 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Face Analytics Networks through Cross-Dataset Hybrid Training
Nov 16, 2017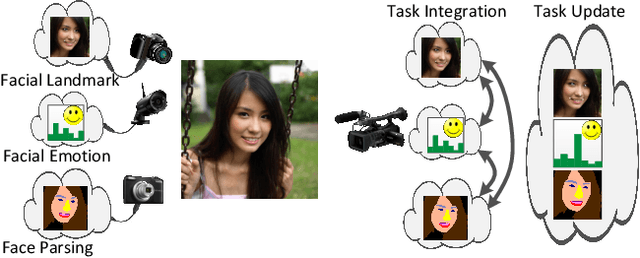
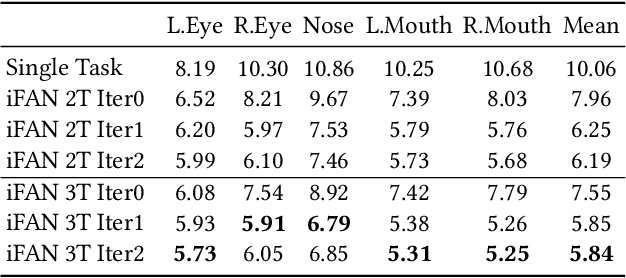
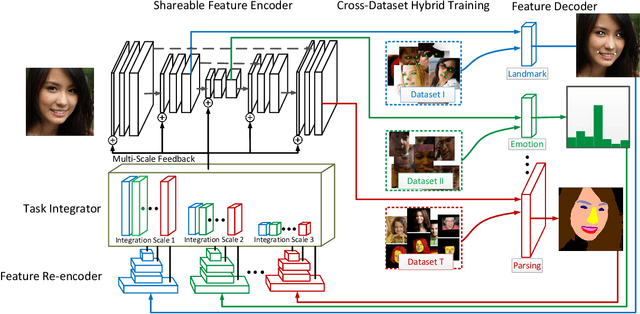
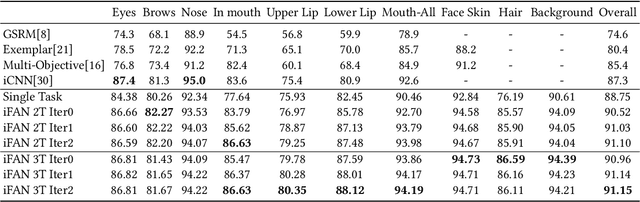
Face analytics benefits many multimedia applications. It consists of a number of tasks, such as facial emotion recognition and face parsing, and most existing approaches generally treat these tasks independently, which limits their deployment in real scenarios. In this paper we propose an integrated Face Analytics Network (iFAN), which is able to perform multiple tasks jointly for face analytics with a novel carefully designed network architecture to fully facilitate the informative interaction among different tasks. The proposed integrated network explicitly models the interactions between tasks so that the correlations between tasks can be fully exploited for performance boost. In addition, to solve the bottleneck of the absence of datasets with comprehensive training data for various tasks, we propose a novel cross-dataset hybrid training strategy. It allows "plug-in and play" of multiple datasets annotated for different tasks without the requirement of a fully labeled common dataset for all the tasks. We experimentally show that the proposed iFAN achieves state-of-the-art performance on multiple face analytics tasks using a single integrated model. Specifically, iFAN achieves an overall F-score of 91.15% on the Helen dataset for face parsing, a normalized mean error of 5.81% on the MTFL dataset for facial landmark localization and an accuracy of 45.73% on the BNU dataset for emotion recognition with a single model.
