 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022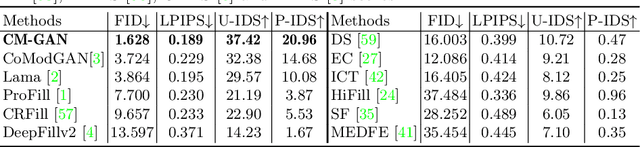
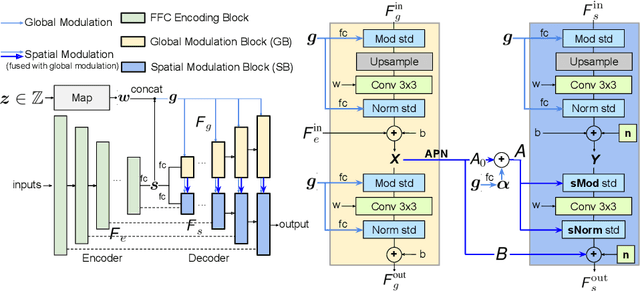
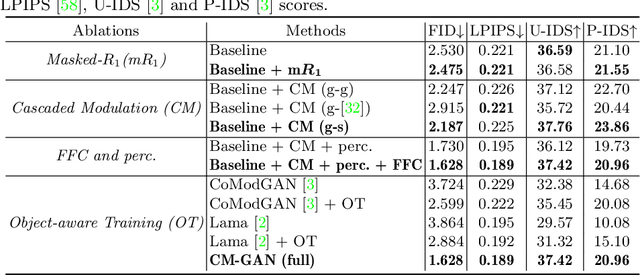

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
InsetGAN for Full-Body Image Generation
Mar 14, 2022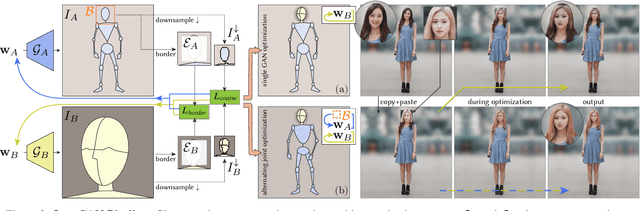



While GANs can produce photo-realistic images in ideal conditions for certain domains, the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose. Instead of modeling this complex domain with a single GAN, we propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas. We model the problem as jointly exploring the respective latent spaces such that the generated images can be combined, by inserting the parts from the specialized generators onto the global canvas, without introducing seams. We demonstrate the setup by combining a full body GAN with a dedicated high-quality face GAN to produce plausible-looking humans. We evaluate our results with quantitative metrics and user studies.
Collaging Class-specific GANs for Semantic Image Synthesis
Oct 08, 2021
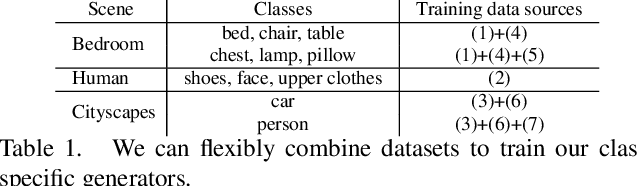
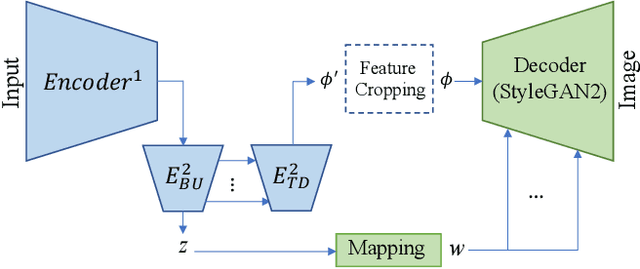
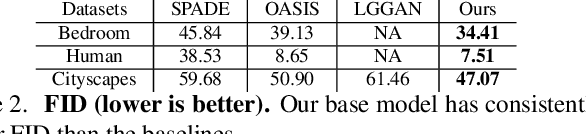
We propose a new approach for high resolution semantic image synthesis. It consists of one base image generator and multiple class-specific generators. The base generator generates high quality images based on a segmentation map. To further improve the quality of different objects, we create a bank of Generative Adversarial Networks (GANs) by separately training class-specific models. This has several benefits including -- dedicated weights for each class; centrally aligned data for each model; additional training data from other sources, potential of higher resolution and quality; and easy manipulation of a specific object in the scene. Experiments show that our approach can generate high quality images in high resolution while having flexibility of object-level control by using class-specific generators.
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
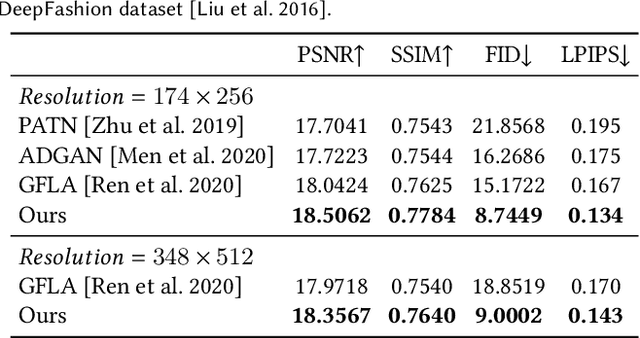


