 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTG: Generalizable Trajectory Generation Model for Urban Mobility
Feb 03, 2025



Trajectory data mining is crucial for smart city management. However, collecting large-scale trajectory datasets is challenging due to factors such as commercial conflicts and privacy regulations. Therefore, we urgently need trajectory generation techniques to address this issue. Existing trajectory generation methods rely on the global road network structure of cities. When the road network structure changes, these methods are often not transferable to other cities. In fact, there exist invariant mobility patterns between different cities: 1) People prefer paths with the minimal travel cost; 2) The travel cost of roads has an invariant relationship with the topological features of the road network. Based on the above insight, this paper proposes a Generalizable Trajectory Generation model (GTG). The model consists of three parts: 1) Extracting city-invariant road representation based on Space Syntax method; 2) Cross-city travel cost prediction through disentangled adversarial training; 3) Travel preference learning by shortest path search and preference update. By learning invariant movement patterns, the model is capable of generating trajectories in new cities. Experiments on three datasets demonstrates that our model significantly outperforms existing models in terms of generalization ability.
Exact Fit Attention in Node-Holistic Graph Convolutional Network for Improved EEG-Based Driver Fatigue Detection
Jan 25, 2025EEG-based fatigue monitoring can effectively reduce the incidence of related traffic accidents. In the past decade, with the advancement of deep learning, convolutional neural networks (CNN) have been increasingly used for EEG signal processing. However, due to the data's non-Euclidean characteristics, existing CNNs may lose important spatial information from EEG, specifically channel correlation. Thus, we propose the node-holistic graph convolutional network (NHGNet), a model that uses graphic convolution to dynamically learn each channel's features. With exact fit attention optimization, the network captures inter-channel correlations through a trainable adjacency matrix. The interpretability is enhanced by revealing critical areas of brain activity and their interrelations in various mental states. In validations on two public datasets, NHGNet outperforms the SOTAs. Specifically, in the intra-subject, NHGNet improved detection accuracy by at least 2.34% and 3.42%, and in the inter-subjects, it improved by at least 2.09% and 15.06%. Visualization research on the model revealed that the central parietal area plays an important role in detecting fatigue levels, whereas the frontal and temporal lobes are essential for maintaining vigilance.
MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation
Jan 14, 2025



The growing demand for efficient and lightweight Retrieval-Augmented Generation (RAG) systems has highlighted significant challenges when deploying Small Language Models (SLMs) in existing RAG frameworks. Current approaches face severe performance degradation due to SLMs' limited semantic understanding and text processing capabilities, creating barriers for widespread adoption in resource-constrained scenarios. To address these fundamental limitations, we present MiniRAG, a novel RAG system designed for extreme simplicity and efficiency. MiniRAG introduces two key technical innovations: (1) a semantic-aware heterogeneous graph indexing mechanism that combines text chunks and named entities in a unified structure, reducing reliance on complex semantic understanding, and (2) a lightweight topology-enhanced retrieval approach that leverages graph structures for efficient knowledge discovery without requiring advanced language capabilities. Our extensive experiments demonstrate that MiniRAG achieves comparable performance to LLM-based methods even when using SLMs while requiring only 25\% of the storage space. Additionally, we contribute a comprehensive benchmark dataset for evaluating lightweight RAG systems under realistic on-device scenarios with complex queries. We fully open-source our implementation and datasets at: https://github.com/HKUDS/MiniRAG.
