 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAEExplainer: Interpreting SAE Features with Activation-Guided Preference Optimization
Jun 07, 2026Although Sparse Autoencoders (SAEs) have mitigated the opacity of large language models (LLMs) by decomposing dense representations into sparse features, explaining these features still remains a central challenge. Current explanation methods, however, typically operate within an open-loop paradigm, failing to leverage mechanistic feedback for further refinement. In this paper, we propose SAEExplainer, a training framework utilizes activation scores as an objective reward signal to train the model for self-correction and iterative bootstrapping. By iteratively verifying and correcting foundational explanations through a two-round optimization process, SAEExplainer achieves continuous improvement in its explanatory capabilities. This mechanism significantly reduces explanation hallucinations and reinforces causal triggering patterns. Extensive experiments demonstrate our approach improves upon established baselines across most metrics, especially in causal triggering and discriminative activation.
SurgOnAir: Hierarchy-Aware Real-Time Surgical Video Commentary
May 20, 2026Understanding surgical workflow in real time is fundamental for intelligent surgical embodiment, where AI systems continuously perceive and respond as surgery proceeds. In the operating room, critical decisions depend on subtle, moment-to-moment changes, such as fine instrument movements and evolving tissue states, where even slight perceptual delays can limit assistance or compromise safety. Yet existing methods remain offline or operate at coarse temporal scales, generating descriptions only after processing clips, preventing immediate reaction. We address this by proposing SurgOnAir, a streaming vision-language model that processes frames sequentially without future access and progressively generates narration tokens as visual input arrives. SurgOnAir achieves fine-grained frame-to-token generation, enabling instant responsiveness to evolving surgical dynamics. Built upon our curated hierarchical dataset SurgOnAir-11k spanning action-, step-, and phase-level supervision, the model is trained to produce multi-level textual responses that reflect the inherent hierarchy of surgical procedures. Furthermore, special transition tokens are generated to explicitly mark state changes, allowing SurgOnAir to capture and signal key workflow transitions as they occur. Experiments show that SurgOnAir enables real-time understanding through a single vision-language model that unifies streaming across multiple hierarchies of the surgical workflow, generating superior and hierarchy-aware narrations. Code and dataset will be public.
Grounding by Remembering: Cross-Scene and In-Scene Memory for 3D Functional Affordances
May 12, 2026Functional affordance grounding requires more than recognizing an object: an agent must localize the specific region that supports an interaction, such as the handle to pull or the button to press. This is difficult for training-free vision-language pipelines because actionable regions are often small, visually ambiguous, and repeated across multiple same-category instances in a scene. We propose AFFORDMEM, a framework that grounds 3D functional affordances by remembering geometry at two levels. The first is cross-scene affordance memory: the agent maintains a category-level memory bank of RGB images with affordance regions rendered as overlays, and recalls the most informative examples at query time to guide a frozen VLM toward small operable subregions that text-only prompting consistently misses. The second is in-scene spatial memory: as the agent processes the scene, it organizes candidate instances and their 3D spatial relations into a structured scene graph, enabling the language model to resolve references over distant or currently unobserved candidates such as "the second handle from the top." AFFORDMEM requires no model fine-tuning and no target-scene annotation, using a reusable memory bank built from source scenes. On SceneFun3D, our method improves AP50 over the prior training-free state of the art by 3.23 on Split 0 and 3.7 on Split 1. Ablation studies support complementary benefits: cross-scene affordance memory improves fine-grained localization, while in-scene spatial memory provides the larger gain on spatially qualified queries. The project homepage is available at the project page.
HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents
Apr 22, 2026Long-term conversational large language model (LLM) agents require memory systems that can recover relevant evidence from historical interactions without overwhelming the answer stage with irrelevant context. However, existing memory systems, including hierarchical ones, still often rely solely on vector similarity for retrieval. It tends to produce bloated evidence sets: adding many superficially similar dialogue turns yields little additional recall, but lowers retrieval precision, increases answer-stage context cost, and makes retrieved memories harder to inspect and manage. To address this, we propose HiGMem (Hierarchical and LLM-Guided Memory System), a two-level event-turn memory system that allows LLMs to use event summaries as semantic anchors to predict which related turns are worth reading. This allows the model to inspect high-level event summaries first and then focus on a smaller set of potentially useful turns, providing a concise and reliable evidence set through reasoning, while avoiding the retrieval overhead that would be excessively high compared to vector retrieval. On the LoCoMo10 benchmark, HiGMem achieves the best F1 on four of five question categories and improves adversarial F1 from 0.54 to 0.78 over A-Mem, while retrieving an order of magnitude fewer turns. Code is publicly available at https://github.com/ZeroLoss-Lab/HiGMem.