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Few-shot Image Generation via Cross-domain Correspondence
Apr 13, 2021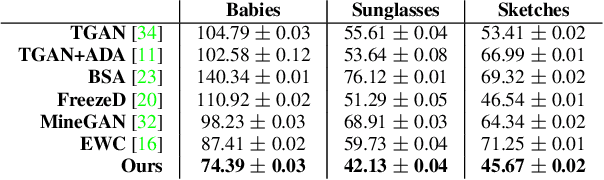

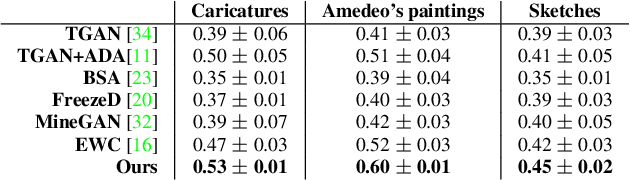
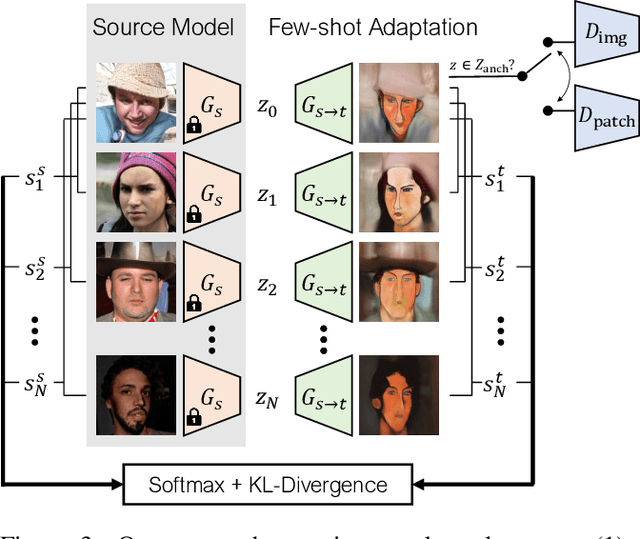
Training generative models, such as GANs, on a target domain containing limited examples (e.g., 10) can easily result in overfitting. In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target. We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss. To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space. With extensive results in both photorealistic and non-photorealistic domains, we demonstrate qualitatively and quantitatively that our few-shot model automatically discovers correspondences between source and target domains and generates more diverse and realistic images than previous methods.
IMAGINE: Image Synthesis by Image-Guided Model Inversion
Apr 13, 2021
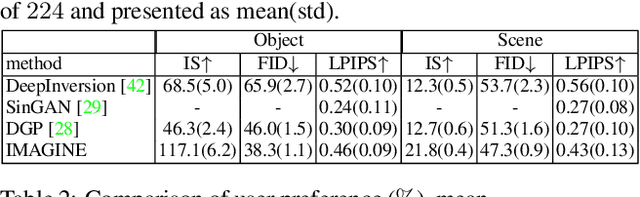