Distributionally Robust Policy Learning under Concept Drifts
Dec 18, 2024Distributionally robust policy learning aims to find a policy that performs well under the worst-case distributional shift, and yet most existing methods for robust policy learning consider the worst-case joint distribution of the covariate and the outcome. The joint-modeling strategy can be unnecessarily conservative when we have more information on the source of distributional shifts. This paper studiesa more nuanced problem -- robust policy learning under the concept drift, when only the conditional relationship between the outcome and the covariate changes. To this end, we first provide a doubly-robust estimator for evaluating the worst-case average reward of a given policy under a set of perturbed conditional distributions. We show that the policy value estimator enjoys asymptotic normality even if the nuisance parameters are estimated with a slower-than-root-$n$ rate. We then propose a learning algorithm that outputs the policy maximizing the estimated policy value within a given policy class $\Pi$, and show that the sub-optimality gap of the proposed algorithm is of the order $\kappa(\Pi)n^{-1/2}$, with $\kappa(\Pi)$ is the entropy integral of $\Pi$ under the Hamming distance and $n$ is the sample size. A matching lower bound is provided to show the optimality of the rate. The proposed methods are implemented and evaluated in numerical studies, demonstrating substantial improvement compared with existing benchmarks.
Learnable Sparse Customization in Heterogeneous Edge Computing
Dec 10, 2024



To effectively manage and utilize massive distributed data at the network edge, Federated Learning (FL) has emerged as a promising edge computing paradigm across data silos. However, FL still faces two challenges: system heterogeneity (i.e., the diversity of hardware resources across edge devices) and statistical heterogeneity (i.e., non-IID data). Although sparsification can extract diverse submodels for diverse clients, most sparse FL works either simply assign submodels with artificially-given rigid rules or prune partial parameters using heuristic strategies, resulting in inflexible sparsification and poor performance. In this work, we propose Learnable Personalized Sparsification for heterogeneous Federated learning (FedLPS), which achieves the learnable customization of heterogeneous sparse models with importance-associated patterns and adaptive ratios to simultaneously tackle system and statistical heterogeneity. Specifically, FedLPS learns the importance of model units on local data representation and further derives an importance-based sparse pattern with minimal heuristics to accurately extract personalized data features in non-IID settings. Furthermore, Prompt Upper Confidence Bound Variance (P-UCBV) is designed to adaptively determine sparse ratios by learning the superimposed effect of diverse device capabilities and non-IID data, aiming at resource self-adaptation with promising accuracy. Extensive experiments show that FedLPS outperforms status quo approaches in accuracy and training costs, which improves accuracy by 1.28%-59.34% while reducing running time by more than 68.80%.
BIGCity: A Universal Spatiotemporal Model for Unified Trajectory and Traffic State Data Analysis
Dec 01, 2024