Beyond Hate: Differentiating Uncivil and Intolerant Speech in Multimodal Content Moderation
Mar 24, 2026Current multimodal toxicity benchmarks typically use a single binary hatefulness label. This coarse approach conflates two fundamentally different characteristics of expression: tone and content. Drawing on communication science theory, we introduce a fine-grained annotation scheme that distinguishes two separable dimensions: incivility (rude or dismissive tone) and intolerance (content that attacks pluralism and targets groups or identities) and apply it to 2,030 memes from the Hateful Memes dataset. We evaluate different vision-language models under coarse-label training, transfer learning across label schemes and a joint learning approach that combines the coarse hatefulness label with our fine-grained annotations. Our results show that fine-grained annotations complement existing coarse labels and, when used jointly, improve overall model performance. Moreover, models trained with the fine-grained scheme exhibit more balanced moderation-relevant error profiles and are less prone to under-detection of harmful content than models trained on hatefulness labels alone (FNR-FPR, the difference between false negative and false positive rates: 0.74 to 0.42 for LLaVA-1.6-Mistral-7B; 0.54 to 0.28 for Qwen2.5-VL-7B). This work contributes to data-centric approaches in content moderation by improving the reliability and accuracy of moderation systems through enhanced data quality. Overall, combining both coarse and fine-grained labels provides a practical route to more reliable multimodal moderation.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024



In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
Learning with Rejection for Abstractive Text Summarization
Feb 16, 2023



State-of-the-art abstractive summarization systems frequently hallucinate content that is not supported by the source document, mainly due to noise in the training dataset. Existing methods opt to drop the noisy samples or tokens from the training set entirely, reducing the effective training set size and creating an artificial propensity to copy words from the source. In this work, we propose a training objective for abstractive summarization based on rejection learning, in which the model learns whether or not to reject potentially noisy tokens. We further propose a regularized decoding objective that penalizes non-factual candidate summaries during inference by using the rejection probability learned during training. We show that our method considerably improves the factuality of generated summaries in automatic and human evaluations when compared to five baseline models and that it does so while increasing the abstractiveness of the generated summaries.
Learning Efficient Task-Specific Meta-Embeddings with Word Prisms
Nov 05, 2020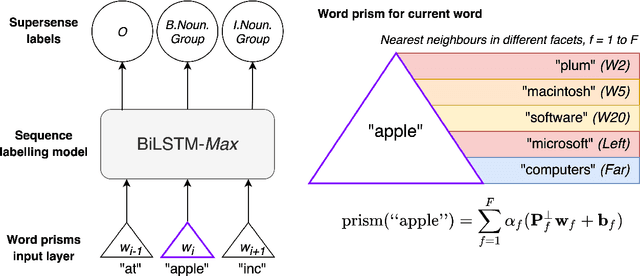
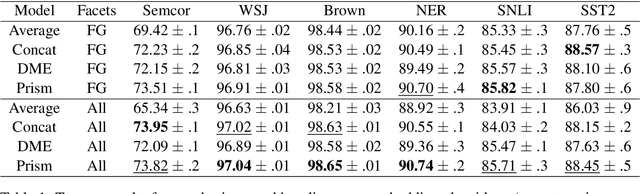
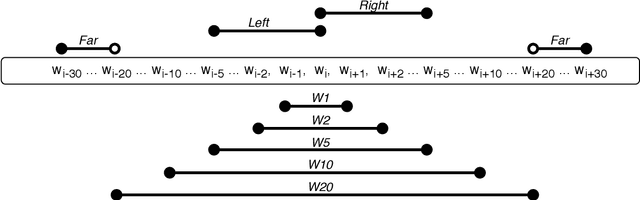

Word embeddings are trained to predict word cooccurrence statistics, which leads them to possess different lexical properties (syntactic, semantic, etc.) depending on the notion of context defined at training time. These properties manifest when querying the embedding space for the most similar vectors, and when used at the input layer of deep neural networks trained to solve downstream NLP problems. Meta-embeddings combine multiple sets of differently trained word embeddings, and have been shown to successfully improve intrinsic and extrinsic performance over equivalent models which use just one set of source embeddings. We introduce word prisms: a simple and efficient meta-embedding method that learns to combine source embeddings according to the task at hand. Word prisms learn orthogonal transformations to linearly combine the input source embeddings, which allows them to be very efficient at inference time. We evaluate word prisms in comparison to other meta-embedding methods on six extrinsic evaluations and observe that word prisms offer improvements in performance on all tasks.
