 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAPM: Federated Learning via ADMM with Partial Model Personalization
Jun 05, 2025In federated learning (FL), the assumption that datasets from different devices are independent and identically distributed (i.i.d.) often does not hold due to user differences, and the presence of various data modalities across clients makes using a single model impractical. Personalizing certain parts of the model can effectively address these issues by allowing those parts to differ across clients, while the remaining parts serve as a shared model. However, we found that partial model personalization may exacerbate client drift (each client's local model diverges from the shared model), thereby reducing the effectiveness and efficiency of FL algorithms. We propose an FL framework based on the alternating direction method of multipliers (ADMM), referred to as FedAPM, to mitigate client drift. We construct the augmented Lagrangian function by incorporating first-order and second-order proximal terms into the objective, with the second-order term providing fixed correction and the first-order term offering compensatory correction between the local and shared models. Our analysis demonstrates that FedAPM, by using explicit estimates of the Lagrange multiplier, is more stable and efficient in terms of convergence compared to other FL frameworks. We establish the global convergence of FedAPM training from arbitrary initial points to a stationary point, achieving three types of rates: constant, linear, and sublinear, under mild assumptions. We conduct experiments using four heterogeneous and multimodal datasets with different metrics to validate the performance of FedAPM. Specifically, FedAPM achieves faster and more accurate convergence, outperforming the SOTA methods with average improvements of 12.3% in test accuracy, 16.4% in F1 score, and 18.0% in AUC while requiring fewer communication rounds.
On ADMM in Heterogeneous Federated Learning: Personalization, Robustness, and Fairness
Jul 23, 2024



Statistical heterogeneity is a root cause of tension among accuracy, fairness, and robustness of federated learning (FL), and is key in paving a path forward. Personalized FL (PFL) is an approach that aims to reduce the impact of statistical heterogeneity by developing personalized models for individual users, while also inherently providing benefits in terms of fairness and robustness. However, existing PFL frameworks focus on improving the performance of personalized models while neglecting the global model. Moreover, these frameworks achieve sublinear convergence rates and rely on strong assumptions. In this paper, we propose FLAME, an optimization framework by utilizing the alternating direction method of multipliers (ADMM) to train personalized and global models. We propose a model selection strategy to improve performance in situations where clients have different types of heterogeneous data. Our theoretical analysis establishes the global convergence and two kinds of convergence rates for FLAME under mild assumptions. We theoretically demonstrate that FLAME is more robust and fair than the state-of-the-art methods on a class of linear problems. Our experimental findings show that FLAME outperforms state-of-the-art methods in convergence and accuracy, and it achieves higher test accuracy under various attacks and performs more uniformly across clients.
Sequential Manipulation Against Rank Aggregation: Theory and Algorithm
Jul 02, 2024Rank aggregation with pairwise comparisons is widely encountered in sociology, politics, economics, psychology, sports, etc . Given the enormous social impact and the consequent incentives, the potential adversary has a strong motivation to manipulate the ranking list. However, the ideal attack opportunity and the excessive adversarial capability cause the existing methods to be impractical. To fully explore the potential risks, we leverage an online attack on the vulnerable data collection process. Since it is independent of rank aggregation and lacks effective protection mechanisms, we disrupt the data collection process by fabricating pairwise comparisons without knowledge of the future data or the true distribution. From the game-theoretic perspective, the confrontation scenario between the online manipulator and the ranker who takes control of the original data source is formulated as a distributionally robust game that deals with the uncertainty of knowledge. Then we demonstrate that the equilibrium in the above game is potentially favorable to the adversary by analyzing the vulnerability of the sampling algorithms such as Bernoulli and reservoir methods. According to the above theoretical analysis, different sequential manipulation policies are proposed under a Bayesian decision framework and a large class of parametric pairwise comparison models. For attackers with complete knowledge, we establish the asymptotic optimality of the proposed policies. To increase the success rate of the sequential manipulation with incomplete knowledge, a distributionally robust estimator, which replaces the maximum likelihood estimation in a saddle point problem, provides a conservative data generation solution. Finally, the corroborating empirical evidence shows that the proposed method manipulates the results of rank aggregation methods in a sequential manner.