Predicting Scene Parsing and Motion Dynamics in the Future
Nov 09, 2017
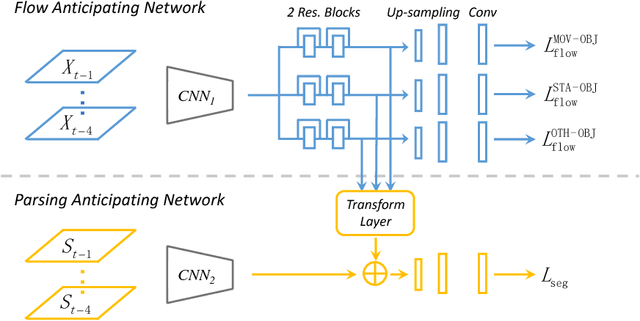
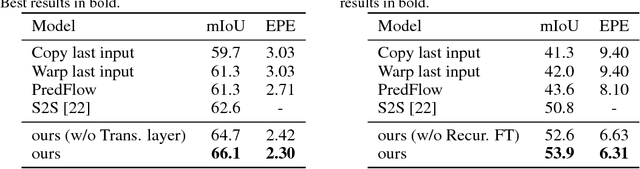

The ability of predicting the future is important for intelligent systems, e.g. autonomous vehicles and robots to plan early and make decisions accordingly. Future scene parsing and optical flow estimation are two key tasks that help agents better understand their environments as the former provides dense semantic information, i.e. what objects will be present and where they will appear, while the latter provides dense motion information, i.e. how the objects will move. In this paper, we propose a novel model to simultaneously predict scene parsing and optical flow in unobserved future video frames. To our best knowledge, this is the first attempt in jointly predicting scene parsing and motion dynamics. In particular, scene parsing enables structured motion prediction by decomposing optical flow into different groups while optical flow estimation brings reliable pixel-wise correspondence to scene parsing. By exploiting this mutually beneficial relationship, our model shows significantly better parsing and motion prediction results when compared to well-established baselines and individual prediction models on the large-scale Cityscapes dataset. In addition, we also demonstrate that our model can be used to predict the steering angle of the vehicles, which further verifies the ability of our model to learn latent representations of scene dynamics.
Ensemble Robustness and Generalization of Stochastic Deep Learning Algorithms
Nov 05, 2017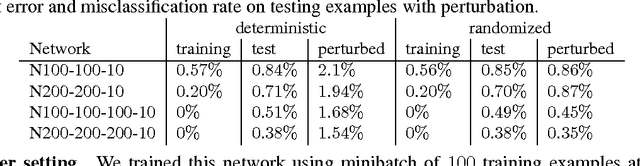
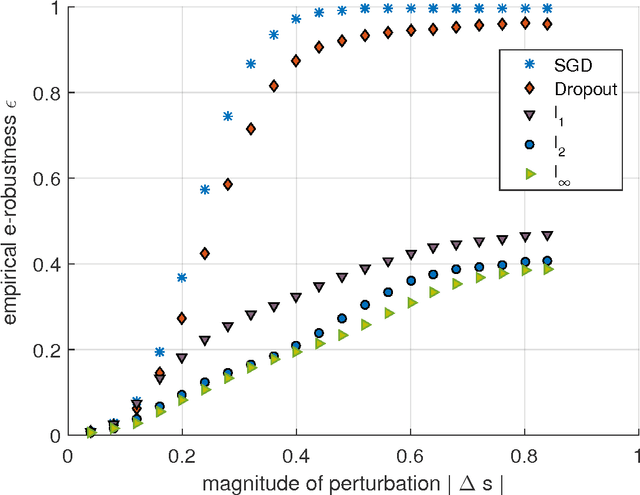
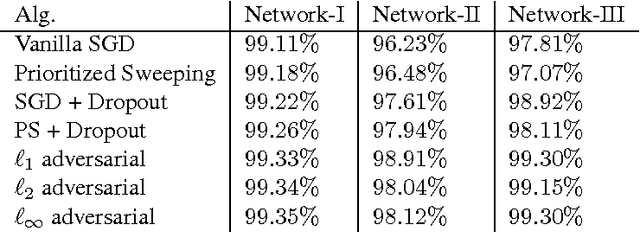

The question why deep learning algorithms generalize so well has attracted increasing research interest. However, most of the well-established approaches, such as hypothesis capacity, stability or sparseness, have not provided complete explanations (Zhang et al., 2016; Kawaguchi et al., 2017). In this work, we focus on the robustness approach (Xu & Mannor, 2012), i.e., if the error of a hypothesis will not change much due to perturbations of its training examples, then it will also generalize well. As most deep learning algorithms are stochastic (e.g., Stochastic Gradient Descent, Dropout, and Bayes-by-backprop), we revisit the robustness arguments of Xu & Mannor, and introduce a new approach, ensemble robustness, that concerns the robustness of a population of hypotheses. Through the lens of ensemble robustness, we reveal that a stochastic learning algorithm can generalize well as long as its sensitiveness to adversarial perturbations is bounded in average over training examples. Moreover, an algorithm may be sensitive to some adversarial examples (Goodfellow et al., 2015) but still generalize well. To support our claims, we provide extensive simulations for different deep learning algorithms and different network architectures exhibiting a strong correlation between ensemble robustness and the ability to generalize.
