 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and backpropagation-free Green Learning for efficient multi-task echocardiographic segmentation and classification
Jan 27, 2026Echocardiography is a cornerstone for managing heart failure (HF), with Left Ventricular Ejection Fraction (LVEF) being a critical metric for guiding therapy. However, manual LVEF assessment suffers from high inter-observer variability, while existing Deep Learning (DL) models are often computationally intensive and data-hungry "black boxes" that impede clinical trust and adoption. Here, we propose a backpropagation-free multi-task Green Learning (MTGL) framework that performs simultaneous Left Ventricle (LV) segmentation and LVEF classification. Our framework integrates an unsupervised VoxelHop encoder for hierarchical spatio-temporal feature extraction with a multi-level regression decoder and an XG-Boost classifier. On the EchoNet-Dynamic dataset, our MTGL model achieves state-of-the-art classification and segmentation performance, attaining a classification accuracy of 94.3% and a Dice Similarity Coefficient (DSC) of 0.912, significantly outperforming several advanced 3D DL models. Crucially, our model achieves this with over an order of magnitude fewer parameters, demonstrating exceptional computational efficiency. This work demonstrates that the GL paradigm can deliver highly accurate, efficient, and interpretable solutions for complex medical image analysis, paving the way for more sustainable and trustworthy artificial intelligence in clinical practice.
Predicting Distance matrix with large language models
Sep 24, 2024Structural prediction has long been considered critical in RNA research, especially following the success of AlphaFold2 in protein studies, which has drawn significant attention to the field. While recent advances in machine learning and data accumulation have effectively addressed many biological tasks, particularly in protein related research. RNA structure prediction remains a significant challenge due to data limitations. Obtaining RNA structural data is difficult because traditional methods such as nuclear magnetic resonance spectroscopy, Xray crystallography, and electron microscopy are expensive and time consuming. Although several RNA 3D structure prediction methods have been proposed, their accuracy is still limited. Predicting RNA structural information at another level, such as distance maps, remains highly valuable. Distance maps provide a simplified representation of spatial constraints between nucleotides, capturing essential relationships without requiring a full 3D model. This intermediate level of structural information can guide more accurate 3D modeling and is computationally less intensive, making it a useful tool for improving structural predictions. In this work, we demonstrate that using only primary sequence information, we can accurately infer the distances between RNA bases by utilizing a large pretrained RNA language model coupled with a well trained downstream transformer.
Spatial Semantic Recurrent Mining for Referring Image Segmentation
May 15, 2024Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (S\textsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, S\textsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, S\textsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
Adaptive Multi-source Predictor for Zero-shot Video Object Segmentation
Mar 18, 2023Both static and moving objects usually exist in real-life videos. Most video object segmentation methods only focus on exacting and exploiting motion cues to perceive moving objects. Once faced with static objects frames, moving object predictors may predict failed results caused by uncertain motion information, such as low-quality optical flow maps. Besides, many sources such as RGB, depth, optical flow and static saliency can provide useful information about the objects. However, existing approaches only utilize the RGB or RGB and optical flow. In this paper, we propose a novel adaptive multi-source predictor for zero-shot video object segmentation. In the static object predictor, the RGB source is converted to depth and static saliency sources, simultaneously. In the moving object predictor, we propose the multi-source fusion structure. First, the spatial importance of each source is highlighted with the help of the interoceptive spatial attention module (ISAM). Second, the motion-enhanced module (MEM) is designed to generate pure foreground motion attention for improving both static and moving features used in the decoder. Furthermore, we design a feature purification module (FPM) to filter the inter-source incompatible features. By the ISAM, MEM and FPM, the multi-source features are effectively fused. In addition, we put forward an adaptive predictor fusion network (APF) to evaluate the quality of optical flow and fuse the predictions from the static object predictor and the moving object predictor in order to prevent over-reliance on the failed results caused by low-quality optical flow maps. Experiments show that the proposed model outperforms the state-of-the-art methods on three challenging ZVOS benchmarks. And, the static object predictor can precisely predicts a high-quality depth map and static saliency map at the same time.
