 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Apr 30, 2019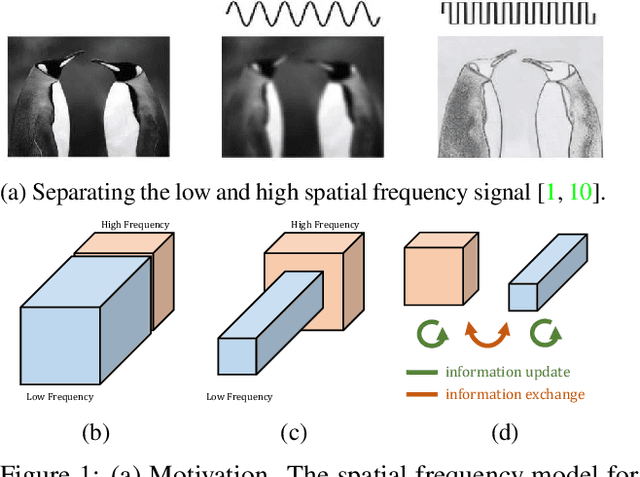

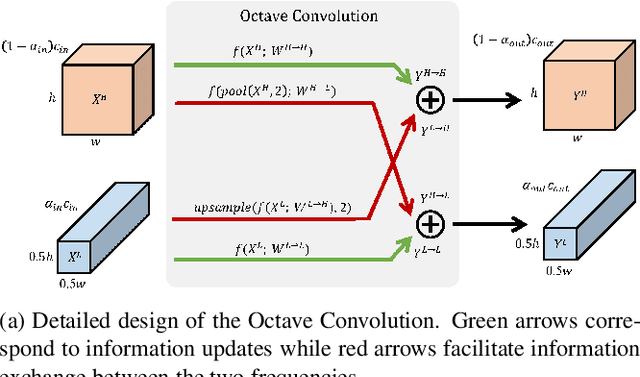
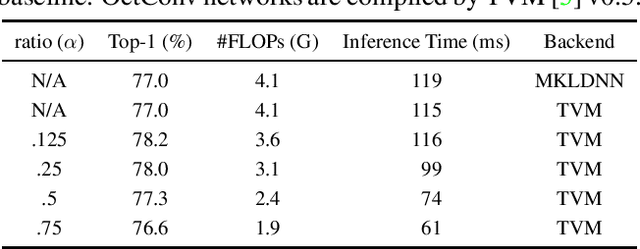
In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
A Simple Pooling-Based Design for Real-Time Salient Object Detection
Apr 21, 2019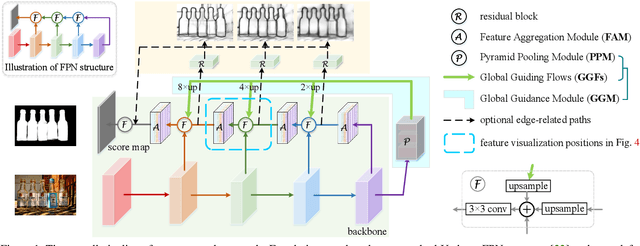
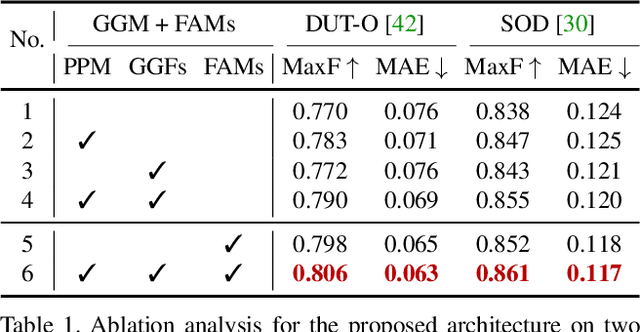

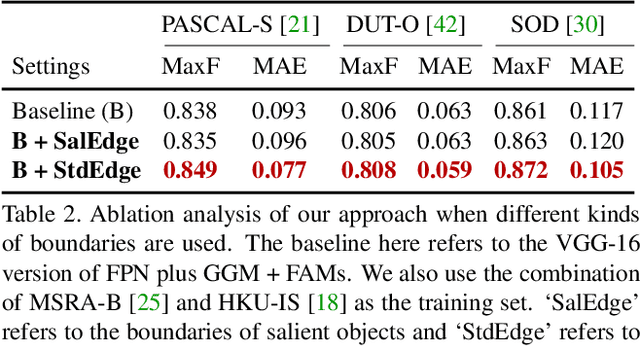
We solve the problem of salient object detection by investigating how to expand the role of pooling in convolutional neural networks. Based on the U-shape architecture, we first build a global guidance module (GGM) upon the bottom-up pathway, aiming at providing layers at different feature levels the location information of potential salient objects. We further design a feature aggregation module (FAM) to make the coarse-level semantic information well fused with the fine-level features from the top-down pathway. By adding FAMs after the fusion operations in the top-down pathway, coarse-level features from the GGM can be seamlessly merged with features at various scales. These two pooling-based modules allow the high-level semantic features to be progressively refined, yielding detail enriched saliency maps. Experiment results show that our proposed approach can more accurately locate the salient objects with sharpened details and hence substantially improve the performance compared to the previous state-of-the-arts. Our approach is fast as well and can run at a speed of more than 30 FPS when processing a $300 \times 400$ image. Code can be found at http://mmcheng.net/poolnet/.
