 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTET-GAN: Text Effects Transfer via Stylization and Destylization
Dec 27, 2018
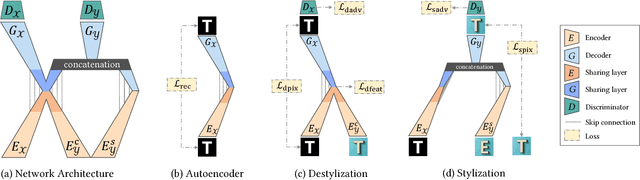


Text effects transfer technology automatically makes the text dramatically more impressive. However, previous style transfer methods either study the model for general style, which cannot handle the highly-structured text effects along the glyph, or require manual design of subtle matching criteria for text effects. In this paper, we focus on the use of the powerful representation abilities of deep neural features for text effects transfer. For this purpose, we propose a novel Texture Effects Transfer GAN (TET-GAN), which consists of a stylization subnetwork and a destylization subnetwork. The key idea is to train our network to accomplish both the objective of style transfer and style removal, so that it can learn to disentangle and recombine the content and style features of text effects images. To support the training of our network, we propose a new text effects dataset with as much as 64 professionally designed styles on 837 characters. We show that the disentangled feature representations enable us to transfer or remove all these styles on arbitrary glyphs using one network. Furthermore, the flexible network design empowers TET-GAN to efficiently extend to a new text style via one-shot learning where only one example is required. We demonstrate the superiority of the proposed method in generating high-quality stylized text over the state-of-the-art methods.
Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning
Dec 02, 2018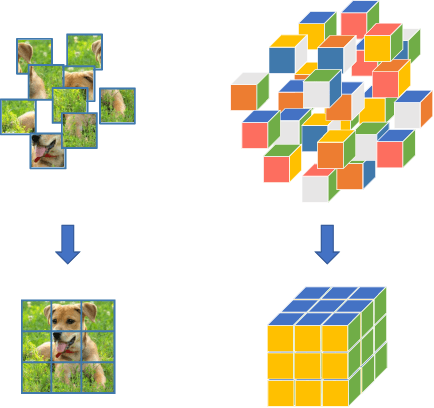
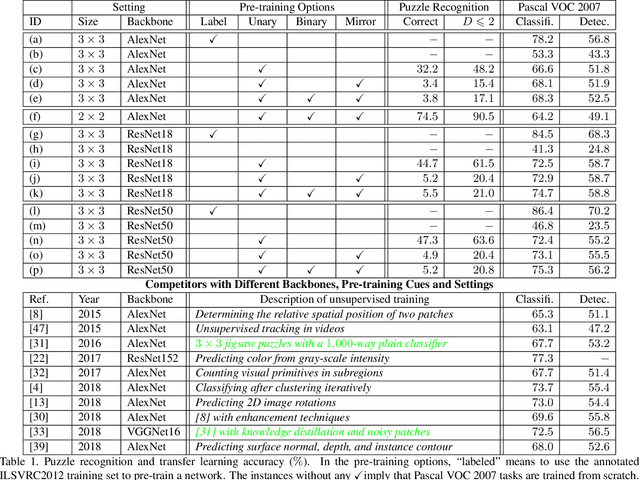
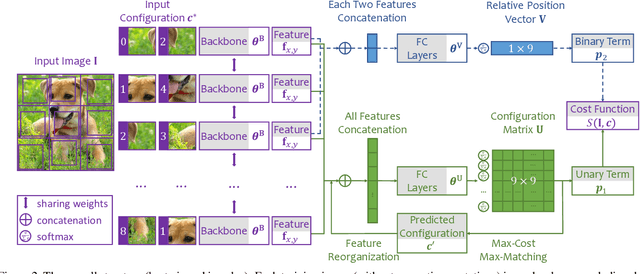
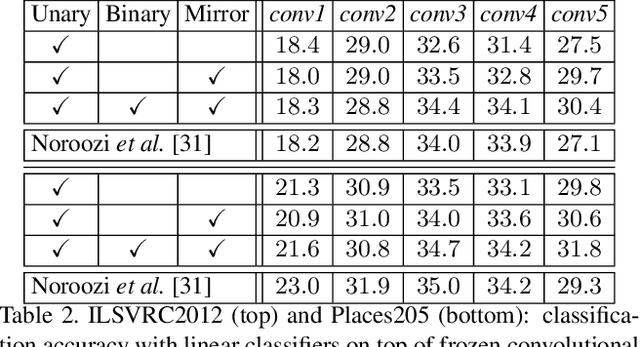
Learning visual features from unlabeled image data is an important yet challenging task, which is often achieved by training a model on some annotation-free information. We consider spatial contexts, for which we solve so-called jigsaw puzzles, i.e., each image is cut into grids and then disordered, and the goal is to recover the correct configuration. Existing approaches formulated it as a classification task by defining a fixed mapping from a small subset of configurations to a class set, but these approaches ignore the underlying relationship between different configurations and also limit their application to more complex scenarios. This paper presents a novel approach which applies to jigsaw puzzles with an arbitrary grid size and dimensionality. We provide a fundamental and generalized principle, that weaker cues are easier to be learned in an unsupervised manner and also transfer better. In