 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Semantic Segmentation via Auto Depth, Downsampling Joint Decision and Feature Aggregation
Mar 31, 2020
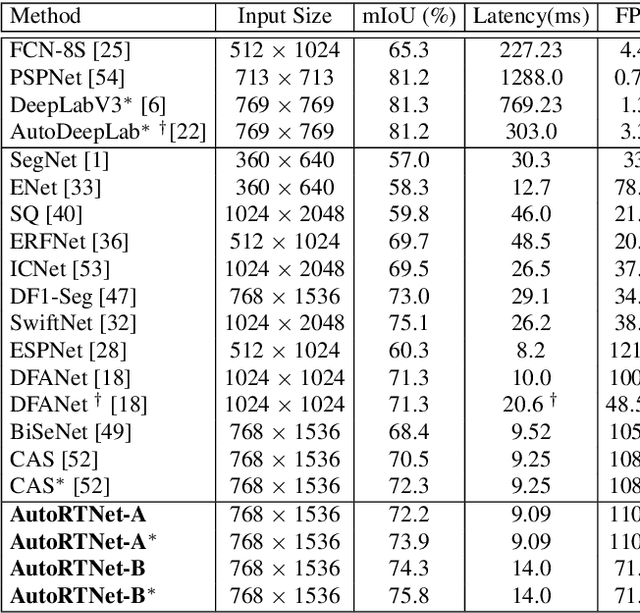

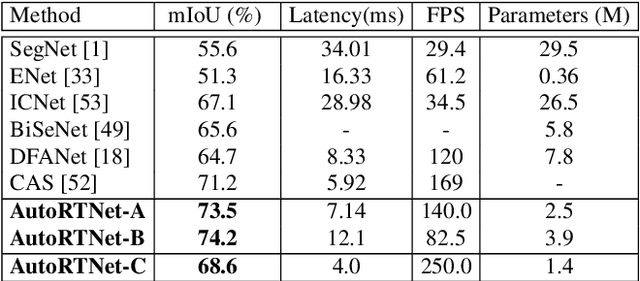
To satisfy the stringent requirements on computational resources in the field of real-time semantic segmentation, most approaches focus on the hand-crafted design of light-weight segmentation networks. Recently, Neural Architecture Search (NAS) has been used to search for the optimal building blocks of networks automatically, but the network depth, downsampling strategy, and feature aggregation way are still set in advance by trial and error. In this paper, we propose a joint search framework, called AutoRTNet, to automate the design of these strategies. Specifically, we propose hyper-cells to jointly decide the network depth and downsampling strategy, and an aggregation cell to achieve automatic multi-scale feature aggregation. Experimental results show that AutoRTNet achieves 73.9% mIoU on the Cityscapes test set and 110.0 FPS on an NVIDIA TitanXP GPU card with 768x1536 input images.
Disturbance-immune Weight Sharing for Neural Architecture Search
Mar 29, 2020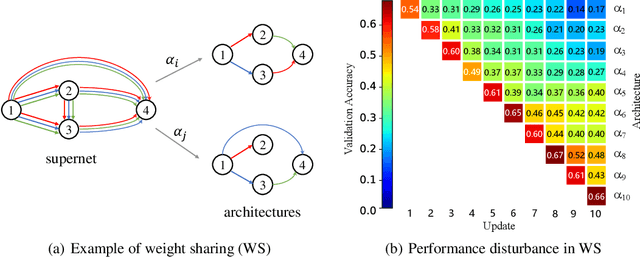
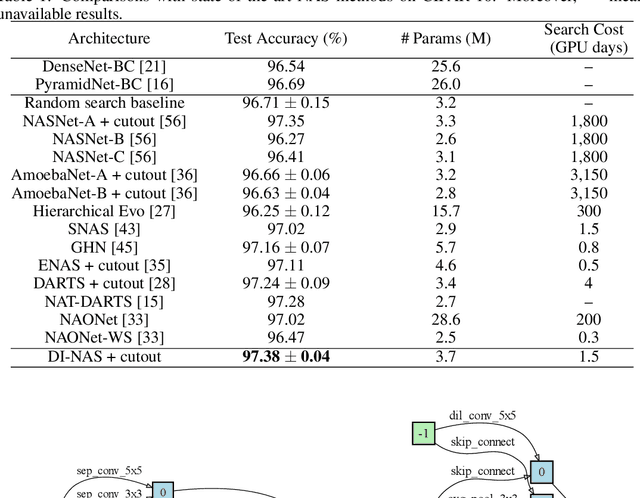
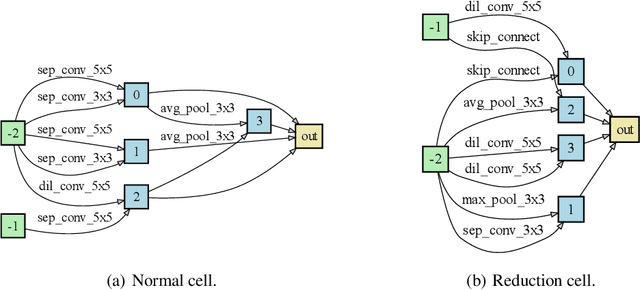
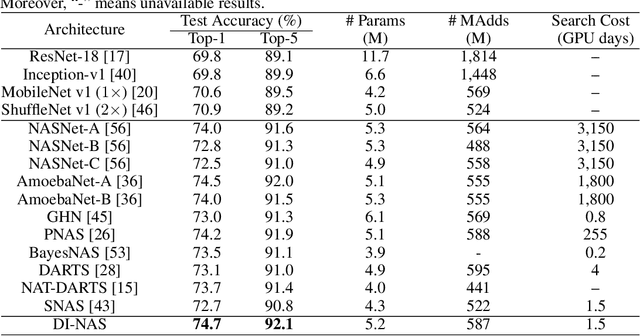
Neural architecture search (NAS) has gained increasing attention in the community of architecture design. One of the key factors behind the success lies in the training efficiency created by the weight sharing (WS) technique. However, WS-based NAS methods often suffer from a performance disturbance (PD) issue. That is, the training of subsequent architectures inevitably disturbs the performance of previously trained architectures due to the partially shared weights. This leads to inaccurate performance estimation for the previous architectures, which makes it hard to learn a good search strategy. To alleviate the performance disturbance issue, we propose a new