Hierarchical Meta Learning
Apr 19, 2019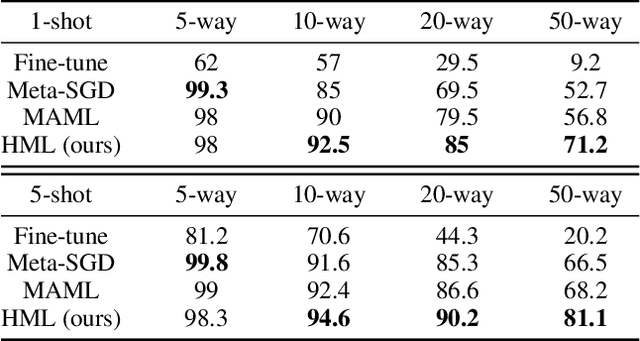

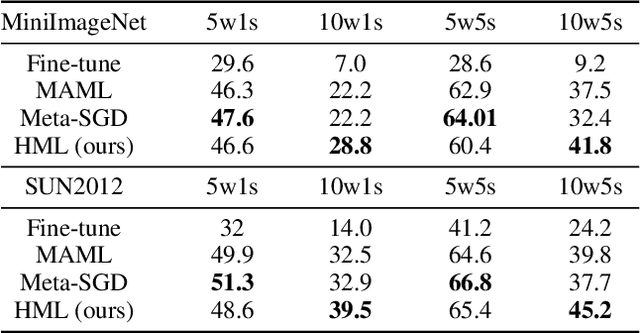
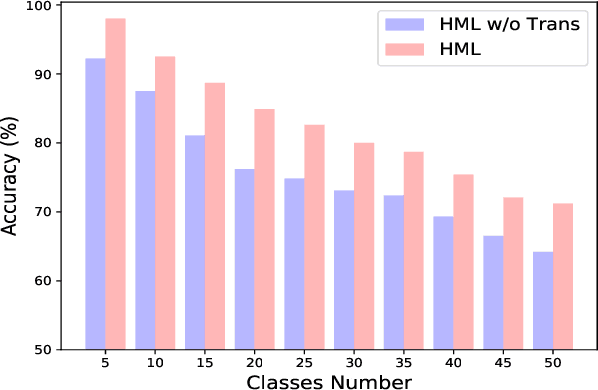
Meta learning is a promising solution to few-shot learning problems. However, existing meta learning methods are restricted to the scenarios where training and application tasks share the same out-put structure. To obtain a meta model applicable to the tasks with new structures, it is required to collect new training data and repeat the time-consuming meta training procedure. This makes them inefficient or even inapplicable in learning to solve heterogeneous few-shot learning tasks. We thus develop a novel and principled HierarchicalMeta Learning (HML) method. Different from existing methods that only focus on optimizing the adaptability of a meta model to similar tasks, HML also explicitly optimizes its generalizability across heterogeneous tasks. To this end, HML first factorizes a set of similar training tasks into heterogeneous ones and trains the meta model over them at two levels to maximize adaptation and generalization performance respectively. The resultant model can then directly generalize to new tasks. Extensive experiments on few-shot classification and regression problems clearly demonstrate the superiority of HML over fine-tuning and state-of-the-art meta learning approaches in terms of generalization across heterogeneous tasks.