Deep Sparse Subspace Clustering
Sep 25, 2017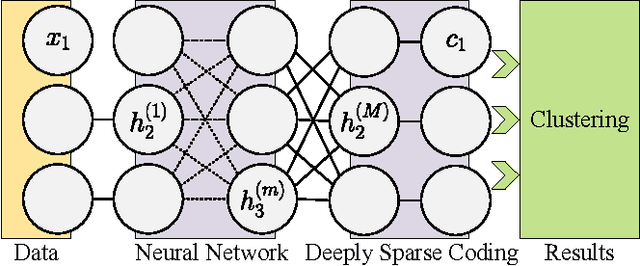
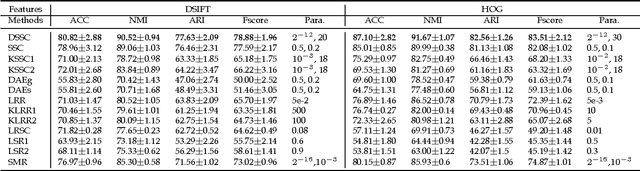
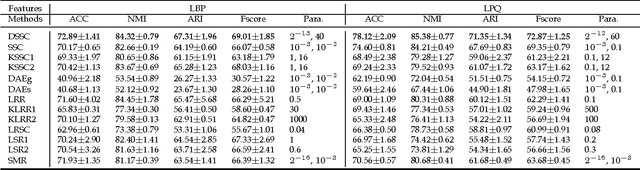
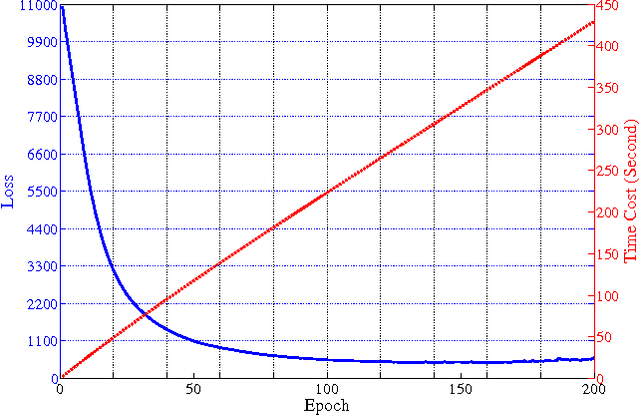
In this paper, we present a deep extension of Sparse Subspace Clustering, termed Deep Sparse Subspace Clustering (DSSC). Regularized by the unit sphere distribution assumption for the learned deep features, DSSC can infer a new data affinity matrix by simultaneously satisfying the sparsity principle of SSC and the nonlinearity given by neural networks. One of the appealing advantages brought by DSSC is: when original real-world data do not meet the class-specific linear subspace distribution assumption, DSSC can employ neural networks to make the assumption valid with its hierarchical nonlinear transformations. To the best of our knowledge, this is among the first deep learning based subspace clustering methods. Extensive experiments are conducted on four real-world datasets to show the proposed DSSC is significantly superior to 12 existing methods for subspace clustering.
Discriminative Similarity for Clustering and Semi-Supervised Learning
Sep 05, 2017Similarity-based clustering and semi-supervised learning methods separate the data into clusters or classes according to the pairwise similarity between the data, and the pairwise similarity is crucial for their performance. In this paper, we propose a novel discriminative similarity learning framework which learns discriminative similarity for either data clustering or semi-supervised learning. The proposed framework learns classifier from each hypothetical labeling, and searches for the optimal labeling by minimizing the generalization error of the learned classifiers associated with the hypothetical labeling. Kernel classifier is employed in our framework. By generalization analysis via Rademacher complexity, the generalization error bound for the kernel classifier learned from hypothetical labeling is expressed as the sum of pairwise similarity between the data from different classes, parameterized by the weights of the kernel classifier. Such pairwise similarity serves as the discriminative similarity for the purpose of clustering and semi-supervised learning, and discriminative similarity with similar form can also be induced by the integrated squared error bound for kernel density classification. Based on the discriminative similarity induced by the kernel classifier, we propose new clustering and semi-supervised learning methods.