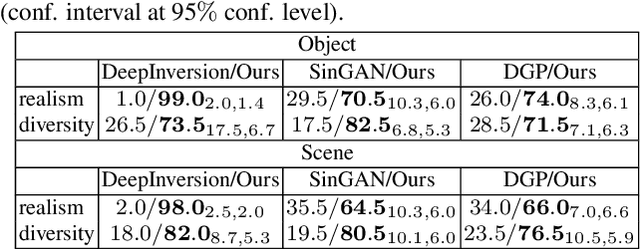
We introduce an inversion based method, denoted as IMAge-Guided model INvErsion (IMAGINE), to generate high-quality and diverse images from only a single training sample. We leverage the knowledge of image semantics from a pre-trained classifier to achieve plausible generations via matching multi-level feature representations in the classifier, associated with adversarial training with an external discriminator. IMAGINE enables the synthesis procedure to simultaneously 1) enforce semantic specificity constraints during the synthesis, 2) produce realistic images without generator training, and 3) give users intuitive control over the generation process. With extensive experimental results, we demonstrate qualitatively and quantitatively that IMAGINE performs favorably against state-of-the-art GAN-based and inversion-based methods, across three different image domains (i.e., objects, scenes, and textures).
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
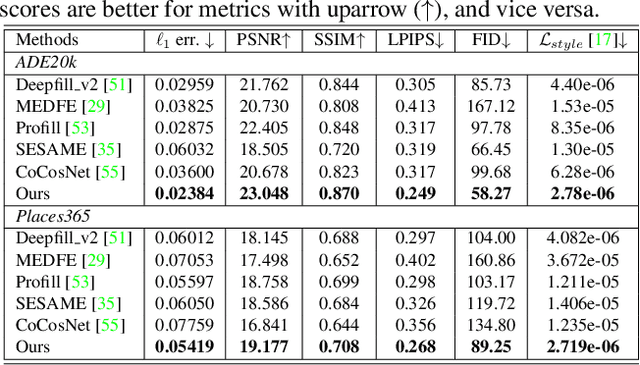
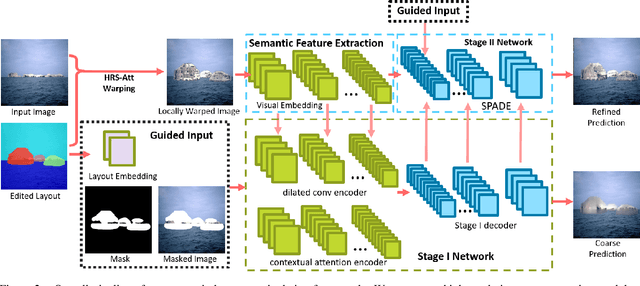
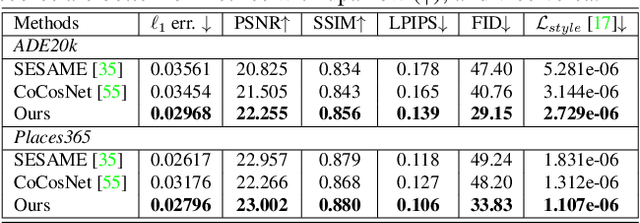
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
Few-shot Image Generation with Elastic Weight Consolidation
Dec 04, 2020

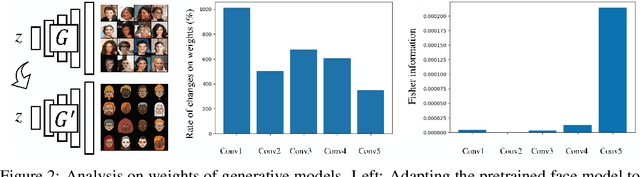
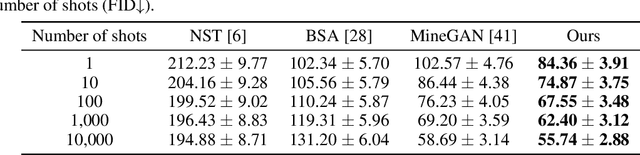
Few-shot image generation seeks to generate more data of a given domain, with only few available training examples. As it is unreasonable to expect to fully infer the distribution from just a few observations (e.g., emojis), we seek to leverage a large, related source domain as pretraining (e.g., human faces). Thus, we wish to preserve the diversity of the source domain, while adapting to the appearance of the target. We adapt a pretrained model, without introducing any additional parameters, to the few examples of the target domain. Crucially, we regularize the changes of the weights during this adaptation, in order to best preserve the information of the source dataset, while fitting the target. We demonstrate the effectiveness of our algorithm by generating high-quality results of different target domains, including those with extremely few examples (e.g., <10). We also analyze the performance of our method with respect to some important factors, such as the number of examples and the dissimilarity between the source and target domain.
Unselfie: Translating Selfies to Neutral-pose Portraits in the Wild
Jul 29, 2020