the context of puzzle recognition, we use an iterative manner which, instead of solving the puzzle all at once, adjusts the order of the patches in each step until convergence. In each step, we combine both unary and binary features on each patch into a cost function judging the correctness of the current configuration. Our approach, by taking similarity between puzzles into consideration, enjoys a more reasonable way of learning visual knowledge. We verify the effectiveness of our approach in two aspects. First, it is able to solve arbitrarily complex puzzles, including high-dimensional puzzles, that prior methods are difficult to handle. Second, it serves as a reliable way of network initialization, which leads to better transfer performance in a few visual recognition tasks including image classification, object detection, and semantic segmentation.
Progressive Recurrent Learning for Visual Recognition
Nov 29, 2018
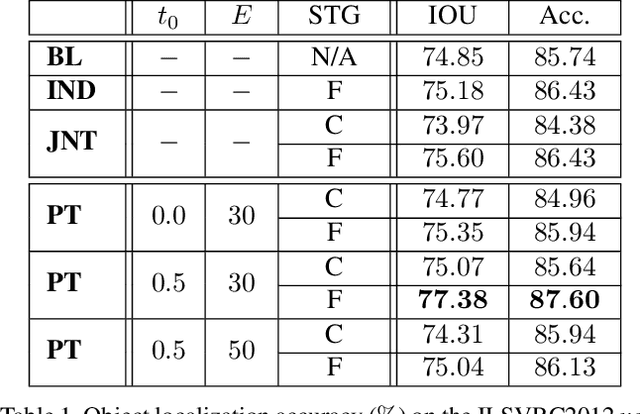

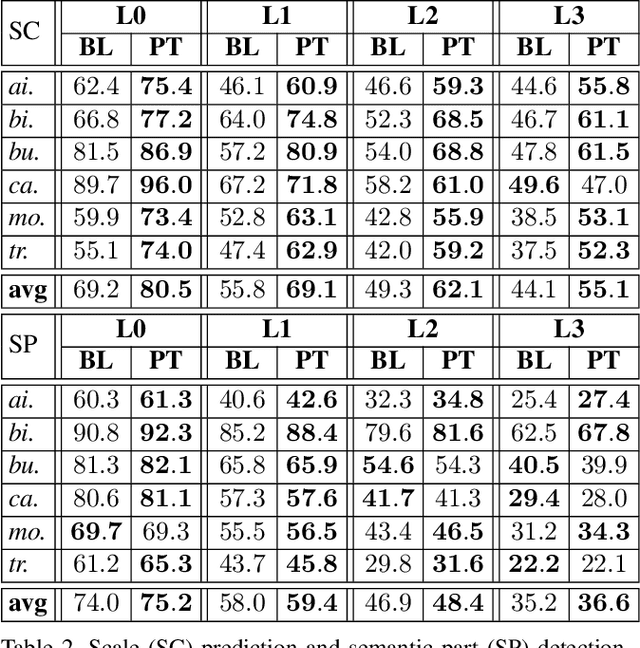
Computer vision is difficult, partly because the mathematical function connecting input and output data is often complex, fuzzy and thus hard to learn. A currently popular solution is to design a deep neural network and optimize it on a large-scale dataset. However, as the number of parameters increases, the generalization ability is often not guaranteed, e.g., the model can over-fit due to the limited amount of training data, or fail to converge because the desired function is too difficult to learn. This paper presents an effective framework named progressive recurrent learning (PRL). The core idea is similar to curriculum learning which gradually increases the difficulty of training data. We generalize it to a wide range of vision problems that were previously considered less proper to apply curriculum learning. PRL starts with inserting a recurrent prediction scheme, based on the motivation of feeding the prediction of a vision model to the same model iteratively, so that the auxiliary cues contained in it can be exploited to improve the quality of itself. In order to better optimize this framework, we start with providing perfect prediction, i.e., ground-truth, to the second stage, but gradually replace it with the prediction of the first stage. In the final status, the ground-truth information is not needed any more, so that the entire model works on the real data distribution as in the testing process. We apply PRL to two challenging visual recognition tasks, namely, object localization and semantic segmentation, and demonstrate consistent accuracy gain compared to the baseline training strategy, especially in the scenarios of more difficult vision tasks.