Cycle-SUM: Cycle-consistent Adversarial LSTM Networks for Unsupervised Video Summarization
Apr 17, 2019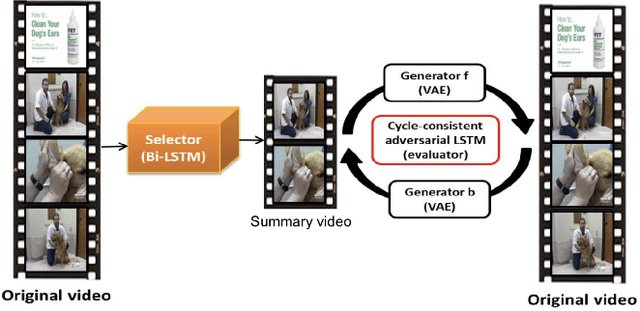

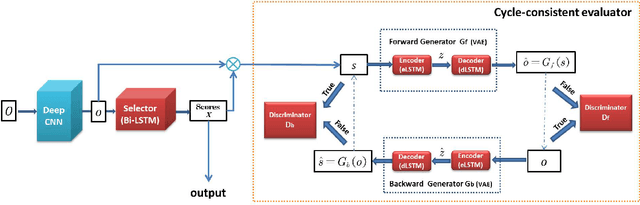
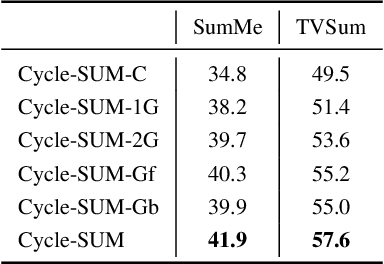
In this paper, we present a novel unsupervised video summarization model that requires no manual annotation. The proposed model termed Cycle-SUM adopts a new cycle-consistent adversarial LSTM architecture that can effectively maximize the information preserving and compactness of the summary video. It consists of a frame selector and a cycle-consistent learning based evaluator. The selector is a bi-direction LSTM network that learns video representations that embed the long-range relationships among video frames. The evaluator defines a learnable information preserving metric between original video and summary video and "supervises" the selector to identify the most informative frames to form the summary video. In particular, the evaluator is composed of two generative adversarial networks (GANs), in which the forward GAN is learned to reconstruct original video from summary video while the backward GAN learns to invert the processing. The consistency between the output of such cycle learning is adopted as the information preserving metric for video summarization. We demonstrate the close relation between mutual information maximization and such cycle learning procedure. Experiments on two video summarization benchmark datasets validate the state-of-the-art performance and superiority of the Cycle-SUM model over previous baselines.
