 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond task performance: Decoding bioacoustic embeddings with speech features
Jun 12, 2026Pretrained audio embeddings are standard in bioacoustics, yet little is known about which acoustic features these models encode, nor which are useful for a given task. This hinders transparency and limits extension to rare species or data-scarce domains. Here we reveal which speech-like features are encoded in bioacoustic representations. Using the 88~eGeMAPS features across six taxonomic groups, we apply linear and nonlinear regression probes to quantify which acoustic properties each model captures. Results confirm a ``no free lunch'' pattern: no single model captures the full feature space. A concatenated embedding achieves the highest performance, suggesting complementary acoustic space coverage across models. Loudness features are best encoded ($R^2 = 0.76$) while F0 is hardest to recover ($R^2 = 0.33$). By cross-referencing recoverability with per-species feature salience (NMI), we derive data-driven model selection guidance for bioacoustics.
Multi-layer attentive probing improves transfer of audio representations for bioacoustics
May 11, 2026Probing heads map the representations learned from audio by a machine learning model to downstream task labels and are a key component in evaluating representation learning. Most bioacoustic benchmarks use a fixed, low-capacity probe, such as a linear layer on the final encoder layer. While this standardization enables model comparisons, it may bias results by overlooking the interaction between encoder features and probe design. In this work, we systematically study different probing strategies across two bioacoustic benchmarks, BEANs and BirdSet. We evaluate last- and multi-layer probing, across linear and attention probes. We show that larger probe heads that leverage time information have superior performance. Our results suggest that current benchmarks may misrepresent encoder quality when relying on a last-layer probing setup. Multi-layer probing improves downstream task performance across all tested models, while attention probing has superior performance to linear probing for transformer models.
On Leakage of Code Generation Evaluation Datasets
Jul 11, 2024



In this paper we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them: (i) direct data leakage, (ii) indirect data leakage through the use of synthetic data and (iii) overfitting to evaluation sets during model selection. Key to our findings is a new dataset of 161 prompts with their associated python solutions, dataset which is released at https://huggingface.co/datasets/CohereForAI/lbpp .
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
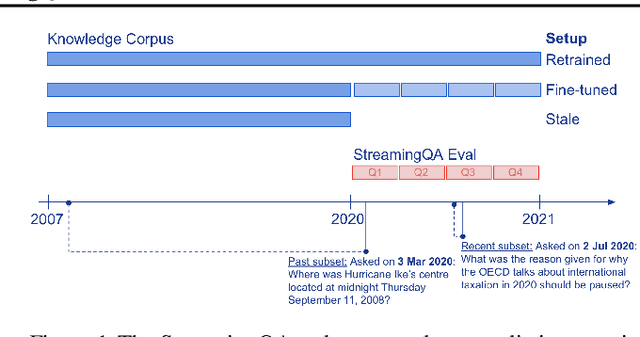

Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.