Generalized Graph Convolutional Networks for Skeleton-based Action Recognition
Nov 29, 2018

With the prevalence of accessible depth sensors, dynamic human body skeletons have attracted much attention as a robust modality for action recognition. Previous methods model skeletons based on RNN or CNN, which has limited expressive power for irregular joints. In this paper, we represent skeletons naturally on graphs and propose a generalized graph convolutional neural networks (GGCN) for skeleton-based action recognition, aiming to capture space-time variation via spectral graph theory. In particular, we construct a generalized graph over consecutive frames, where each joint is not only connected to its neighboring joints in the same frame strongly or weakly, but also linked with relevant joints in the previous and subsequent frames. The generalized graphs are then fed into GGCN along with the coordinate matrix of the skeleton sequence for feature learning, where we deploy high-order and fast Chebyshev approximation of spectral graph convolution in the network. Experiments show that we achieve the state-of-the-art performance on the widely used NTU RGB+D, UT-Kinect and SYSU 3D datasets.
Temporal Bilinear Networks for Video Action Recognition
Nov 25, 2018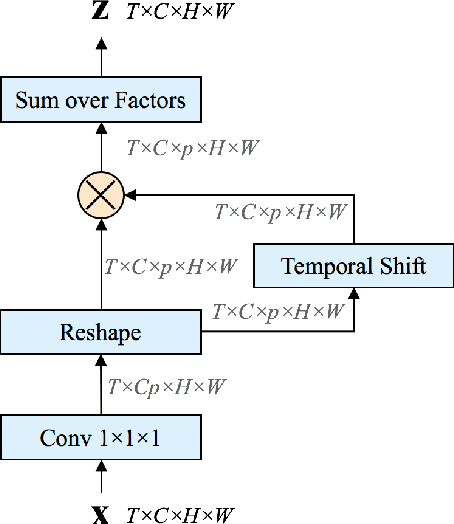

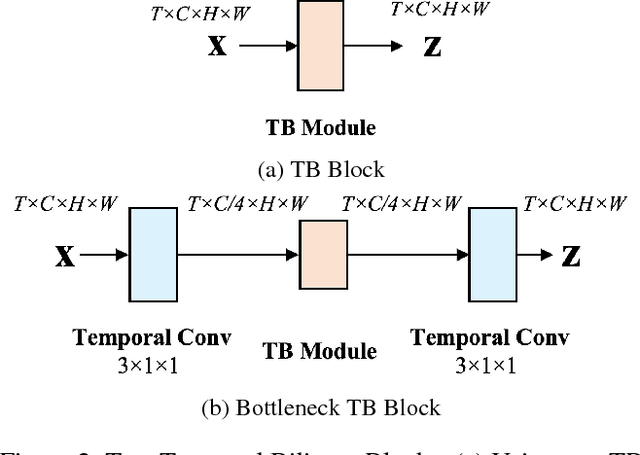

Temporal modeling in videos is a fundamental yet challenging problem in computer vision. In this paper, we propose a novel Temporal Bilinear (TB) model to capture the temporal pairwise feature interactions between adjacent frames. Compared with some existing temporal methods which are limited in linear transformations, our TB model considers explicit quadratic bilinear transformations in the temporal domain for motion evolution and sequential relation modeling. We further leverage the factorized bilinear model in linear complexity and a bottleneck network design to build our TB blocks, which also constrains the parameters and computation cost. We consider two schemes in terms of the incorporation of TB blocks and the original 2D spatial convolutions, namely wide and deep Temporal Bilinear Networks (TBN). Finally, we perform experiments on several widely adopted datasets including Kinetics, UCF101 and HMDB51. The effectiveness of our TBNs is validated by comprehensive ablation analyses and comparisons with various state-of-the-art methods.
