 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-HYPER: Generative CTR Modeling for Cold-Start Ad Personalization via LLM-Based Hypernetworks
Apr 13, 2026On online advertising platforms, newly introduced promotional ads face the cold-start problem, as they lack sufficient user feedback for model training. In this work, we propose LLM-HYPER, a novel framework that treats large language models (LLMs) as hypernetworks to directly generate the parameters of the click-through rate (CTR) estimator in a training-free manner. LLM-HYPER uses few-shot Chain-of-Thought prompting over multimodal ad content (text and images) to infer feature-wise model weights for a linear CTR predictor. By retrieving semantically similar past campaigns via CLIP embeddings and formatting them into prompt-based demonstrations, the LLM learns to reason about customer intent, feature influence, and content relevance. To ensure numerical stability and serviceability, we introduce normalization and calibration techniques that align the generated weights with production-ready CTR distributions. Extensive offline experiments show that LLM-HYPER significantly outperforms cold-start baselines in NDCG$@10$ by 55.9\%. Our real-world online A/B test on one of the top e-commerce platforms in the U.S. demonstrates the strong performance of LLM-HYPER, which drastically reduces the cold-start period and achieves competitive performance. LLM-HYPER has been successfully deployed in production.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
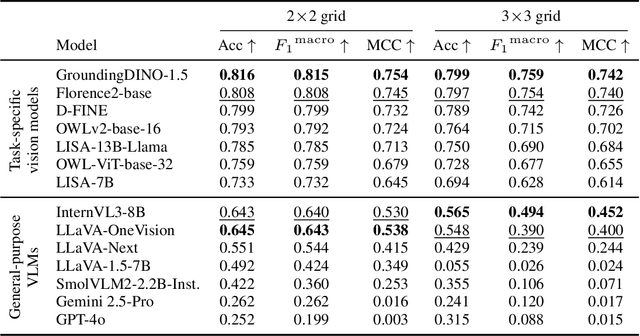

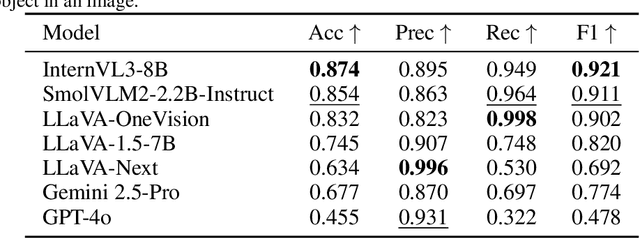
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.
Spatiotemporal Transformer for Imputing Sparse Data: A Deep Learning Approach
Dec 01, 2023



Effective management of environmental resources and agricultural sustainability heavily depends on accurate soil moisture data. However, datasets like the SMAP/Sentinel-1 soil moisture product often contain missing values across their spatiotemporal grid, which poses a significant challenge. This paper introduces a novel Spatiotemporal Transformer model (ST-Transformer) specifically designed to address the issue of missing values in sparse spatiotemporal datasets, particularly focusing on soil moisture data. The ST-Transformer employs multiple spatiotemporal attention layers to capture the complex spatiotemporal correlations in the data and can integrate additional spatiotemporal covariates during the imputation process, thereby enhancing its accuracy. The model is trained using a self-supervised approach, enabling it to autonomously predict missing values from observed data points. Our model's efficacy is demonstrated through its application to the SMAP 1km soil moisture data over a 36 x 36 km grid in Texas. It showcases superior accuracy compared to well-known imputation methods. Additionally, our simulation studies on other datasets highlight the model's broader applicability in various spatiotemporal imputation tasks.