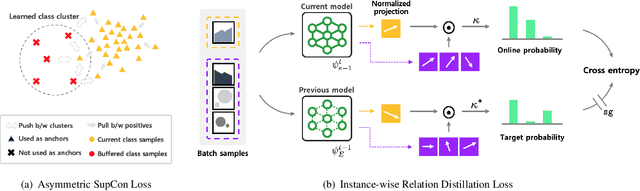
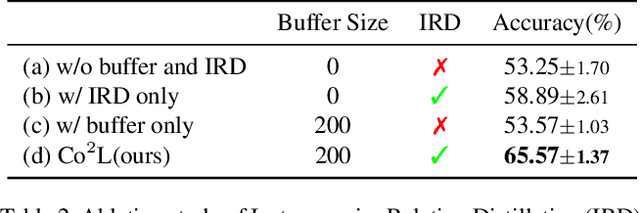
Recent breakthroughs in self-supervised learning show that such algorithms learn visual representations that can be transferred better to unseen tasks than joint-training methods relying on task-specific supervision. In this paper, we found that the similar holds in the continual learning con-text: contrastively learned representations are more robust against the catastrophic forgetting than jointly trained representations. Based on this novel observation, we propose a rehearsal-based continual learning algorithm that focuses on continually learning and maintaining transferable representations. More specifically, the proposed scheme (1) learns representations using the contrastive learning objective, and (2) preserves learned representations using a self-supervised distillation step. We conduct extensive experimental validations under popular benchmark image classification datasets, where our method sets the new state-of-the-art performance.
Scaling Neural Tangent Kernels via Sketching and Random Features
Jun 15, 2021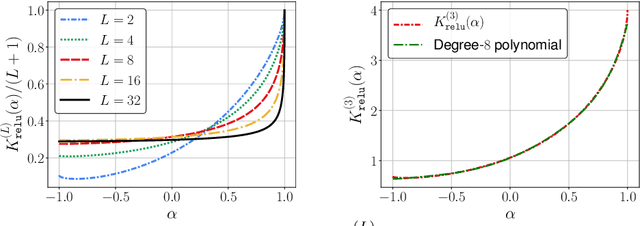

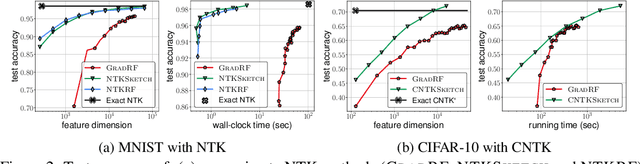
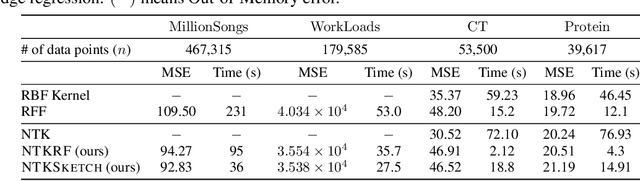
The Neural Tangent Kernel (NTK) characterizes the behavior of infinitely-wide neural networks trained under least squares loss by gradient descent. Recent works also report that NTK regression can outperform finitely-wide neural networks trained on small-scale datasets. However, the computational complexity of kernel methods has limited its use in large-scale learning tasks. To accelerate learning with NTK, we design a near input-sparsity time approximation algorithm for NTK, by sketching the polynomial expansions of arc-cosine kernels: our sketch for the convolutional counterpart of NTK (CNTK) can transform any image using a linear runtime in the number of pixels. Furthermore, we prove a spectral approximation guarantee for the NTK matrix, by combining random features (based on leverage score sampling) of the arc-cosine kernels with a sketching algorithm. We benchmark our methods on various large-scale regression and classification tasks and show that a linear regressor trained on our CNTK features matches the accuracy of exact CNTK on CIFAR-10 dataset while achieving 150x speedup.