Weakly Supervised Scene Parsing with Point-based Distance Metric Learning
Nov 06, 2018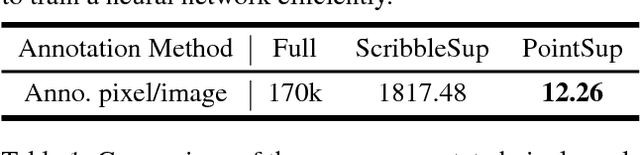

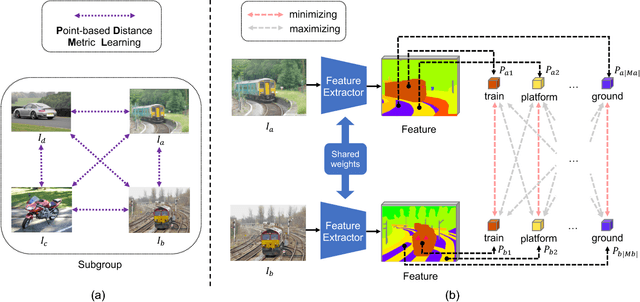
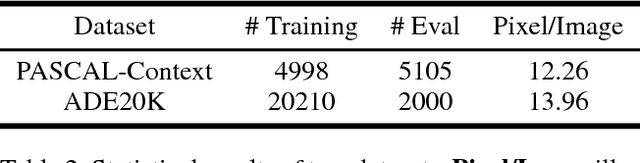
Semantic scene parsing is suffering from the fact that pixel-level annotations are hard to be collected. To tackle this issue, we propose a Point-based Distance Metric Learning (PDML) in this paper. PDML does not require dense annotated masks and only leverages several labeled points that are much easier to obtain to guide the training process. Concretely, we leverage semantic relationship among the annotated points by encouraging the feature representations of the intra- and inter-category points to keep consistent, i.e. points within the same category should have more similar feature representations compared to those from different categories. We formulate such a characteristic into a simple distance metric loss, which collaborates with the point-wise cross-entropy loss to optimize the deep neural networks. Furthermore, to fully exploit the limited annotations, distance metric learning is conducted across different training images instead of simply adopting an image-dependent manner. We conduct extensive experiments on two challenging scene parsing benchmarks of PASCAL-Context and ADE 20K to validate the effectiveness of our PDML, and competitive mIoU scores are achieved.
