 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETA: Denoised Task Adaptation for Few-Shot Learning
Mar 11, 2023Test-time task adaptation in few-shot learning aims to adapt a pre-trained task-agnostic model for capturing taskspecific knowledge of the test task, rely only on few-labeled support samples. Previous approaches generally focus on developing advanced algorithms to achieve the goal, while neglecting the inherent problems of the given support samples. In fact, with only a handful of samples available, the adverse effect of either the image noise (a.k.a. X-noise) or the label noise (a.k.a. Y-noise) from support samples can be severely amplified. To address this challenge, in this work we propose DEnoised Task Adaptation (DETA), a first, unified image- and label-denoising framework orthogonal to existing task adaptation approaches. Without extra supervision, DETA filters out task-irrelevant, noisy representations by taking advantage of both global visual information and local region details of support samples. On the challenging Meta-Dataset, DETA consistently improves the performance of a broad spectrum of baseline methods applied on various pre-trained models. Notably, by tackling the overlooked image noise in Meta-Dataset, DETA establishes new state-of-the-art results. Code is released at https://github.com/nobody-1617/DETA.
A Closer Look at Few-shot Classification Again
Feb 02, 2023



Few-shot classification consists of a training phase where a model is learned on a relatively large dataset and an adaptation phase where the learned model is adapted to previously-unseen tasks with limited labeled samples. In this paper, we empirically prove that the training algorithm and the adaptation algorithm can be completely disentangled, which allows algorithm analysis and design to be done individually for each phase. Our meta-analysis for each phase reveals several interesting insights that may help better understand key aspects of few-shot classification and connections with other fields such as visual representation learning and transfer learning. We hope the insights and research challenges revealed in this paper can inspire future work in related directions.
Hyperbolic Hierarchical Contrastive Hashing
Dec 17, 2022Hierarchical semantic structures, naturally existing in real-world datasets, can assist in capturing the latent distribution of data to learn robust hash codes for retrieval systems. Although hierarchical semantic structures can be simply expressed by integrating semantically relevant data into a high-level taxon with coarser-grained semantics, the construction, embedding, and exploitation of the structures remain tricky for unsupervised hash learning. To tackle these problems, we propose a novel unsupervised hashing method named Hyperbolic Hierarchical Contrastive Hashing (HHCH). We propose to embed continuous hash codes into hyperbolic space for accurate semantic expression since embedding hierarchies in hyperbolic space generates less distortion than in hyper-sphere space and Euclidean space. In addition, we extend the K-Means algorithm to hyperbolic space and perform the proposed hierarchical hyperbolic K-Means algorithm to construct hierarchical semantic structures adaptively. To exploit the hierarchical semantic structures in hyperbolic space, we designed the hierarchical contrastive learning algorithm, including hierarchical instance-wise and hierarchical prototype-wise contrastive learning. Extensive experiments on four benchmark datasets demonstrate that the proposed method outperforms the state-of-the-art unsupervised hashing methods. Codes will be released.
Progressive Tree-Structured Prototype Network for End-to-End Image Captioning
Nov 17, 2022Studies of image captioning are shifting towards a trend of a fully end-to-end paradigm by leveraging powerful visual pre-trained models and transformer-based generation architecture for more flexible model training and faster inference speed. State-of-the-art approaches simply extract isolated concepts or attributes to assist description generation. However, such approaches do not consider the hierarchical semantic structure in the textual domain, which leads to an unpredictable mapping between visual representations and concept words. To this end, we propose a novel Progressive Tree-Structured prototype Network (dubbed PTSN), which is the first attempt to narrow down the scope of prediction words with appropriate semantics by modeling the hierarchical textual semantics. Specifically, we design a novel embedding method called tree-structured prototype, producing a set of hierarchical representative embeddings which capture the hierarchical semantic structure in textual space. To utilize such tree-structured prototypes into visual cognition, we also propose a progressive aggregation module to exploit semantic relationships within the image and prototypes. By applying our PTSN to the end-to-end captioning framework, extensive experiments conducted on MSCOCO dataset show that our method achieves a new state-of-the-art performance with 144.2% (single model) and 146.5% (ensemble of 4 models) CIDEr scores on `Karpathy' split and 141.4% (c5) and 143.9% (c40) CIDEr scores on the official online test server. Trained models and source code have been released at: https://github.com/NovaMind-Z/PTSN.
