 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryoFormer: Continuous Reconstruction of 3D Structures from Cryo-EM Data using Transformer-based Neural Representations
Mar 28, 2023High-resolution heterogeneous reconstruction of 3D structures of proteins and other biomolecules using cryo-electron microscopy (cryo-EM) is essential for understanding fundamental processes of life. However, it is still challenging to reconstruct the continuous motions of 3D structures from hundreds of thousands of noisy and randomly oriented 2D cryo-EM images. Existing methods based on coordinate-based neural networks show compelling results to model continuous conformations of 3D structures in the Fourier domain, but they suffer from a limited ability to model local flexible regions and lack interpretability. We propose a novel approach, cryoFormer, that utilizes a transformer-based network architecture for continuous heterogeneous cryo-EM reconstruction. We for the first time directly reconstruct continuous conformations of 3D structures using an implicit feature volume in the 3D spatial domain. A novel deformation transformer decoder further improves reconstruction quality and, more importantly, locates and robustly tackles flexible 3D regions caused by conformations. In experiments, our method outperforms current approaches on three public datasets (1 synthetic and 2 experimental) and a new synthetic dataset of PEDV spike protein. The code and new synthetic dataset will be released for better reproducibility of our results. Project page: https://cryoformer.github.io.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 12, 2023This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 16, 2022



Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.
NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Dec 15, 2022



Humans constantly interact with objects in daily life tasks. Capturing such processes and subsequently conducting visual inferences from a fixed viewpoint suffers from occlusions, shape and texture ambiguities, motions, etc. To mitigate the problem, it is essential to build a training dataset that captures free-viewpoint interactions. We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of $\sim$75M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects. Extensive experiments on the HODome dataset demonstrate the effectiveness of NeuralDome on a variety of inference, modeling, and rendering tasks. Both the dataset and the NeuralDome tools will be disseminated to the community for further development.
Executing your Commands via Motion Diffusion in Latent Space
Dec 08, 2022



We study a challenging task, conditional human motion generation, which produces plausible human motion sequences according to various conditional inputs, such as action classes or textual descriptors. Since human motions are highly diverse and have a property of quite different distribution from conditional modalities, such as textual descriptors in natural languages, it is hard to learn a probabilistic mapping from the desired conditional modality to the human motion sequences. Besides, the raw motion data from the motion capture system might be redundant in sequences and contain noises; directly modeling the joint distribution over the raw motion sequences and conditional modalities would need a heavy computational overhead and might result in artifacts introduced by the captured noises. To learn a better representation of the various human motion sequences, we first design a powerful Variational AutoEncoder (VAE) and arrive at a representative and low-dimensional latent code for a human motion sequence. Then, instead of using a diffusion model to establish the connections between the raw motion sequences and the conditional inputs, we perform a diffusion process on the motion latent space. Our proposed Motion Latent-based Diffusion model (MLD) could produce vivid motion sequences conforming to the given conditional inputs and substantially reduce the computational overhead in both the training and inference stages. Extensive experiments on various human motion generation tasks demonstrate that our MLD achieves significant improvements over the state-of-the-art methods among extensive human motion generation tasks, with two orders of magnitude faster than previous diffusion models on raw motion sequences.
Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR
Nov 30, 2022



Depth estimation is usually ill-posed and ambiguous for monocular camera-based 3D multi-person pose estimation. Since LiDAR can capture accurate depth information in long-range scenes, it can benefit both the global localization of individuals and the 3D pose estimation by providing rich geometry features. Motivated by this, we propose a monocular camera and single LiDAR-based method for 3D multi-person pose estimation in large-scale scenes, which is easy to deploy and insensitive to light. Specifically, we design an effective fusion strategy to take advantage of multi-modal input data, including images and point cloud, and make full use of temporal information to guide the network to learn natural and coherent human motions. Without relying on any 3D pose annotations, our method exploits the inherent geometry constraints of point cloud for self-supervision and utilizes 2D keypoints on images for weak supervision. Extensive experiments on public datasets and our newly collected dataset demonstrate the superiority and generalization capability of our proposed method.
LiCamGait: Gait Recognition in the Wild by Using LiDAR and Camera Multi-modal Visual Sensors
Nov 22, 2022