Efficient k-means with Individual Fairness via Exponential Tilting
Jun 24, 2024In location-based resource allocation scenarios, the distances between each individual and the facility are desired to be approximately equal, thereby ensuring fairness. Individually fair clustering is often employed to achieve the principle of treating all points equally, which can be applied in these scenarios. This paper proposes a novel algorithm, tilted k-means (TKM), aiming to achieve individual fairness in clustering. We integrate the exponential tilting into the sum of squared errors (SSE) to formulate a novel objective function called tilted SSE. We demonstrate that the tilted SSE can generalize to SSE and employ the coordinate descent and first-order gradient method for optimization. We propose a novel fairness metric, the variance of the distances within each cluster, which can alleviate the Matthew Effect typically caused by existing fairness metrics. Our theoretical analysis demonstrates that the well-known k-means++ incurs a multiplicative error of O(k log k), and we establish the convergence of TKM under mild conditions. In terms of fairness, we prove that the variance generated by TKM decreases with a scaled hyperparameter. In terms of efficiency, we demonstrate the time complexity is linear with the dataset size. Our experiments demonstrate that TKM outperforms state-of-the-art methods in effectiveness, fairness, and efficiency.
Personalized Federated Learning via ADMM with Moreau Envelope
Nov 12, 2023Personalized federated learning (PFL) is an approach proposed to address the issue of poor convergence on heterogeneous data. However, most existing PFL frameworks require strong assumptions for convergence. In this paper, we propose an alternating direction method of multipliers (ADMM) for training PFL models with Moreau envelope (FLAME), which achieves a sublinear convergence rate, relying on the relatively weak assumption of gradient Lipschitz continuity. Moreover, due to the gradient-free nature of ADMM, FLAME alleviates the need for hyperparameter tuning, particularly in avoiding the adjustment of the learning rate when training the global model. In addition, we propose a biased client selection strategy to expedite the convergence of training of PFL models. Our theoretical analysis establishes the global convergence under both unbiased and biased client selection strategies. Our experiments validate that FLAME, when trained on heterogeneous data, outperforms state-of-the-art methods in terms of model performance. Regarding communication efficiency, it exhibits an average speedup of 3.75x compared to the baselines. Furthermore, experimental results validate that the biased client selection strategy speeds up the convergence of both personalized and global models.
SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
Nov 26, 2022



The automatic generation of Chinese fonts is an important problem involved in many applications. The predominated methods for the Chinese font generation are based on the deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based methods (say, CycleGAN) for the Chinese font generation usually suffer from the mode collapse issue, mainly due to the lack of effective guidance information. This paper proposes a novel information guidance module called the skeleton guided channel expansion (SGCE) module for the Chinese font generation through integrating the skeleton information into the generator with the channel expansion way, motivated by the observation that the skeleton embodies both local and global structure information of Chinese characters. We conduct extensive experiments to show the effectiveness of the proposed module. Numerical results show that the mode collapse issue suffered by the known CycleGAN can be effectively alleviated by equipping with the proposed SGCE module, and the CycleGAN equipped with SGCE outperforms the state-of-the-art models in terms of four important evaluation metrics and visualization quality. Besides CycleGAN, we also show that the suggested SGCE module can be adapted to other models for Chinese font generation as a plug-and-play module to further improve their performance.
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Nov 11, 2022



The generation of Chinese fonts has a wide range of applications. The currently predominated methods are mainly based on deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based models usually suffer from the well-known mode collapse problem. When mode collapse happens, the kind of GAN-based models will be failure to yield the correct fonts. To address this issue, we introduce a one-bit stroke encoding and a few-shot semi-supervised scheme (i.e., using a few paired data as semi-supervised information) to explore the local and global structure information of Chinese characters respectively, motivated by the intuition that strokes and characters directly embody certain local and global modes of Chinese characters. Based on these ideas, this paper proposes an effective model called \textit{StrokeGAN+}, which incorporates the stroke encoding and the few-shot semi-supervised scheme into the CycleGAN model. The effectiveness of the proposed model is demonstrated by amounts of experiments. Experimental results show that the mode collapse issue can be effectively alleviated by the introduced one-bit stroke encoding and few-shot semi-supervised training scheme, and that the proposed model outperforms the state-of-the-art models in fourteen font generation tasks in terms of four important evaluation metrics and the quality of generated characters. Besides CycleGAN, we also show that the proposed idea can be adapted to other existing models to improve their performance. The effectiveness of the proposed model for the zero-shot traditional Chinese font generation is also evaluated in this paper.