On the Suboptimality of Proximal Gradient Descent for $\ell^{0}$ Sparse Approximation
Sep 05, 2017We study the proximal gradient descent (PGD) method for $\ell^{0}$ sparse approximation problem as well as its accelerated optimization with randomized algorithms in this paper. We first offer theoretical analysis of PGD showing the bounded gap between the sub-optimal solution by PGD and the globally optimal solution for the $\ell^{0}$ sparse approximation problem under conditions weaker than Restricted Isometry Property widely used in compressive sensing literature. Moreover, we propose randomized algorithms to accelerate the optimization by PGD using randomized low rank matrix approximation (PGD-RMA) and randomized dimension reduction (PGD-RDR). Our randomized algorithms substantially reduces the computation cost of the original PGD for the $\ell^{0}$ sparse approximation problem, and the resultant sub-optimal solution still enjoys provable suboptimality, namely, the sub-optimal solution to the reduced problem still has bounded gap to the globally optimal solution to the original problem.
Self-explanatory Deep Salient Object Detection
Aug 18, 2017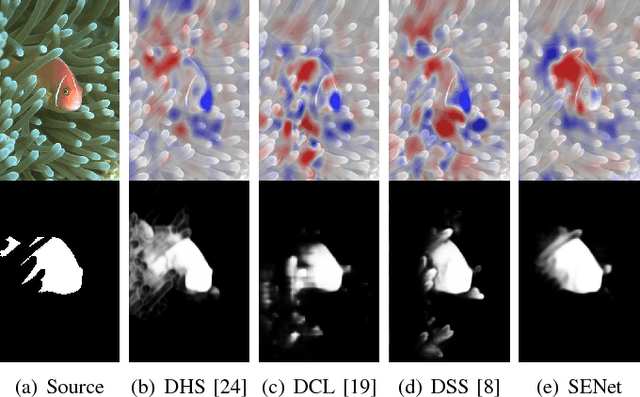

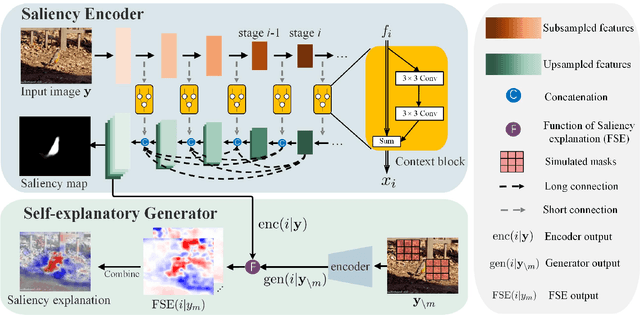

Salient object detection has seen remarkable progress driven by deep learning techniques. However, most of deep learning based salient object detection methods are black-box in nature and lacking in interpretability. This paper proposes the first self-explanatory saliency detection network that explicitly exploits low- and high-level features for salient object detection. We demonstrate that such supportive clues not only significantly enhances performance of salient object detection but also gives better justified detection results. More specifically, we develop a multi-stage saliency encoder to extract multi-scale features which contain both low- and high-level saliency context. Dense short- and long-range connections are introduced to reuse these features iteratively. Benefiting from the direct access to low- and high-level features, the proposed saliency encoder can not only model the object context but also preserve the boundary. Furthermore, a self-explanatory generator is proposed to interpret how the proposed saliency encoder or other deep saliency models making decisions. The generator simulates the absence of interesting features by preventing these features from contributing to the saliency classifier and estimates the corresponding saliency prediction without these features. A comparison function, saliency explanation, is defined to measure the prediction changes between deep saliency models and corresponding generator. Through visualizing the differences, we can interpret the capability of different deep neural networks based saliency detection models and demonstrate that our proposed model indeed uses more reasonable structure for salient object detection. Extensive experiments on five popular benchmark datasets and the visualized saliency explanation demonstrate that the proposed method provides new state-of-the-art.