Lane Detection with Versatile AtrousFormer and Local Semantic Guidance
Mar 08, 2022
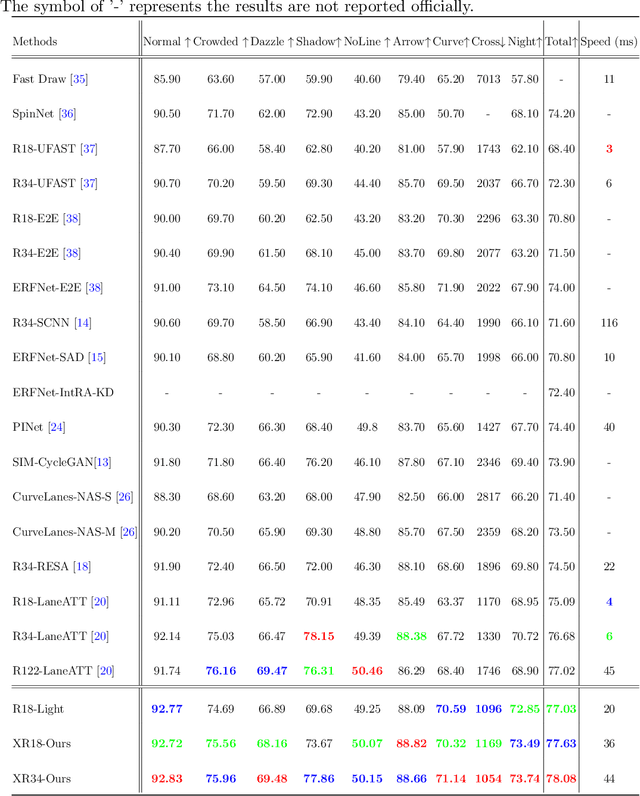
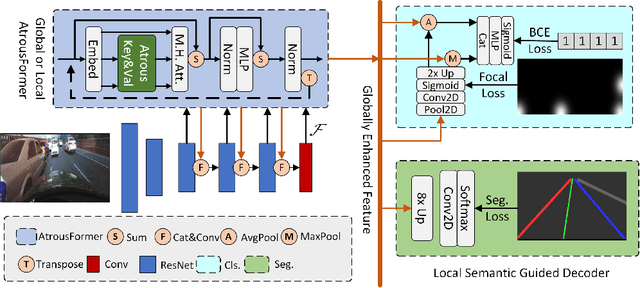
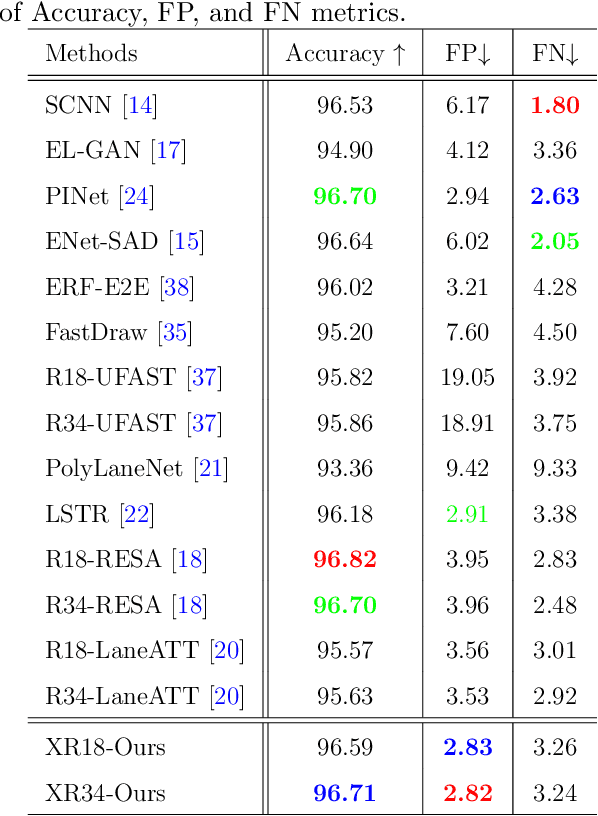
Lane detection is one of the core functions in autonomous driving and has aroused widespread attention recently. The networks to segment lane instances, especially with bad appearance, must be able to explore lane distribution properties. Most existing methods tend to resort to CNN-based techniques. A few have a try on incorporating the recent adorable, the seq2seq Transformer \cite{transformer}. However, their innate drawbacks of weak global information collection ability and exorbitant computation overhead prohibit a wide range of the further applications. In this work, we propose Atrous Transformer (AtrousFormer) to solve the problem. Its variant local AtrousFormer is interleaved into feature extractor to enhance extraction. Their collecting information first by rows and then by columns in a dedicated manner finally equips our network with stronger information gleaning ability and better computation efficiency. To further improve the performance, we also propose a local semantic guided decoder to delineate the identities and shapes of lanes more accurately, in which the predicted Gaussian map of the starting point of each lane serves to guide the process. Extensive results on three challenging benchmarks (CULane, TuSimple, and BDD100K) show that our network performs favorably against the state of the arts.
Multi-Source Fusion and Automatic Predictor Selection for Zero-Shot Video Object Segmentation
Aug 11, 2021

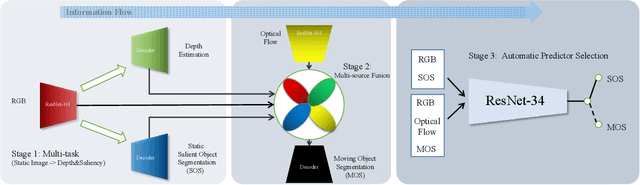
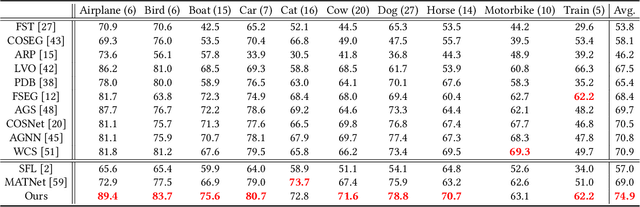
Location and appearance are the key cues for video object segmentation. Many sources such as RGB, depth, optical flow and static saliency can provide useful information about the objects. However, existing approaches only utilize the RGB or RGB and optical flow. In this paper, we propose a novel multi-source fusion network for zero-shot video object segmentation. With the help of interoceptive spatial attention module (ISAM), spatial importance of each source is highlighted. Furthermore, we design a feature purification module (FPM) to filter the inter-source incompatible features. By the ISAM and FPM, the multi-source features are effectively fused. In addition, we put forward an automatic predictor selection network (APS) to select the better prediction of either the static saliency predictor or the moving object predictor in order to prevent over-reliance on the failed results caused by low-quality optical flow maps. Extensive experiments on three challenging public benchmarks (i.e. DAVIS$_{16}$, Youtube-Objects and FBMS) show that the proposed model achieves compelling performance against the state-of-the-arts. The source code will be publicly available at \textcolor{red}{\url{https://github.com/Xiaoqi-Zhao-DLUT/Multi-Source-APS-ZVOS}}.