Foreground-aware Pyramid Reconstruction for Alignment-free Occluded Person Re-identification
Apr 11, 2019
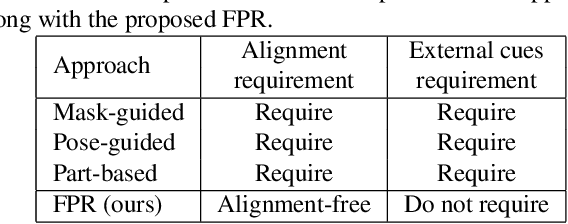
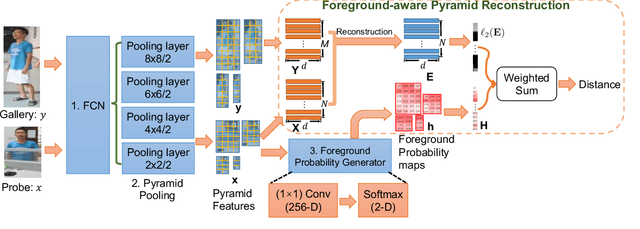

Re-identifying a person across multiple disjoint camera views is important for intelligent video surveillance, smart retailing and many other applications. However, existing person re-identification (ReID) methods are challenged by the ubiquitous occlusion over persons and suffer from performance degradation. This paper proposes a novel occlusion-robust and alignment-free model for occluded person ReID and extends its application to realistic and crowded scenarios. The proposed model first leverages the full convolution network (FCN) and pyramid pooling to extract spatial pyramid features. Then an alignment-free matching approach, namely Foreground-aware Pyramid Reconstruction (FPR), is developed to accurately compute matching scores between occluded persons, despite their different scales and sizes. FPR uses the error from robust reconstruction over spatial pyramid features to measure similarities between two persons. More importantly, we design an occlusion-sensitive foreground probability generator that focuses more on clean human body parts to refine the similarity computation with less contamination from occlusion. The FPR is easily embedded into any end-to-end person ReID models. The effectiveness of the proposed method is clearly demonstrated by the experimental results (Rank-1 accuracy) on three occluded person datasets: Partial REID (78.30\%), Partial iLIDS (68.08\%) and Occluded REID (81.00\%); and three benchmark person datasets: Market1501 (95.42\%), DukeMTMC (88.64\%) and CUHK03 (76.08\%)
Partial Order Pruning: for Best Speed/Accuracy Trade-off in Neural Architecture Search
Apr 05, 2019
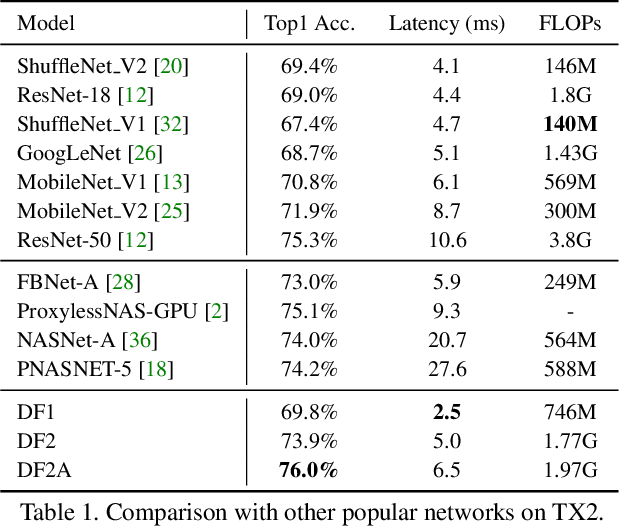

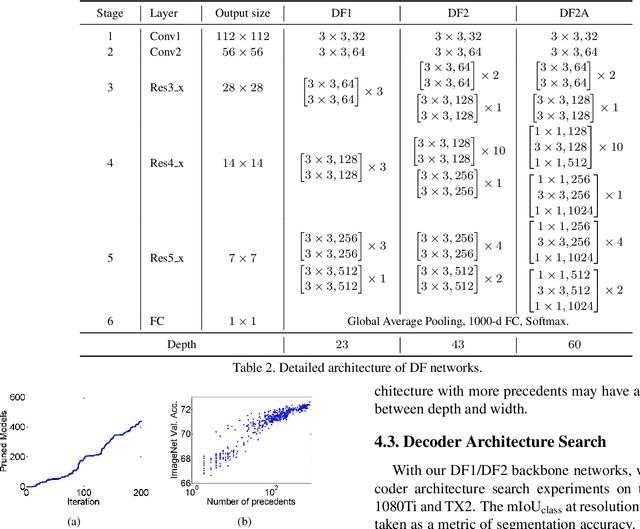
Achieving good speed and accuracy trade-off on a target platform is very important in deploying deep neural networks in real world scenarios. However, most existing automatic architecture search approaches only concentrate on high performance. In this work, we propose an algorithm that can offer better speed/accuracy trade-off of searched networks, which is termed "Partial Order Pruning". It prunes the architecture search space with a partial order assumption to automatically search for the architectures with the best speed and accuracy trade-off. Our algorithm explicitly takes profile information about the inference speed on the target platform into consideration. With the proposed algorithm, we present several Dongfeng (DF) networks that provide high accuracy and fast inference speed on various application GPU platforms. By further searching decoder architectures, our DF-Seg real-time segmentation networks yield state-of-the-art speed/accuracy trade-off on both the target embedded device and the high-end GPU.