Typical dynamic ST data includes trajectory data (representing individual-level mobility) and traffic state data (representing population-level mobility). Traditional studies often treat trajectory and traffic state data as distinct, independent modalities, each tailored to specific tasks within a single modality. However, real-world applications, such as navigation apps, require joint analysis of trajectory and traffic state data. Treating these data types as two separate domains can lead to suboptimal model performance. Although recent advances in ST data pre-training and ST foundation models aim to develop universal models for ST data analysis, most existing models are "multi-task, solo-data modality" (MTSM), meaning they can handle multiple tasks within either trajectory data or traffic state data, but not both simultaneously. To address this gap, this paper introduces BIGCity, the first multi-task, multi-data modality (MTMD) model for ST data analysis. The model targets two key challenges in designing an MTMD ST model: (1) unifying the representations of different ST data modalities, and (2) unifying heterogeneous ST analysis tasks. To overcome the first challenge, BIGCity introduces a novel ST-unit that represents both trajectories and traffic states in a unified format. Additionally, for the second challenge, BIGCity adopts a tunable large model with ST task-oriented prompt, enabling it to perform a range of heterogeneous tasks without the need for fine-tuning. Extensive experiments on real-world datasets demonstrate that BIGCity achieves state-of-the-art performance across 8 tasks, outperforming 18 baselines. To the best of our knowledge, BIGCity is the first model capable of handling both trajectories and traffic states for diverse heterogeneous tasks. Our code are available at https://github.com/bigscity/BIGCity
VecCity: A Taxonomy-guided Library for Map Entity Representation Learning
Oct 31, 2024



Electronic maps consist of diverse entities, such as points of interest (POIs), road networks, and land parcels, playing a vital role in applications like ITS and LBS. Map entity representation learning (MapRL) generates versatile and reusable data representations, providing essential tools for efficiently managing and utilizing map entity data. Despite the progress in MapRL, two key challenges constrain further development. First, existing research is fragmented, with models classified by the type of map entity, limiting the reusability of techniques across different tasks. Second, the lack of unified benchmarks makes systematic evaluation and comparison of models difficult. To address these challenges, we propose a novel taxonomy for MapRL that organizes models based on functional module-such as encoders, pre-training tasks, and downstream tasks-rather than by entity type. Building on this taxonomy, we present a taxonomy-driven library, VecCity, which offers easy-to-use interfaces for encoding, pre-training, fine-tuning, and evaluation. The library integrates datasets from nine cities and reproduces 21 mainstream MapRL models, establishing the first standardized benchmarks for the field. VecCity also allows users to modify and extend models through modular components, facilitating seamless experimentation. Our comprehensive experiments cover multiple types of map entities and evaluate 21 VecCity pre-built models across various downstream tasks. Experimental results demonstrate the effectiveness of VecCity in streamlining model development and provide insights into the impact of various components on performance. By promoting modular design and reusability, VecCity offers a unified framework to advance research and innovation in MapRL. The code is available at https://github.com/Bigscity-VecCity/VecCity.
Performance Analysis of Photon-Limited Free-Space Optical Communications with Practical Photon-Counting Receivers