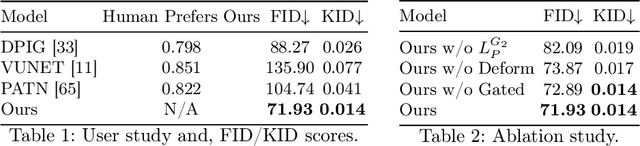
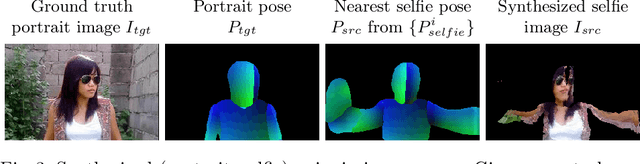
Due to the ubiquity of smartphones, it is popular to take photos of one's self, or "selfies." Such photos are convenient to take, because they do not require specialized equipment or a third-party photographer. However, in selfies, constraints such as human arm length often make the body pose look unnatural. To address this issue, we introduce $\textit{unselfie}$, a novel photographic transformation that automatically translates a selfie into a neutral-pose portrait. To achieve this, we first collect an unpaired dataset, and introduce a way to synthesize paired training data for self-supervised learning. Then, to $\textit{unselfie}$ a photo, we propose a new three-stage pipeline, where we first find a target neutral pose, inpaint the body texture, and finally refine and composite the person on the background. To obtain a suitable target neutral pose, we propose a novel nearest pose search module that makes the reposing task easier and enables the generation of multiple neutral-pose results among which users can choose the best one they like. Qualitative and quantitative evaluations show the superiority of our pipeline over alternatives.
Modeling Artistic Workflows for Image Generation and Editing
Jul 14, 2020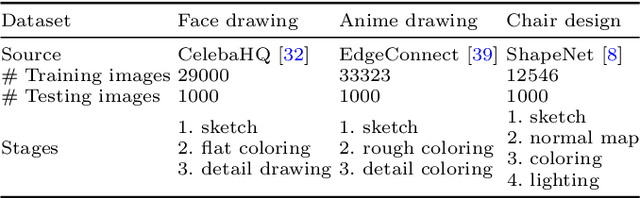
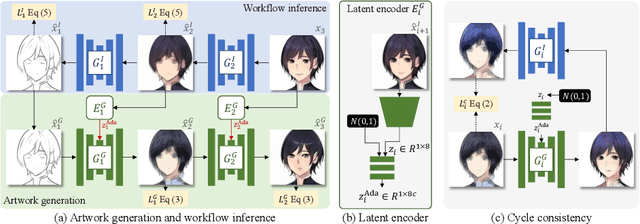
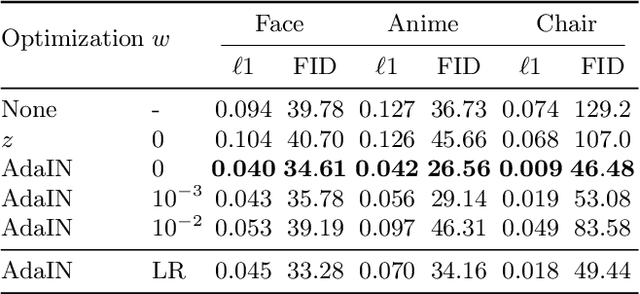

People often create art by following an artistic workflow involving multiple stages that inform the overall design. If an artist wishes to modify an earlier decision, significant work may be required to propagate this new decision forward to the final artwork. Motivated by the above observations, we propose a generative model that follows a given artistic workflow, enabling both multi-stage image generation as well as multi-stage image editing of an existing piece of art. Furthermore, for the editing scenario, we introduce an optimization process along with learning-based regularization to ensure the edited image produced by the model closely aligns with the originally provided image. Qualitative and quantitative results on three different artistic datasets demonstrate the effectiveness of the proposed framework on both image generation and editing tasks.