Training Group Orthogonal Neural Networks with Privileged Information
Aug 18, 2017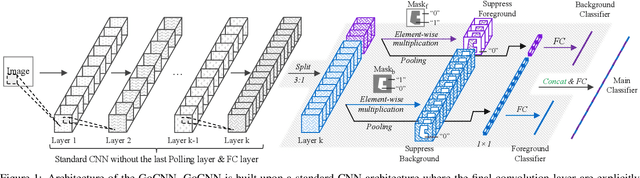


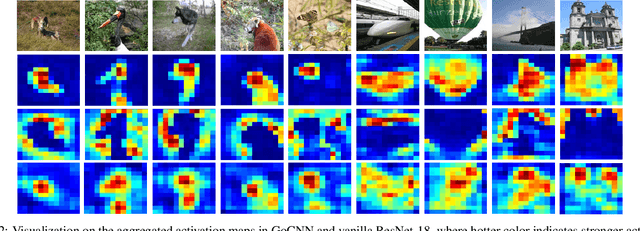
Learning rich and diverse representations is critical for the performance of deep convolutional neural networks (CNNs). In this paper, we consider how to use privileged information to promote inherent diversity of a single CNN model such that the model can learn better representations and offer stronger generalization ability. To this end, we propose a novel group orthogonal convolutional neural network (GoCNN) that learns untangled representations within each layer by exploiting provided privileged information and enhances representation diversity effectively. We take image classification as an example where image segmentation annotations are used as privileged information during the training process. Experiments on two benchmark datasets -- ImageNet and PASCAL VOC -- clearly demonstrate the strong generalization ability of our proposed GoCNN model. On the ImageNet dataset, GoCNN improves the performance of state-of-the-art ResNet-152 model by absolute value of 1.2% while only uses privileged information of 10% of the training images, confirming effectiveness of GoCNN on utilizing available privileged knowledge to train better CNNs.
Learning with Rethinking: Recurrently Improving Convolutional Neural Networks through Feedback
Aug 15, 2017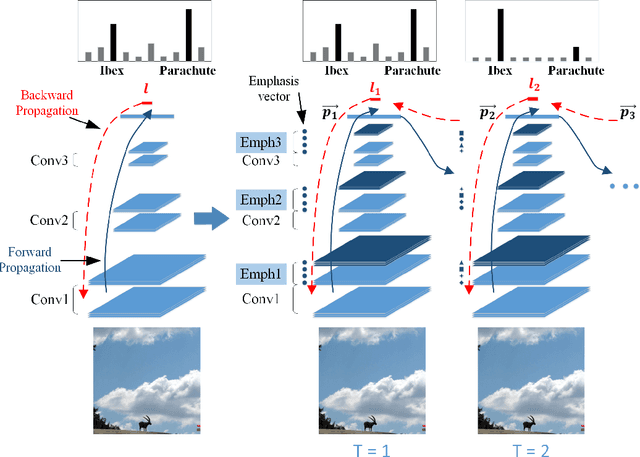
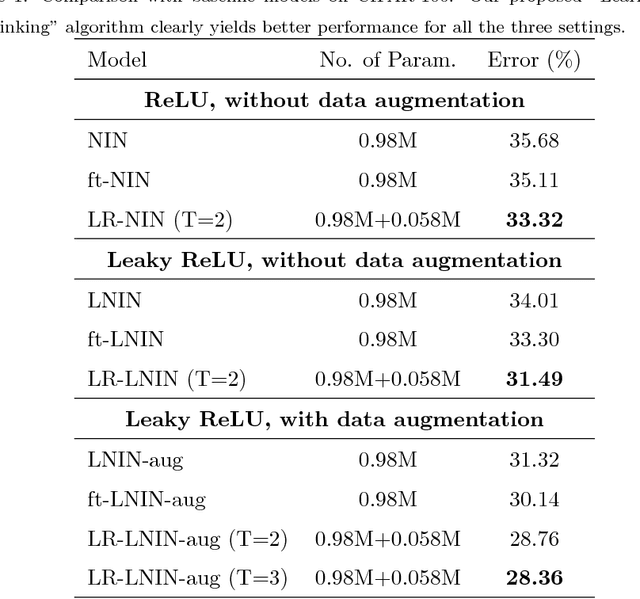
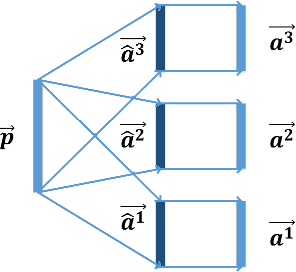
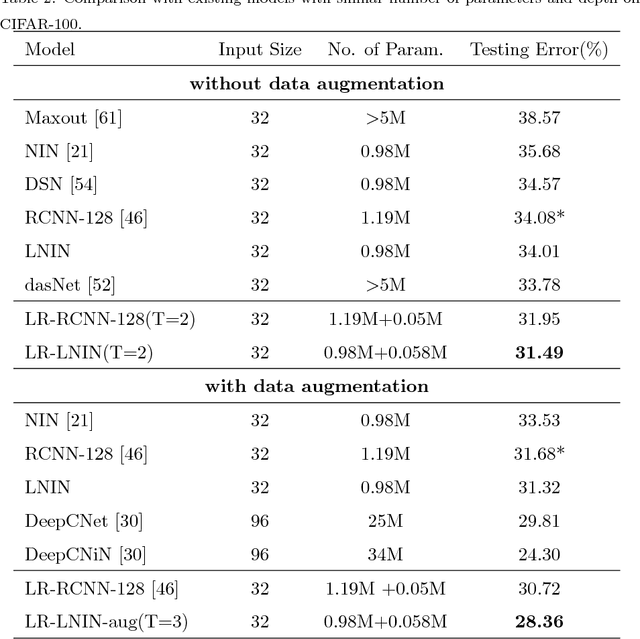
Recent years have witnessed the great success of convolutional neural network (CNN) based models in the field of computer vision. CNN is able to learn hierarchically abstracted features from images in an end-to-end training manner. However, most of the existing CNN models only learn features through a feedforward structure and no feedback information from top to bottom layers is exploited to enable the networks to refine themselves. In this paper, we propose a "Learning with