Learning Dual-Fused Modality-Aware Representations for RGBD Tracking
Nov 15, 2022



With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.
A Lower Bound of Hash Codes' Performance
Oct 12, 2022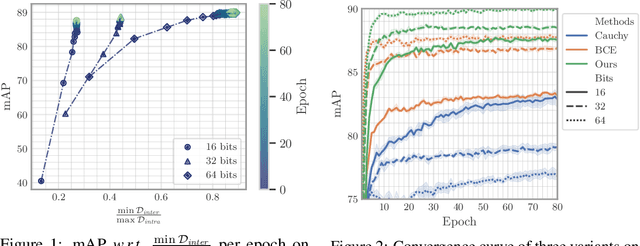
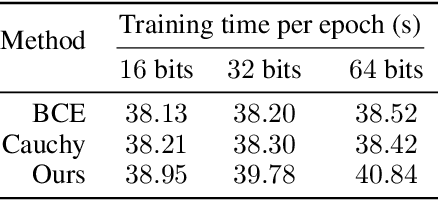
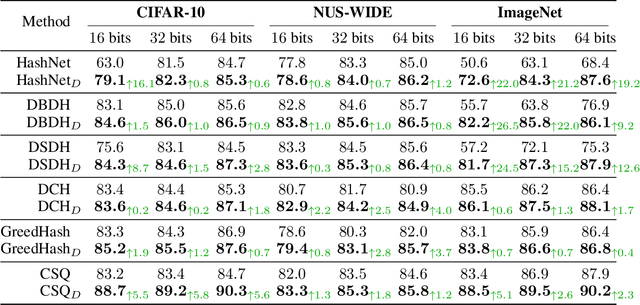
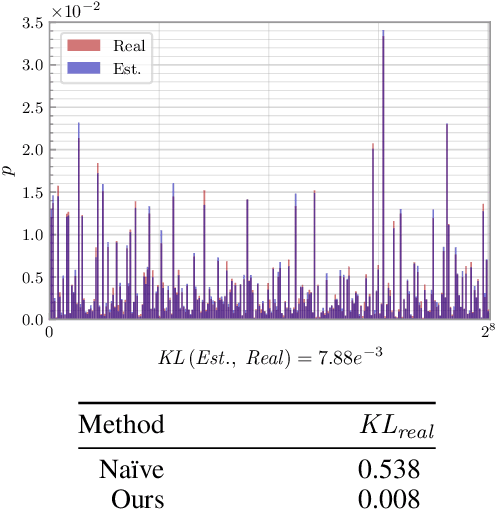
As a crucial approach for compact representation learning, hashing has achieved great success in effectiveness and efficiency. Numerous heuristic Hamming space metric learning objectives are designed to obtain high-quality hash codes. Nevertheless, a theoretical analysis of criteria for learning good hash codes remains largely unexploited. In this paper, we prove that inter-class distinctiveness and intra-class compactness among hash codes determine the lower bound of hash codes' performance. Promoting these two characteristics could lift the bound and improve hash learning. We then propose a surrogate model to fully exploit the above objective by estimating the posterior of hash codes and controlling it, which results in a low-bias optimization. Extensive experiments reveal the effectiveness of the proposed method. By testing on a series of hash-models, we obtain performance improvements among all of them, with an up to $26.5\%$ increase in mean Average Precision and an up to $20.5\%$ increase in accuracy. Our code is publicly available at \url{https://github.com/VL-Group/LBHash}.