Aug 24, 2024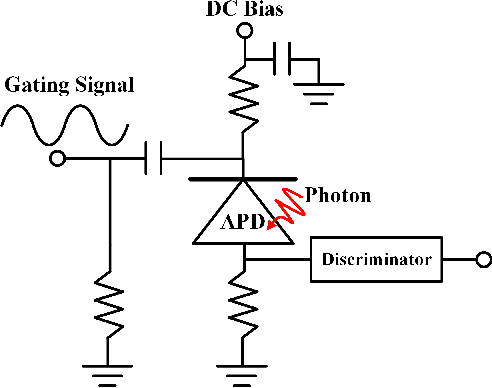
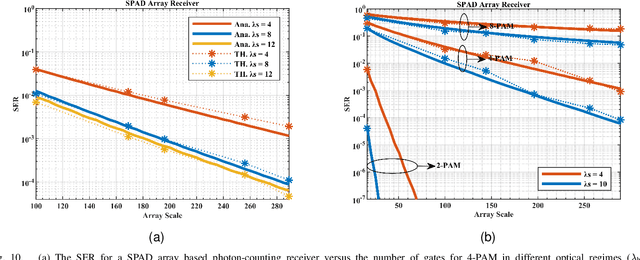
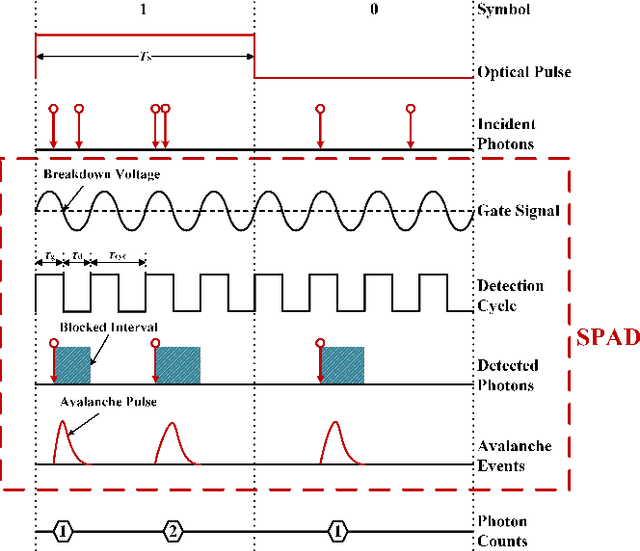
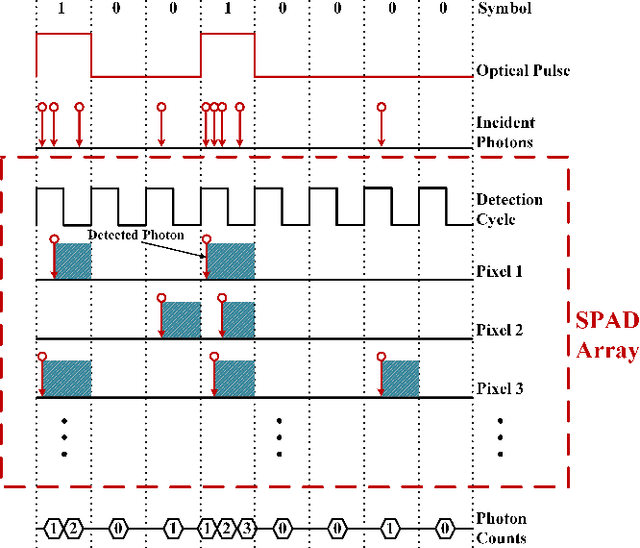
The non-perfect factors of practical photon-counting receiver are recognized as a significant challenge for long-distance photon-limited free-space optical (FSO) communication systems. This paper presents a comprehensive analytical framework for modeling the statistical properties of time-gated single-photon avalanche diode (TG-SPAD) based photon-counting receivers in presence of dead time, non-photon-number-resolving and afterpulsing effect. Drawing upon the non-Markovian characteristic of afterpulsing effect, we formulate a closed-form approximation for the probability mass function (PMF) of photon counts, when high-order pulse amplitude modulation (PAM) is used. Unlike the photon counts from a perfect photon-counting receiver, which adhere to a Poisson arrival process, the photon counts from a practical TG-SPAD based receiver are instead approximated by a binomial distribution. Additionally, by employing the maximum likelihood (ML) criterion, we derive a refined closed-form formula for determining the threshold in high-order PAM, thereby facilitating the development of an analytical model for the symbol error rate (SER). Utilizing this analytical SER model, the system performance is investigated. The numerical results underscore the crucial need to suppress background radiation below the tolerated threshold and to maintain a sufficient number of gates in order to achieve a target SER.
A Novel Signal Detection Method for Photon-Counting Communications with Nonlinear Distortion Effects
Aug 20, 2024



This paper proposes a method for estimating and detecting optical signals in practical photon-counting receivers. There are two important aspects of non-perfect photon-counting receivers, namely, (i) dead time which results in blocking loss, and (ii) non-photon-number-resolving, which leads to counting loss during the gate-ON interval. These factors introduce nonlinear distortion to the detected photon counts. The detected photon counts depend not only on the optical intensity but also on the signal waveform, and obey a Poisson binomial process. Using the discrete Fourier transform characteristic function (DFT-CF) method, we derive the probability mass function (PMF) of the detected photon counts. Furthermore, unlike conventional methods that assume an ideal rectangle wave, we propose a novel signal estimation and decision method applicable to arbitrary waveform. We demonstrate that the proposed method achieves superior error performance compared to conventional methods. The proposed algorithm has the potential to become an essential signal processing tool for photon-counting receivers.
Proposal Report for the 2nd SciCAP Competition 2024
Jul 02, 2024In this paper, we propose a method for document summarization using auxiliary information. This approach effectively summarizes descriptions related to specific images, tables, and appendices within lengthy texts. Our experiments demonstrate that leveraging high-quality OCR data and initially extracted information from the original text enables efficient summarization of the content related to described objects. Based on these findings, we enhanced popular text generation model models by incorporating additional auxiliary branches to improve summarization performance. Our method achieved top scores of 4.33 and 4.66 in the long caption and short caption tracks, respectively, of the 2024 SciCAP competition, ranking highest in both categories.