Rethinking" algorithm. By adding a feedback layer and producing the emphasis vector, the model is able to recurrently boost the performance based on previous prediction. Particularly, it can be employed to boost any pre-trained models. This algorithm is tested on four object classification benchmark datasets: CIFAR-100, CIFAR-10, MNIST-background-image and ILSVRC-2012 dataset. These results have demonstrated the advantage of training CNN models with the proposed feedback mechanism.
FoveaNet: Perspective-aware Urban Scene Parsing
Aug 08, 2017
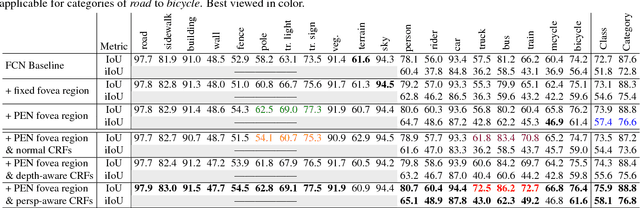
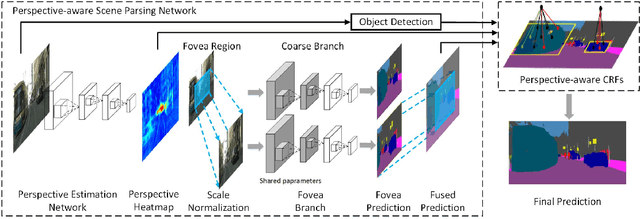
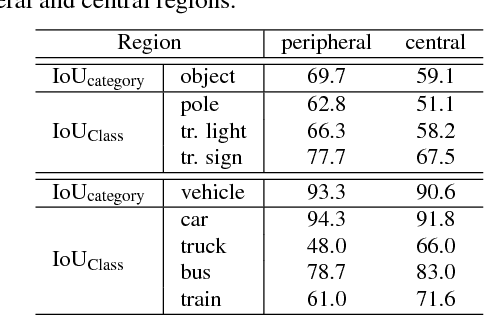
Parsing urban scene images benefits many applications, especially self-driving. Most of the current solutions employ generic image parsing models that treat all scales and locations in the images equally and do not consider the geometry property of car-captured urban scene images. Thus, they suffer from heterogeneous object scales caused by perspective projection of cameras on actual scenes and inevitably encounter parsing failures on distant objects as well as other boundary and recognition errors. In this work, we propose a new FoveaNet model to fully exploit the perspective geometry of scene images and address the common failures of generic parsing models. FoveaNet estimates the perspective geometry of a scene image through a convolutional network which integrates supportive evidence from contextual objects within the image. Based on the perspective geometry information, FoveaNet "undoes" the camera perspective projection analyzing regions in the space of the actual scene, and thus provides much more reliable parsing results. Furthermore, to effectively address the recognition errors, FoveaNet introduces a new dense CRFs model that takes the perspective geometry as a prior potential. We evaluate FoveaNet on two urban scene parsing datasets, Cityspaces and CamVid, which demonstrates that FoveaNet can outperform all the well-established baselines and provide new state-of-the-art performance.