disturbance-immune update strategy for model updating. Specifically, to preserve the knowledge learned by previous architectures, we constrain the training of subsequent architectures in an orthogonal space via orthogonal gradient descent. Equipped with this strategy, we propose a novel disturbance-immune training scheme for NAS. We theoretically analyze the effectiveness of our strategy in alleviating the PD risk. Extensive experiments on CIFAR-10 and ImageNet verify the superiority of our method.
Few Shot Network Compression via Cross Distillation
Nov 21, 2019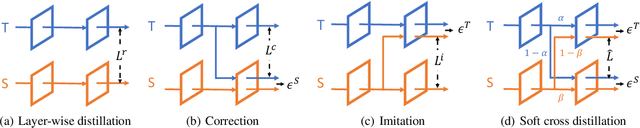
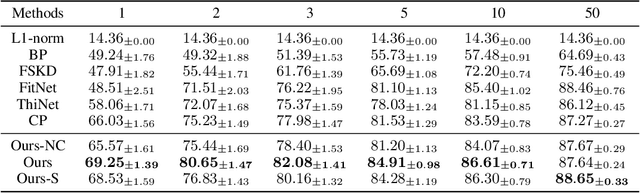
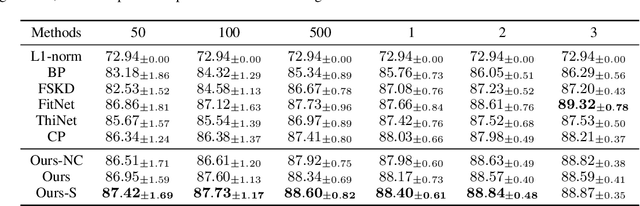
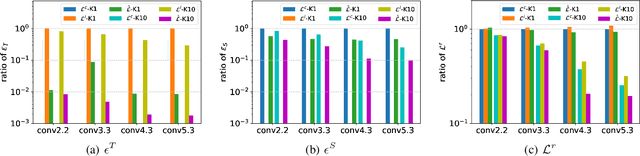
Model compression has been widely adopted to obtain light-weighted deep neural networks. Most prevalent methods, however, require fine-tuning with sufficient training data to ensure accuracy, which could be challenged by privacy and security issues. As a compromise between privacy and performance, in this paper we investigate few shot network compression: given few samples per class, how can we effectively compress the network with negligible performance drop? The core challenge of few shot network compression lies in high estimation errors from the original network during inference, since the compressed network can easily over-fits on the few training instances. The estimation errors could propagate and accumulate layer-wisely and finally deteriorate the network output. To address the problem, we propose cross distillation, a novel layer-wise knowledge distillation approach. By interweaving hidden layers of teacher and student network, layer-wisely accumulated estimation errors can be effectively reduced.The proposed method offers a general framework compatible with prevalent network compression techniques such as pruning. Extensive experiments on benchmark datasets demonstrate that cross distillation can significantly improve the student network's accuracy when only a few training instances are available.