Dynamically Unfolding Recurrent Restorer: A Moving Endpoint Control Method for Image Restoration
Oct 10, 2018
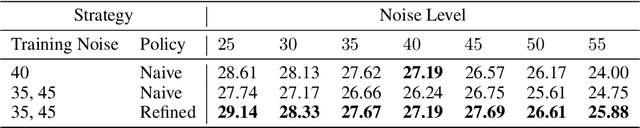
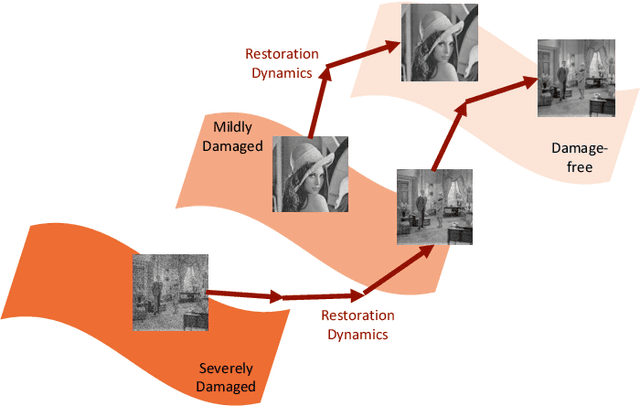
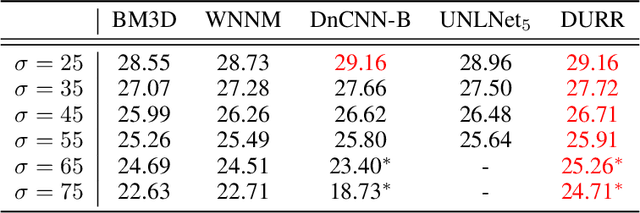
In this paper, we propose a new control framework called the moving endpoint control to restore images corrupted by different degradation levels in one model. The proposed control problem contains a restoration dynamics which is modeled by an RNN. The moving endpoint, which is essentially the terminal time of the associated dynamics, is determined by a policy network. We call the proposed model the dynamically unfolding recurrent restorer (DURR). Numerical experiments show that DURR is able to achieve state-of-the-art performances on blind image denoising and JPEG image deblocking. Furthermore, DURR can well generalize to images with higher degradation levels that are not included in the training stage.
Context-Aware Text-Based Binary Image Stylization and Synthesis
Oct 09, 2018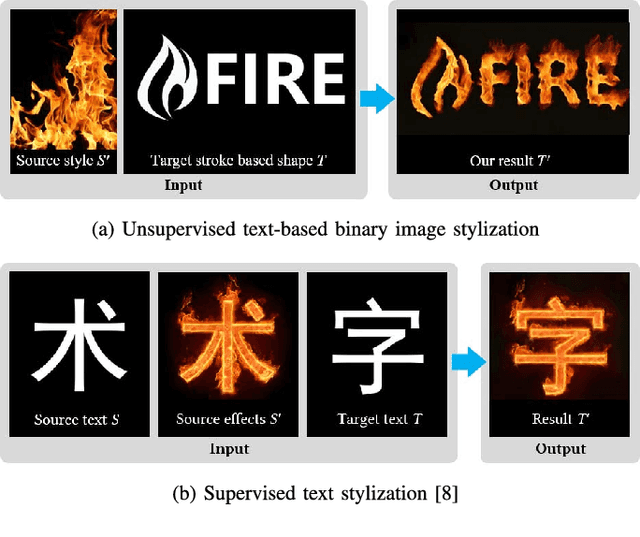



In this work, we present a new framework for the stylization of text-based binary images. First, our method stylizes the stroke-based geometric shape like text, symbols and icons in the target binary image based on an input style image. Second, the composition of the stylized geometric shape and a background image is explored. To accomplish the task, we propose legibility-preserving structure and texture transfer algorithms, which progressively narrow the visual differences between the binary image and the style image. The stylization is then followed by a context-aware layout design algorithm, where cues for both seamlessness and aesthetics are employed to determine the optimal layout of the shape in the background. Given the layout, the binary image is seamlessly embedded into the background by texture synthesis under a context-aware boundary constraint. According to the contents of binary images, our method can be applied to many fields. We show that the proposed method is capable of addressing the unsupervised text stylization problem and is superior to state-of-the-art style transfer methods in automatic artistic typography creation. Besides, extensive experiments on various tasks, such as visual-textual presentation synthesis, icon/symbol rendering and structure-guided image inpainting, demonstrate the effectiveness of the proposed method.
