 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Efficiency and Reliability for Continuous Mobile Manipulation
Apr 07, 2026Humans seamlessly fuse anticipatory planning with immediate feedback to perform successive mobile manipulation tasks without stopping, achieving both high efficiency and reliability. Replicating this fluid and reliable behavior in robots remains fundamentally challenging, not only due to conflicts between long-horizon planning and real-time reactivity, but also because excessively pursuing efficiency undermines reliability in uncertain environments: it impairs stable perception and the potential for compensation, while also increasing the risk of unintended contact. In this work, we present a unified framework that synergizes efficiency and reliability for continuous mobile manipulation. It features a reliability-aware trajectory planner that embeds essential elements for reliable execution into spatiotemporal optimization, generating efficient and reliability-promising global trajectories. It is coupled with a phase-dependent switching controller that seamlessly transitions between global trajectory tracking for efficiency and task-error compensation for reliability. We also investigate a hierarchical initialization that facilitates online replanning despite the complexity of long-horizon planning problems. Real-world evaluations demonstrate that our approach enables efficient and reliable completion of successive tasks under uncertainty (e.g., dynamic disturbances, perception and control errors). Moreover, the framework generalizes to tasks with diverse end-effector constraints. Compared with state-of-the-art baselines, our method consistently achieves the highest efficiency while improving the task success rate by 26.67\%--81.67\%. Comprehensive ablation studies further validate the contribution of each component. The source code will be released.
ADCrowdNet: An Attention-injective Deformable Convolutional Network for Crowd Understanding
Dec 04, 2018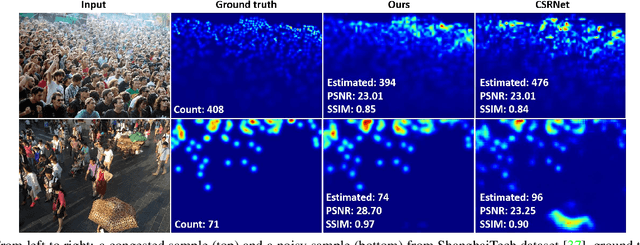
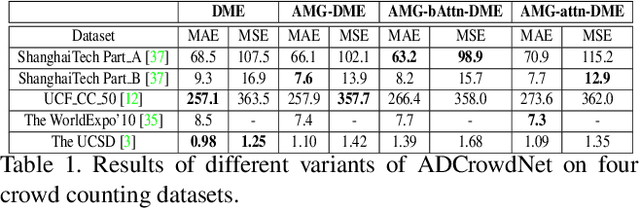

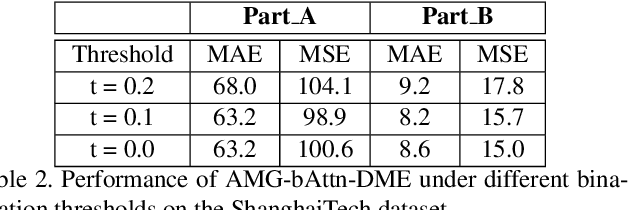
We propose an attention-injective deformable convolutional network called ADCrowdNet for crowd understanding that can address the accuracy degradation problem of highly congested noisy scenes. ADCrowdNet contains two concatenated networks. An attention-aware network called Attention Map Generator (AMG) first detects crowd regions in images and computes the congestion degree of these regions. Based on detected crowd regions and congestion priors, a multi-scale deformable network called Density Map Estimator (DME) then generates high-quality density maps. With the attention-aware training scheme and multi-scale deformable convolutional scheme, the proposed ADCrowdNet achieves the capability of being more effective to capture the crowd features and more resistant to various noises. We have evaluated our method on four popular crowd counting datasets (ShanghaiTech, UCF_CC_50, WorldEXPO'10, and UCSD) and an extra vehicle counting dataset TRANCOS, our approach overwhelmingly beats existing approaches on all of these datasets.