An Efficient Approach to Informative Feature Extraction from Multimodal Data
Nov 22, 2018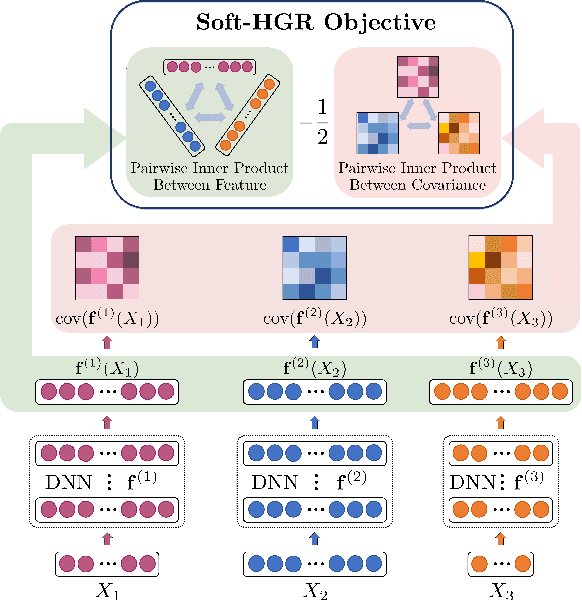
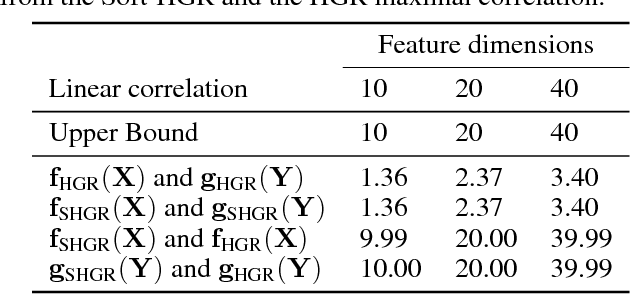
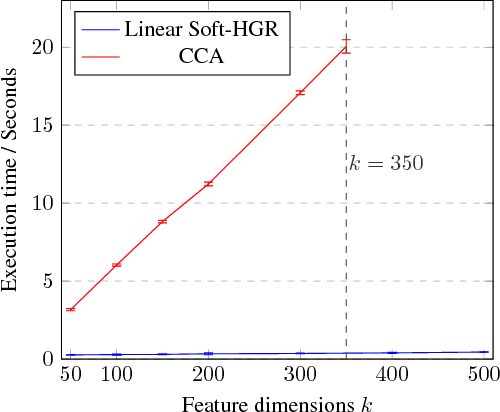
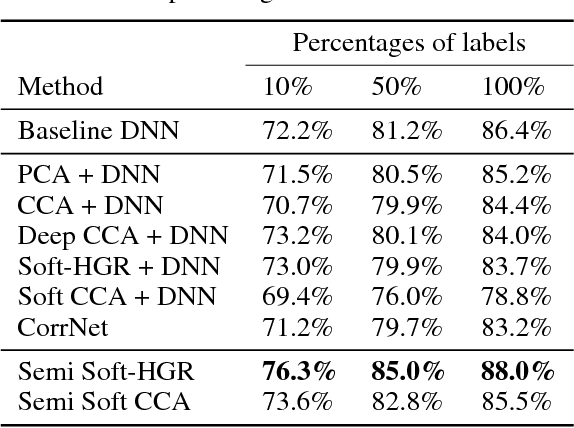
One primary focus in multimodal feature extraction is to find the representations of individual modalities that are maximally correlated. As a well-known measure of dependence, the Hirschfeld-Gebelein-R\'{e}nyi (HGR) maximal correlation becomes an appealing objective because of its operational meaning and desirable properties. However, the strict whitening constraints formalized in the HGR maximal correlation limit its application. To address this problem, this paper proposes Soft-HGR, a novel framework to extract informative features from multiple data modalities. Specifically, our framework prevents the "hard" whitening constraints, while simultaneously preserving the same feature geometry as in the HGR maximal correlation. The objective of Soft-HGR is straightforward, only involving two inner products, which guarantees the efficiency and stability in optimization. We further generalize the framework to handle more than two modalities and missing modalities. When labels