Multi-Prototype Networks for Unconstrained Set-based Face Recognition
Mar 23, 2019
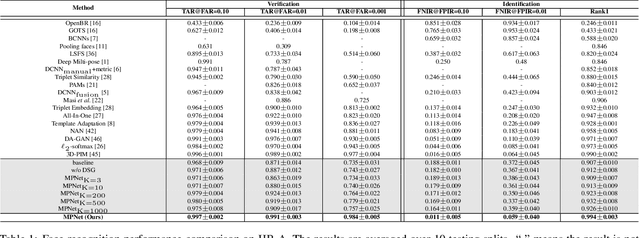
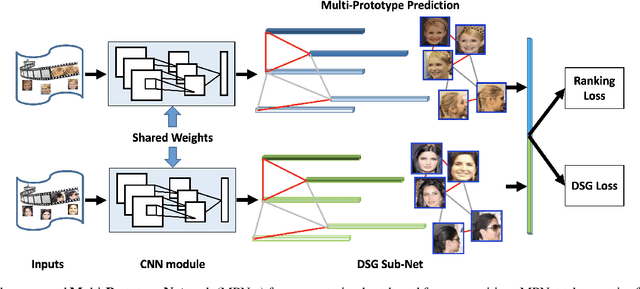
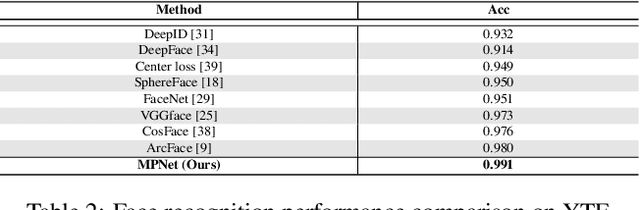
In this paper, we study the challenging unconstrained set-based face recognition problem where each subject face is instantiated by a set of media (images and videos) instead of a single image. Naively aggregating information from all the media within a set would suffer from the large intra-set variance caused by heterogeneous factors (e.g., varying media modalities, poses and illuminations) and fail to learn discriminative face representations. A novel Multi-Prototype Network (MPNet) model is thus proposed to learn multiple prototype face representations adaptively from the media sets. Each learned prototype is representative for the subject face under certain condition in terms of pose, illumination and media modality. Instead of handcrafting the set partition for prototype learning, MPNet introduces a Dense SubGraph (DSG) learning sub-net that implicitly untangles inconsistent media and learns a number of representative prototypes. Qualitative and quantitative experiments clearly demonstrate superiority of the proposed model over state-of-the-arts.