STAR: Zero-Shot Chinese Character Recognition with Stroke- and Radical-Level Decompositions
Oct 16, 2022
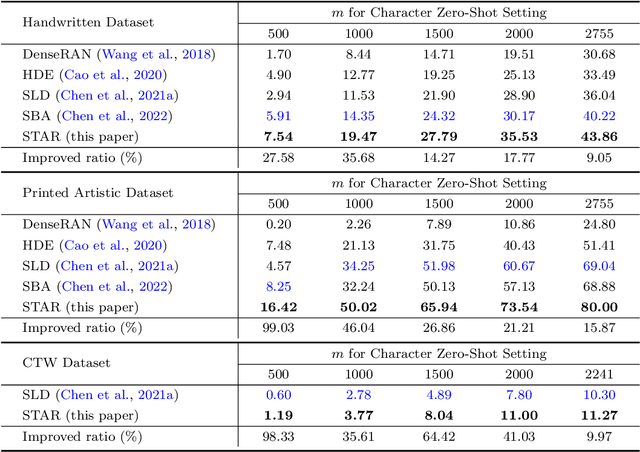
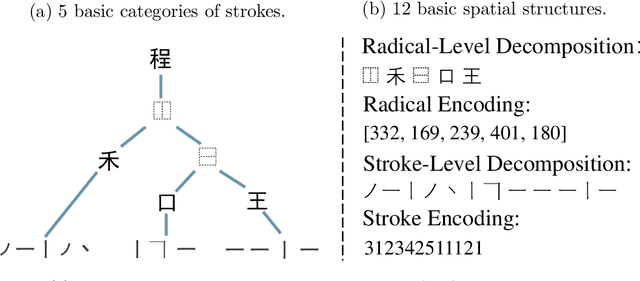
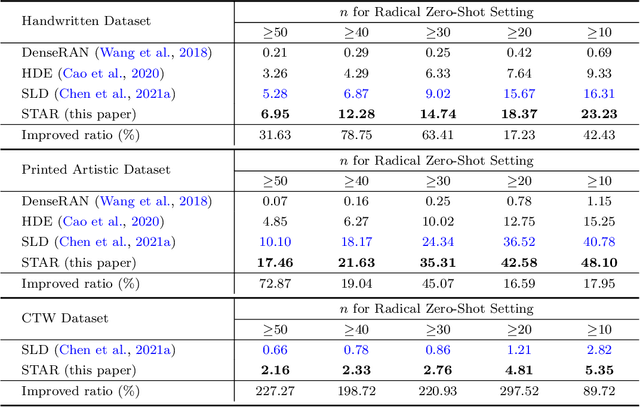
Zero-shot Chinese character recognition has attracted rising attention in recent years. Existing methods for this problem are mainly based on either certain low-level stroke-based decomposition or medium-level radical-based decomposition. Considering that the stroke- and radical-level decompositions can provide different levels of information, we propose an effective zero-shot Chinese character recognition method by combining them. The proposed method consists of a training stage and an inference stage. In the training stage, we adopt two similar encoder-decoder models to yield the estimates of stroke and radical encodings, which together with the true encodings are then used to formalize the associated stroke and radical losses for training. A similarity loss is introduced to regularize stroke and radical encoders to yield features of the same characters with high correlation. In the inference stage, two key modules, i.e., the stroke screening module (SSM) and feature matching module (FMM) are introduced to tackle the deterministic and confusing cases respectively. In particular, we introduce an effective stroke rectification scheme in FMM to enlarge the candidate set of characters for final inference. Numerous experiments over three benchmark datasets covering the handwritten, printed artistic and street view scenarios are conducted to demonstrate the effectiveness of the proposed method. Numerical results show that the proposed method outperforms the state-of-the-art methods in both character and radical zero-shot settings, and maintains competitive performance in the traditional seen character setting.