are partially available, we enhance the discriminative power of the feature representations by making a semi-supervised adaptation. Empirical evaluation implies that our approach learns more informative feature mappings and is more efficient to optimize.
Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization
Jun 21, 2018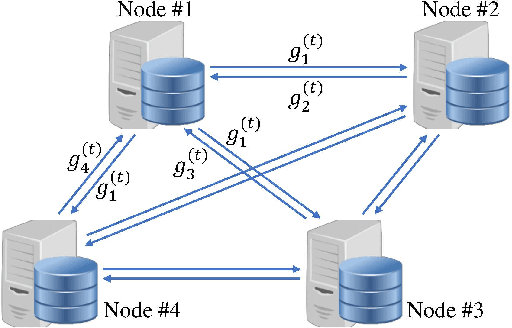
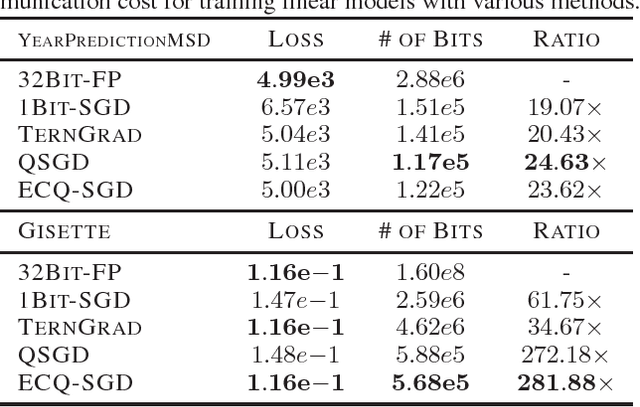
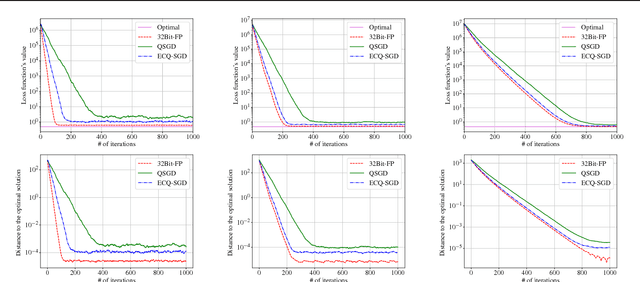
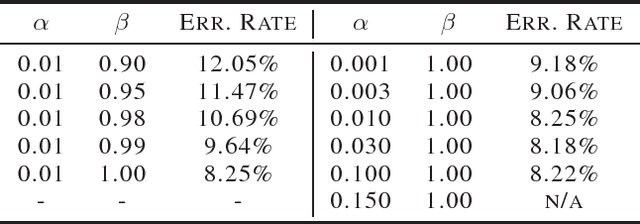
Large-scale distributed optimization is of great importance in various applications. For data-parallel based distributed learning, the inter-node gradient communication often becomes the performance bottleneck. In this paper, we propose the error compensated quantized stochastic gradient descent algorithm to improve the training efficiency. Local gradients are quantized to reduce the communication overhead, and accumulated quantization error is utilized to speed up the convergence. Furthermore, we present theoretical analysis on the convergence behaviour, and demonstrate its advantage over competitors. Extensive experiments indicate that our algorithm can compress gradients by a factor of up to two magnitudes without performance degradation.