Few-shot Adaptive Faster R-CNN
Mar 22, 2019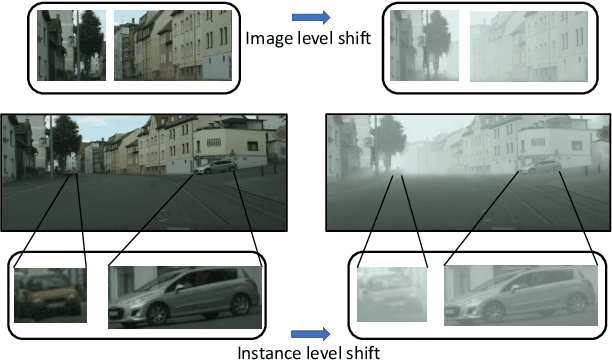

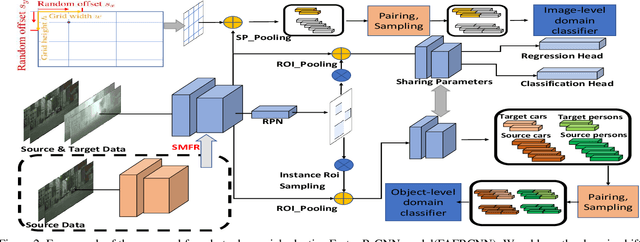

To mitigate the detection performance drop caused by domain shift, we aim to develop a novel few-shot adaptation approach that requires only a few target domain images with limited bounding box annotations. To this end, we first observe several significant challenges. First, the target domain data is highly insufficient, making most existing domain adaptation methods ineffective. Second, object detection involves simultaneous localization and classification, further complicating the model adaptation process. Third, the model suffers from over-adaptation (similar to overfitting when training with a few data example) and instability risk that may lead to degraded detection performance in the target domain. To address these challenges, we first introduce a pairing mechanism over source and target features to alleviate the issue of insufficient target domain samples. We then propose a bi-level module to adapt the source trained detector to the target domain: 1) the split pooling based image level adaptation module uniformly extracts and aligns paired local patch features over locations, with different scale and aspect ratio; 2) the instance level adaptation module semantically aligns paired object features while avoids inter-class confusion. Meanwhile, a source model feature regularization (SMFR) is applied to stabilize the adaptation process of the two modules. Combining these contributions gives a novel few-shot adaptive Faster-RCNN framework, termed FAFRCNN, which effectively adapts to target domain with a few labeled samples. Experiments with multiple datasets show that our model achieves new state-of-the-art performance under both the interested few-shot domain adaptation(FDA) and unsupervised domain adaptation(UDA) setting.
Joint 3D Face Reconstruction and Dense Face Alignment from A Single Image with 2D-Assisted Self-Supervised Learning
Mar 22, 2019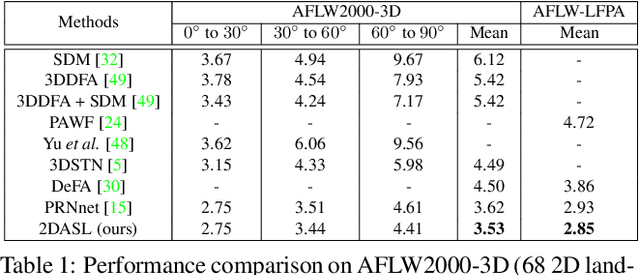
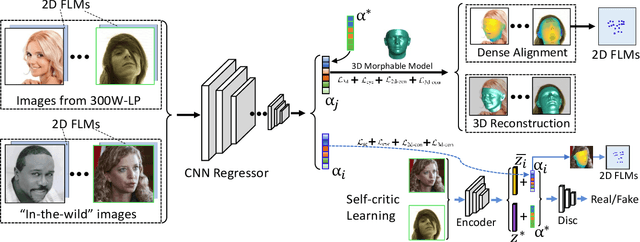
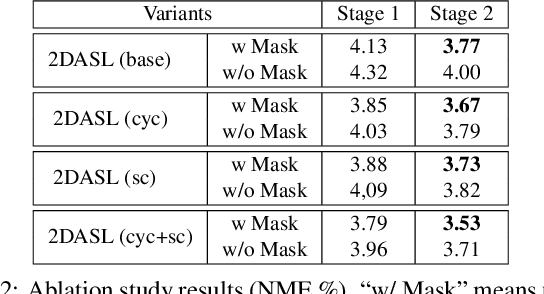
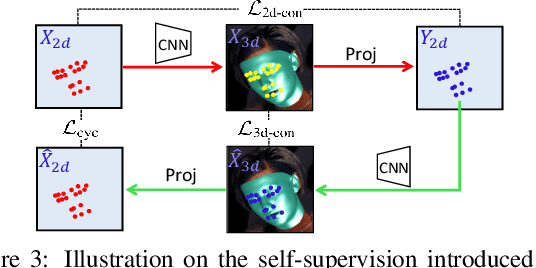