Deep Retinex Decomposition for Low-Light Enhancement
Aug 14, 2018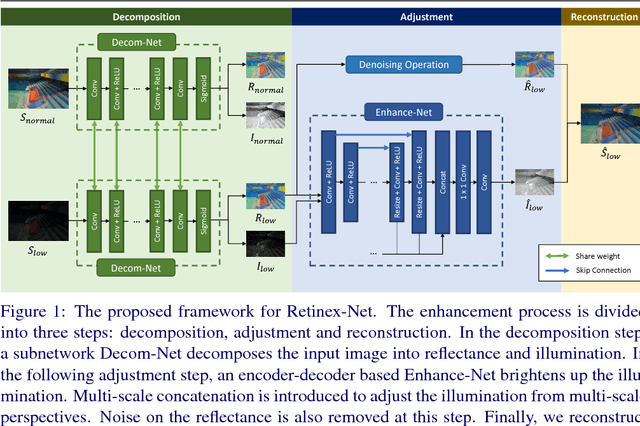


Retinex model is an effective tool for low-light image enhancement. It assumes that observed images can be decomposed into the reflectance and illumination. Most existing Retinex-based methods have carefully designed hand-crafted constraints and parameters for this highly ill-posed decomposition, which may be limited by model capacity when applied in various scenes. In this paper, we collect a LOw-Light dataset (LOL) containing low/normal-light image pairs and propose a deep Retinex-Net learned on this dataset, including a Decom-Net for decomposition and an Enhance-Net for illumination adjustment. In the training process for Decom-Net, there is no ground truth of decomposed reflectance and illumination. The network is learned with only key constraints including the consistent reflectance shared by paired low/normal-light images, and the smoothness of illumination. Based on the decomposition, subsequent lightness enhancement is conducted on illumination by an enhancement network called Enhance-Net, and for joint denoising there is a denoising operation on reflectance. The Retinex-Net is end-to-end trainable, so that the learned decomposition is by nature good for lightness adjustment. Extensive experiments demonstrate that our method not only achieves visually pleasing quality for low-light enhancement but also provides a good representation of image decomposition.
Progressive Spatial Recurrent Neural Network for Intra Prediction
Jul 06, 2018
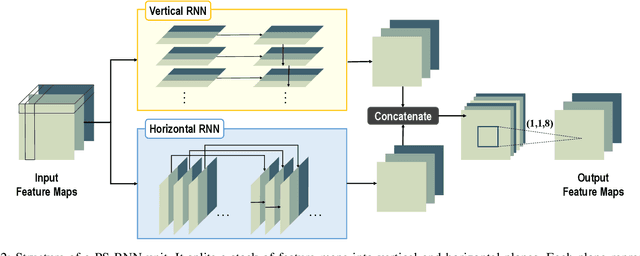

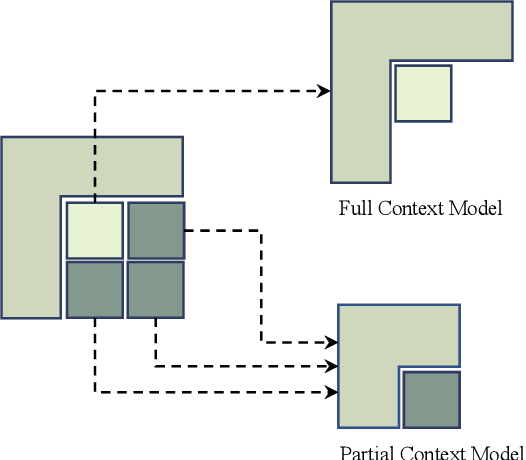
Intra prediction is an important component of modern video codecs, which is able to efficiently squeeze out the spatial redundancy in video frames. With preceding pixels as the context, traditional intra prediction schemes generate linear predictions based on several predefined directions (i.e. modes) for blocks to be encoded. However, these modes are relatively simple and their predictions may fail when facing blocks with complex textures, which leads to additional bits encoding the residue. In this paper, we design a Progressive Spatial Recurrent Neural Network (PS-RNN) that learns to conduct intra prediction. Specifically, our PS-RNN consists of three spatial recurrent units and progressively generates predictions by passing information along from preceding contents to blocks to be encoded. To make our network generate predictions considering both distortion and bit-rate, we propose to use Sum of Absolute Transformed Difference (SATD) as the loss function to train PS-RNN since SATD is able to measure rate-distortion cost of encoding a residue block. Moreover, our method supports variable-block-size for intra prediction, which is more practical in real coding conditions. The proposed intra prediction scheme achieves on average 2.4% bit-rate reduction on variable-block-size settings under the same reconstruction quality compared with HEVC.