Natural Color Fool: Towards Boosting Black-box Unrestricted Attacks
Oct 05, 2022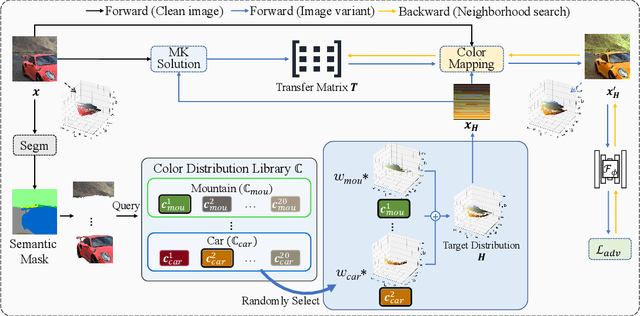
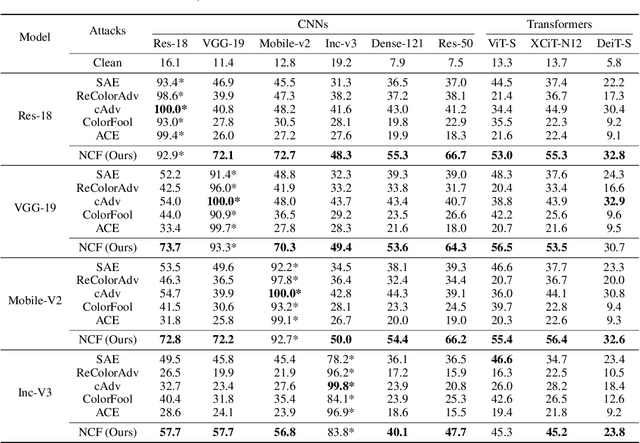

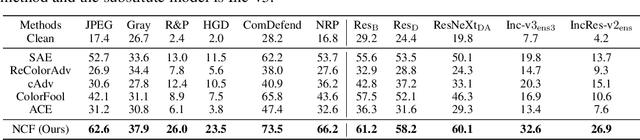
Unrestricted color attacks, which manipulate semantically meaningful color of an image, have shown their stealthiness and success in fooling both human eyes and deep neural networks. However, current works usually sacrifice the flexibility of the uncontrolled setting to ensure the naturalness of adversarial examples. As a result, the black-box attack performance of these methods is limited. To boost transferability of adversarial examples without damaging image quality, we propose a novel Natural Color Fool (NCF) which is guided by realistic color distributions sampled from a publicly available dataset and optimized by our neighborhood search and initialization reset. By conducting extensive experiments and visualizations, we convincingly demonstrate the effectiveness of our proposed method. Notably, on average, results show that our NCF can outperform state-of-the-art approaches by 15.0%$\sim$32.9% for fooling normally trained models and 10.0%$\sim$25.3% for evading defense methods. Our code is available at https://github.com/ylhz/Natural-Color-Fool.
RepParser: End-to-End Multiple Human Parsing with Representative Parts
Aug 27, 2022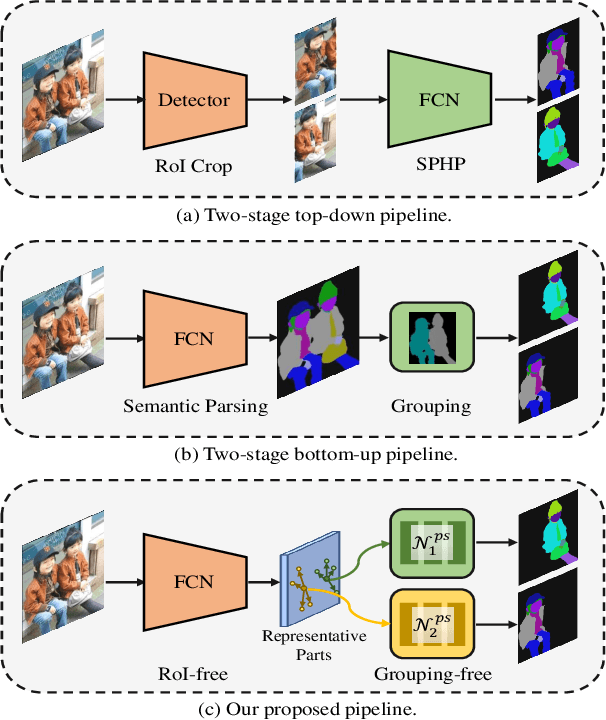
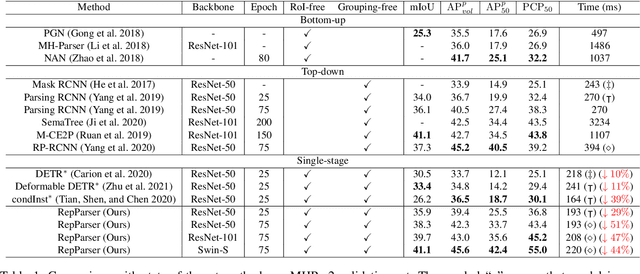
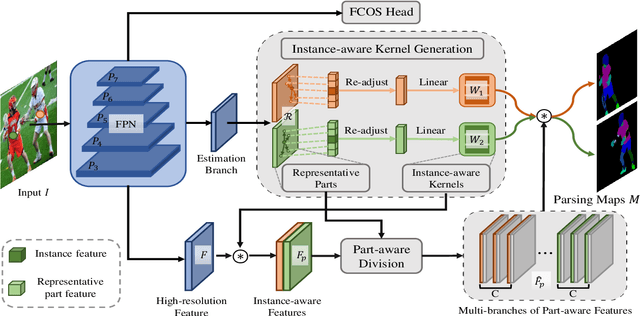