3D face reconstruction from a single 2D image is a challenging problem with broad applications. Recent methods typically aim to learn a CNN-based 3D face model that regresses coefficients of 3D Morphable Model (3DMM) from 2D images to render 3D face reconstruction or dense face alignment. However, the shortage of training data with 3D annotations considerably limits performance of those methods. To alleviate this issue, we propose a novel 2D-assisted self-supervised learning (2DASL) method that can effectively use "in-the-wild" 2D face images with noisy landmark information to substantially improve 3D face model learning. Specifically, taking the sparse 2D facial landmarks as additional information, 2DSAL introduces four novel self-supervision schemes that view the 2D landmark and 3D landmark prediction as a self-mapping process, including the 2D and 3D landmark self-prediction consistency, cycle-consistency over the 2D landmark prediction and self-critic over the predicted 3DMM coefficients based on landmark predictions. Using these four self-supervision schemes, the 2DASL method significantly relieves demands on the the conventional paired 2D-to-3D annotations and gives much higher-quality 3D face models without requiring any additional 3D annotations. Experiments on multiple challenging datasets show that our method outperforms state-of-the-arts for both 3D face reconstruction and dense face alignment by a large margin.
Dynamic Feature Fusion for Semantic Edge Detection
Feb 25, 2019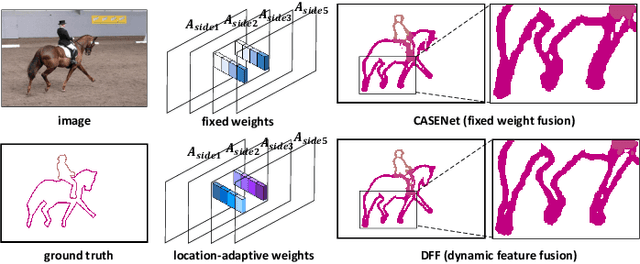
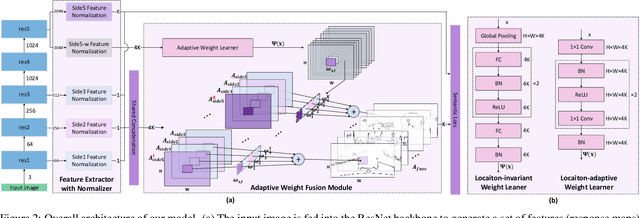
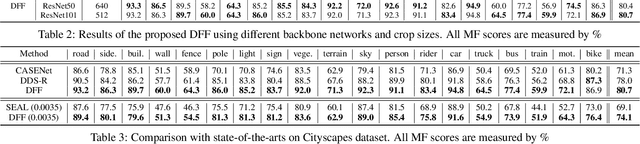
Features from multiple scales can greatly benefit the semantic edge detection task if they are well fused. However, the prevalent semantic edge detection methods apply a fixed weight fusion strategy where images with different semantics are forced to share the same weights, resulting in universal fusion weights for all images and locations regardless of their different semantics or local context. In this work, we propose a novel dynamic feature fusion strategy that assigns different fusion weights for different input images and locations adaptively. This is achieved by a proposed weight learner to infer proper fusion weights over multi-level features for each location of the feature map, conditioned on the specific input. In this way, the heterogeneity in contributions made by different locations of feature maps and input images can be better considered and thus help produce more accurate and sharper edge predictions. We show that our model with the novel dynamic feature fusion is superior to fixed weight fusion and also the na\"ive location-invariant weight fusion methods, via comprehensive experiments on benchmarks Cityscapes and SBD. In particular, our method outperforms all existing well established methods and achieves new state-of-the-art.