Quantized Convolutional Neural Networks for Mobile Devices
May 16, 2016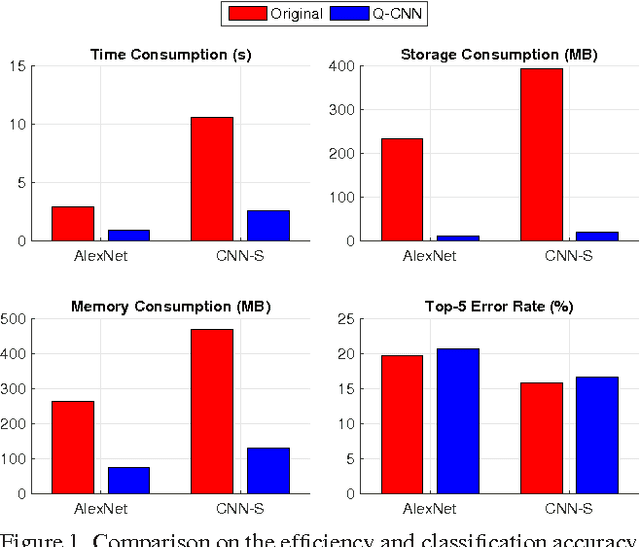

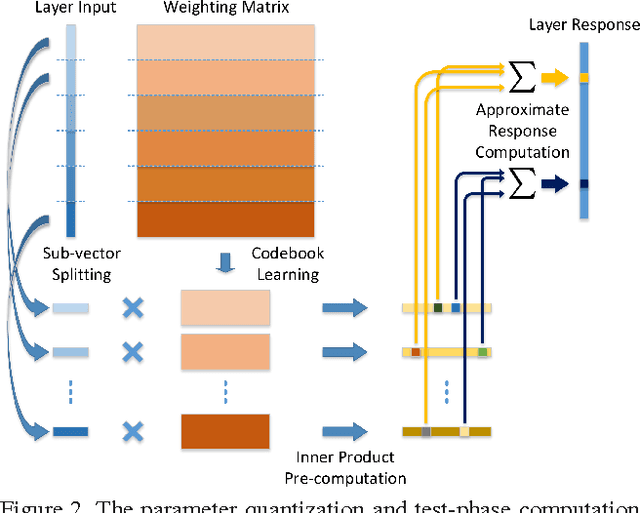
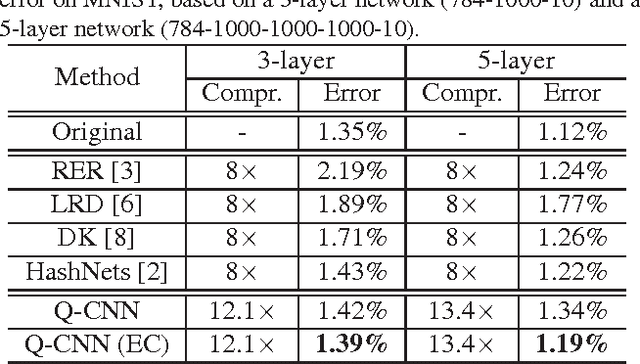
Recently, convolutional neural networks (CNN) have demonstrated impressive performance in various computer vision tasks. However, high performance hardware is typically indispensable for the application of CNN models due to the high computation complexity, which prohibits their further extensions. In this paper, we propose an efficient framework, namely Quantized CNN, to simultaneously speed-up the computation and reduce the storage and memory overhead of CNN models. Both filter kernels in convolutional layers and weighting matrices in fully-connected layers are quantized, aiming at minimizing the estimation error of each layer's response. Extensive experiments on the ILSVRC-12 benchmark demonstrate 4~6x speed-up and 15~20x compression with merely one percentage loss of classification accuracy. With our quantized CNN model, even mobile devices can accurately classify images within one second.