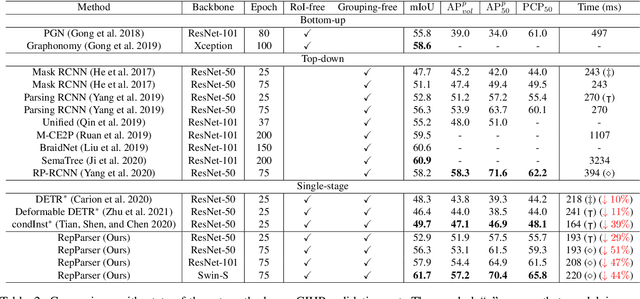
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.
Towards Open-vocabulary Scene Graph Generation with Prompt-based Finetuning
Aug 17, 2022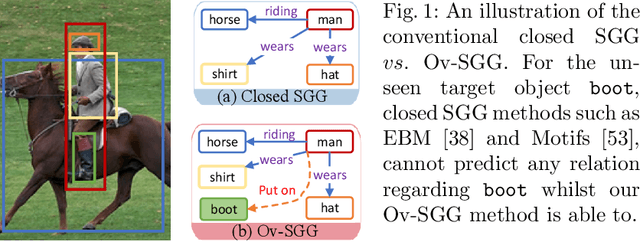
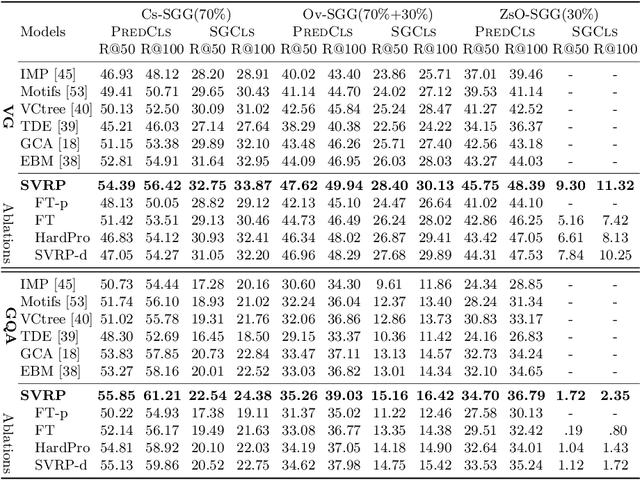
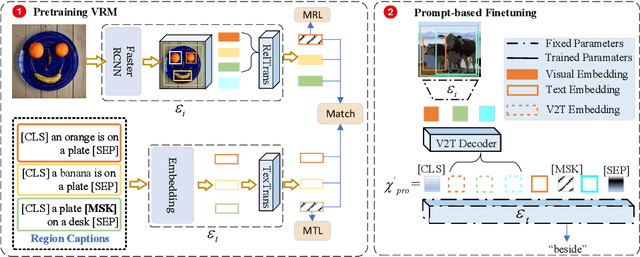
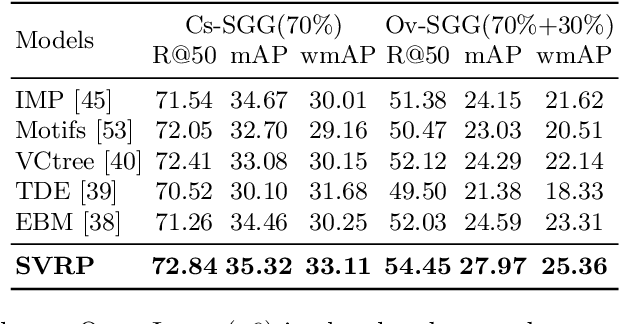
Scene graph generation (SGG) is a fundamental task aimed at detecting visual relations between objects in an image. The prevailing SGG methods require all object classes to be given in the training set. Such a closed setting limits the practical application of SGG. In this paper, we introduce open-vocabulary scene graph generation, a novel, realistic and challenging setting in which a model is trained on a set of base object classes but is required to infer relations for unseen target object classes. To this end, we propose a two-step method that firstly pre-trains on large amounts of coarse-grained region-caption data and then leverages two prompt-based techniques to finetune the pre-trained model without updating its parameters. Moreover, our method can support inference over completely unseen object classes, which existing methods are incapable of handling. On extensive experiments on three benchmark datasets, Visual Genome, GQA, and Open-Image, our method significantly outperforms recent, strong SGG methods on the setting of Ov-SGG, as well as on the conventional closed SGG.