An ensemble learning framework based on group decision making
Jul 01, 2020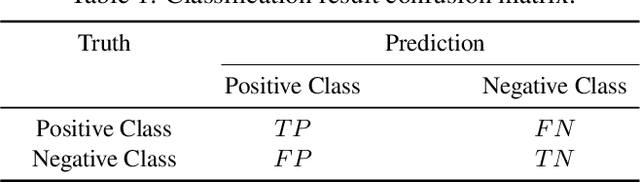
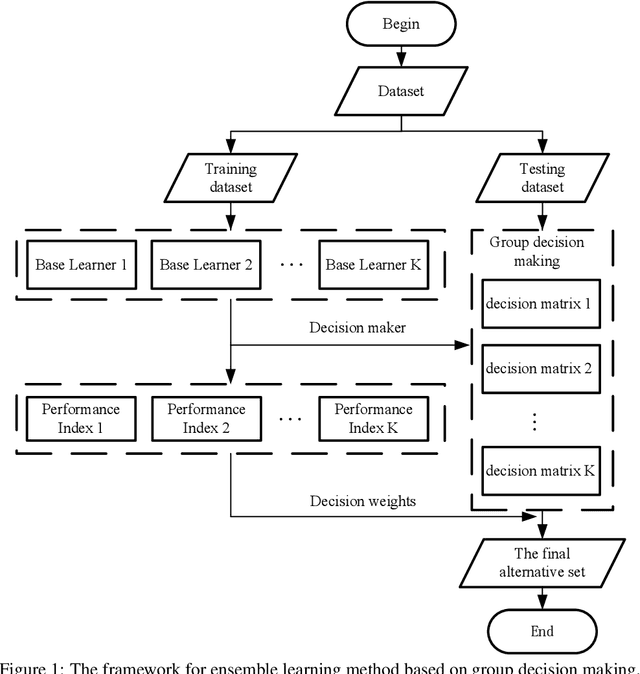
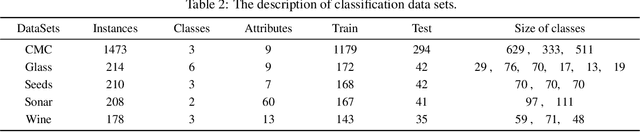
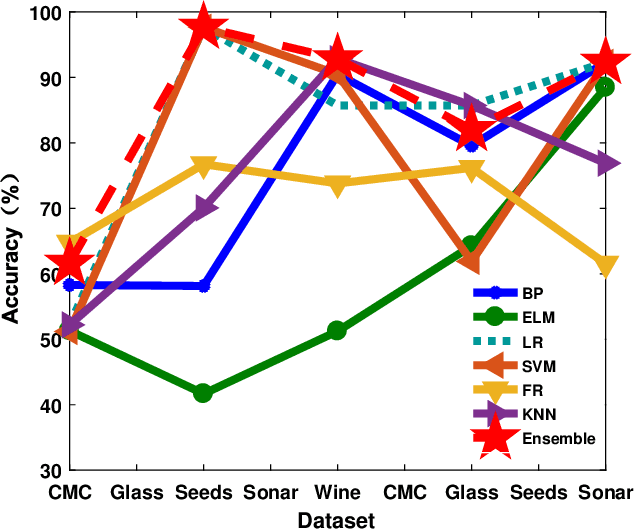
The classification problem is a significant topic in machine learning which aims to teach machines how to group together data by particular criteria. In this paper, a framework for the ensemble learning (EL) method based on group decision making (GDM) has been proposed to resolve this issue. In this framework, base learners can be considered as decision-makers, different categories can be seen as alternatives, classification results obtained by diverse base learners can be considered as performance ratings, and the precision, recall, and accuracy which can reflect the performances of the classification methods can be employed to identify the weights of decision-makers in GDM. Moreover, considering that the precision and recall defined in binary classification problems can not be used directly in the multi-classification problem, the One vs Rest (OvR) has been proposed to obtain the precision and recall of the base learner for each category. The experimental results demonstrate that the proposed EL method based on GDM has higher accuracy than other 6 current popular classification methods in most instances, which verifies the effectiveness of the proposed method.