A Tale of HodgeRank and Spectral Method: Target Attack Against Rank Aggregation Is the Fixed Point of Adversarial Game
Sep 13, 2022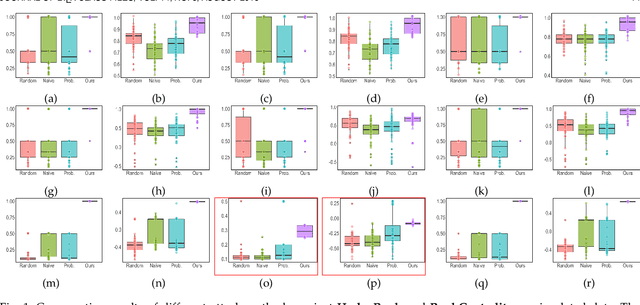

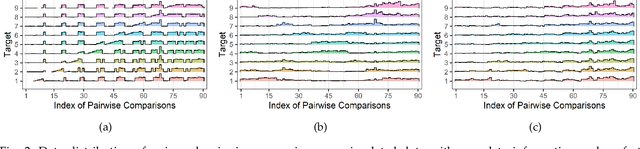

Rank aggregation with pairwise comparisons has shown promising results in elections, sports competitions, recommendations, and information retrieval. However, little attention has been paid to the security issue of such algorithms, in contrast to numerous research work on the computational and statistical characteristics. Driven by huge profits, the potential adversary has strong motivation and incentives to manipulate the ranking list. Meanwhile, the intrinsic vulnerability of the rank aggregation methods is not well studied in the literature. To fully understand the possible risks, we focus on the purposeful adversary who desires to designate the aggregated results by modifying the pairwise data in this paper. From the perspective of the dynamical system, the attack behavior with a target ranking list is a fixed point belonging to the composition of the adversary and the victim. To perform the targeted attack, we formulate the interaction between the adversary and the victim as a game-theoretic framework consisting of two continuous operators while Nash equilibrium is established. Then two procedures against HodgeRank and RankCentrality are constructed to produce the modification of the original data. Furthermore, we prove that the victims will produce the target ranking list once the adversary masters the complete information. It is noteworthy that the proposed methods allow the adversary only to hold incomplete information or imperfect feedback and perform the purposeful attack. The effectiveness of the suggested target attack strategies is demonstrated by a series of toy simulations and several real-world data experiments. These experimental results show that the proposed methods could achieve the attacker's goal in the sense that the leading candidate of the perturbed ranking list is the designated one by the adversary.
* 33 pages, https://github.com/alphaprime/Target_Attack_Rank_Aggregation
Reducing Capacity Gap in Knowledge Distillation with Review Mechanism for Crowd Counting
Jun 11, 2022
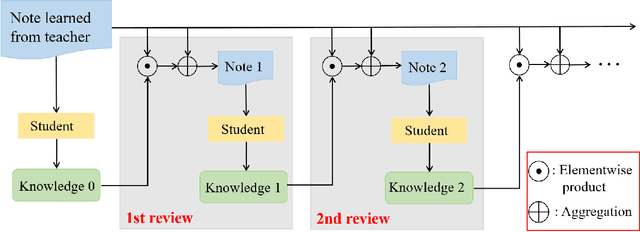
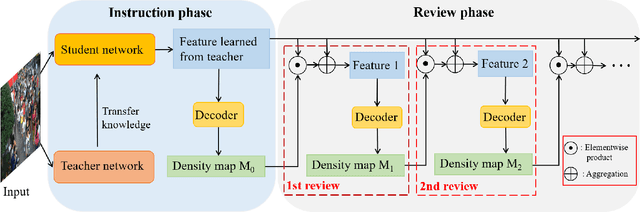
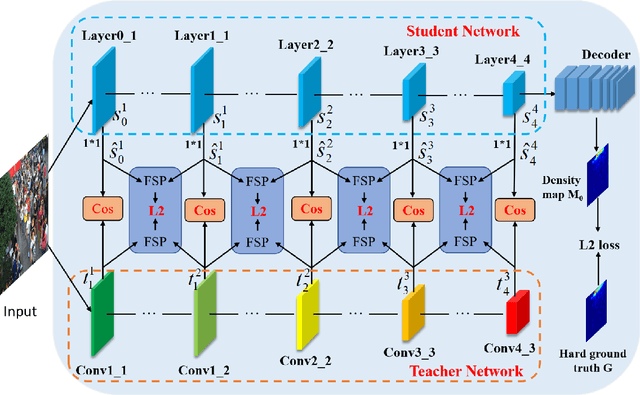
The lightweight crowd counting models, in particular knowledge distillation (KD) based models, have attracted rising attention in recent years due to their superiority on computational efficiency and hardware requirement. However, existing KD based models usually suffer from the capacity gap issue, resulting in the performance of the student network being limited by the teacher network. In this paper, we address this issue by introducing a novel review mechanism following KD models, motivated by the review mechanism of human-beings during the study. Thus, the proposed model is dubbed ReviewKD. The proposed model consists of an instruction phase and a review phase, where we firstly exploit a well-trained heavy teacher network to transfer its latent feature to a lightweight student network in the instruction phase, then in the review phase yield a refined estimate of the density map based on the learned feature through a review mechanism. The effectiveness of ReviewKD is demonstrated by a set of experiments over six benchmark datasets via comparing to the state-of-the-art models. Numerical results show that ReviewKD outperforms existing lightweight models for crowd counting, and can effectively alleviate the capacity gap issue, and particularly has the performance beyond the teacher network. Besides the lightweight models, we also show that the suggested review mechanism can be used as a plug-and-play module to further boost the performance of a kind of heavy crowd counting models without modifying the neural network architecture and introducing any additional model parameter.