 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop-Think-AutoRegress: Language Modeling with Latent Diffusion Planning
Feb 24, 2026The Stop-Think-AutoRegress Language Diffusion Model (STAR-LDM) integrates latent diffusion planning with autoregressive generation. Unlike conventional autoregressive language models limited to token-by-token decisions, STAR-LDM incorporates a "thinking" phase that pauses generation to refine a semantic plan through diffusion before continuing. This enables global planning in continuous space prior to committing to discrete tokens. Evaluations show STAR-LDM significantly outperforms similar-sized models on language understanding benchmarks and achieves $>70\%$ win rates in LLM-as-judge comparisons for narrative coherence and commonsense reasoning. The architecture also allows straightforward control through lightweight classifiers, enabling fine-grained steering of attributes without model retraining while maintaining better fluency-control trade-offs than specialized approaches.
Pre-training Large Memory Language Models with Internal and External Knowledge
May 21, 2025Neural language models are black-boxes -- both linguistic patterns and factual knowledge are distributed across billions of opaque parameters. This entangled encoding makes it difficult to reliably inspect, verify, or update specific facts. We propose a new class of language models, Large Memory Language Models (LMLM) with a pre-training recipe that stores factual knowledge in both internal weights and an external database. Our approach strategically masks externally retrieved factual values from the training loss, thereby teaching the model to perform targeted lookups rather than relying on memorization in model weights. Our experiments demonstrate that LMLMs achieve competitive performance compared to significantly larger, knowledge-dense LLMs on standard benchmarks, while offering the advantages of explicit, editable, and verifiable knowledge bases. This work represents a fundamental shift in how language models interact with and manage factual knowledge.
Calibration by Distribution Matching: Trainable Kernel Calibration Metrics
Oct 31, 2023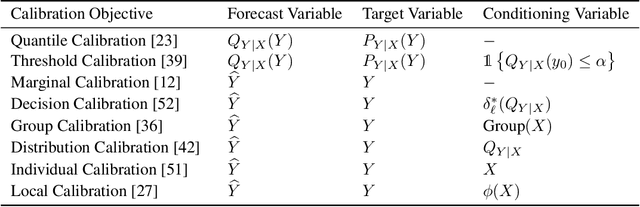



Calibration ensures that probabilistic forecasts meaningfully capture uncertainty by requiring that predicted probabilities align with empirical frequencies. However, many existing calibration methods are specialized for post-hoc recalibration, which can worsen the sharpness of forecasts. Drawing on the insight that calibration can be viewed as a distribution matching task, we introduce kernel-based calibration metrics that unify and generalize popular forms of calibration for both classification and regression. These metrics admit differentiable sample estimates, making it easy to incorporate a calibration objective into empirical risk minimization. Furthermore, we provide intuitive mechanisms to tailor calibration metrics to a decision task, and enforce accurate loss estimation and no regret decisions. Our empirical evaluation demonstrates that employing these metrics as regularizers enhances calibration, sharpness, and decision-making across a range of regression and classification tasks, outperforming methods relying solely on post-hoc recalibration.