LiDAR can capture accurate depth information in large-scale scenarios without the effect of light conditions, and the captured point cloud contains gait-related 3D geometric properties and dynamic motion characteristics. We make the first attempt to leverage LiDAR to remedy the limitation of view-dependent and light-sensitive camera for more robust and accurate gait recognition. In this paper, we propose a LiDAR-camera-based gait recognition method with an effective multi-modal feature fusion strategy, which fully exploits advantages of both point clouds and images. In particular, we propose a new in-the-wild gait dataset, LiCamGait, involving multi-modal visual data and diverse 2D/3D representations. Our method achieves state-of-the-art performance on the new dataset. Code and dataset will be released when this paper is published.
Joint Rigid Motion Correction and Sparse-View CT via Self-Calibrating Neural Field
Nov 06, 2022Neural Radiance Field (NeRF) has widely received attention in Sparse-View Computed Tomography (SVCT) reconstruction tasks as a self-supervised deep learning framework. NeRF-based SVCT methods represent the desired CT image as a continuous function of spatial coordinates and train a Multi-Layer Perceptron (MLP) to learn the function by minimizing loss on the SV sinogram. Benefiting from the continuous representation provided by NeRF, the high-quality CT image can be reconstructed. However, existing NeRF-based SVCT methods strictly suppose there is completely no relative motion during the CT acquisition because they require \textit{accurate} projection poses to model the X-rays that scan the SV sinogram. Therefore, these methods suffer from severe performance drops for real SVCT imaging with motion. In this work, we propose a self-calibrating neural field to recover the artifacts-free image from the rigid motion-corrupted SV sinogram without using any external data. Specifically, we parametrize the inaccurate projection poses caused by rigid motion as trainable variables and then jointly optimize these pose variables and the MLP. We conduct numerical experiments on a public CT image dataset. The results indicate our model significantly outperforms two representative NeRF-based methods for SVCT reconstruction tasks with four different levels of rigid motion.
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

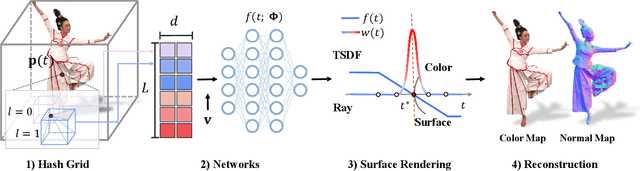
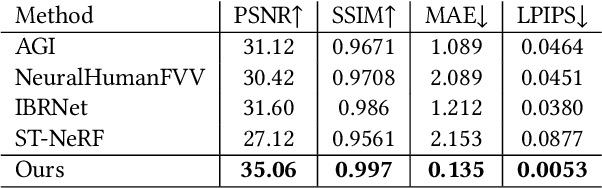
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022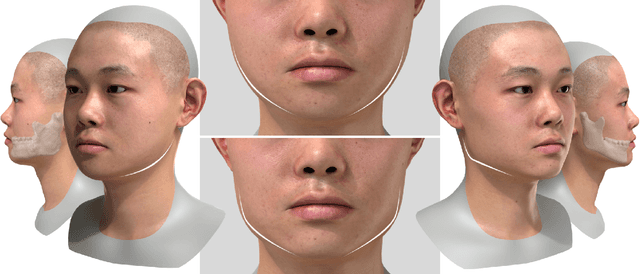
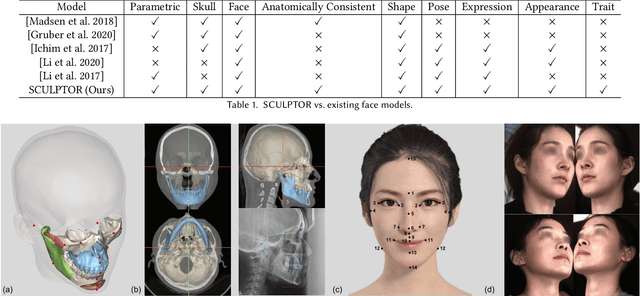
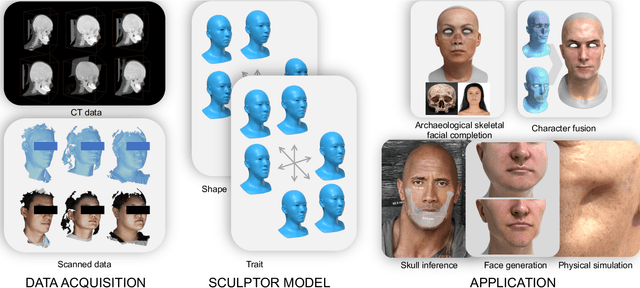
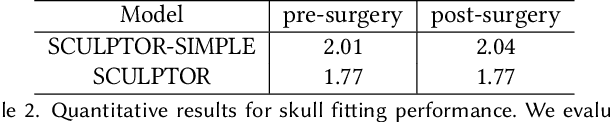
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.