Prompting for Multi-Modal Tracking
Aug 01, 2022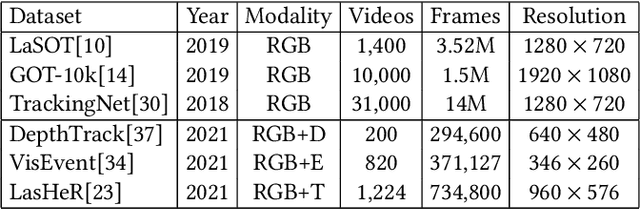
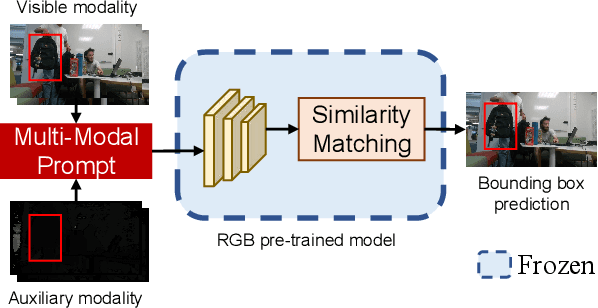
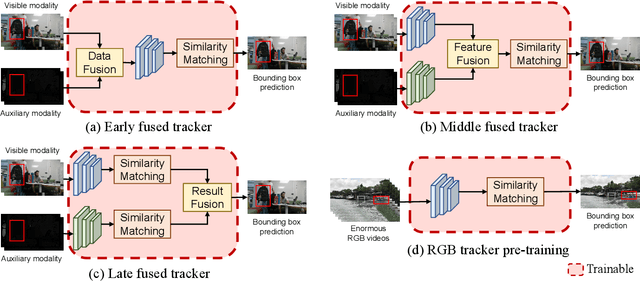
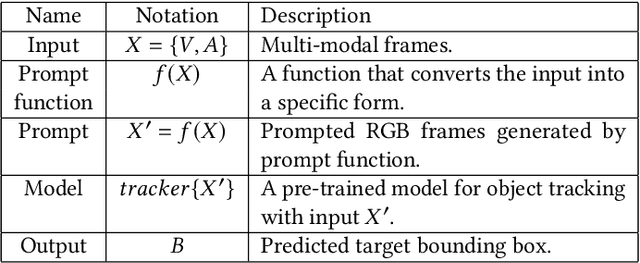
Multi-modal tracking gains attention due to its ability to be more accurate and robust in complex scenarios compared to traditional RGB-based tracking. Its key lies in how to fuse multi-modal data and reduce the gap between modalities. However, multi-modal tracking still severely suffers from data deficiency, thus resulting in the insufficient learning of fusion modules. Instead of building such a fusion module, in this paper, we provide a new perspective on multi-modal tracking by attaching importance to the multi-modal visual prompts. We design a novel multi-modal prompt tracker (ProTrack), which can transfer the multi-modal inputs to a single modality by the prompt paradigm. By best employing the tracking ability of pre-trained RGB trackers learning at scale, our ProTrack can achieve high-performance multi-modal tracking by only altering the inputs, even without any extra training on multi-modal data. Extensive experiments on 5 benchmark datasets demonstrate the effectiveness of the proposed ProTrack.