 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining
Jul 06, 2024



Language-queried audio source separation (LASS) aims to separate an audio source guided by a text query, with the signal-to-distortion ratio (SDR)-based metrics being commonly used to objectively measure the quality of the separated audio. However, the SDR-based metrics require a reference signal, which is often difficult to obtain in real-world scenarios. In addition, with the SDR-based metrics, the content information of the text query is not considered effectively in LASS. This paper introduces a reference-free evaluation metric using a contrastive language-audio pretraining (CLAP) module, termed CLAPScore, which measures the semantic similarity between the separated audio and the text query. Unlike SDR, the proposed CLAPScore metric evaluates the quality of the separated audio based on the content information of the text query, without needing a reference signal. Experimental results show that the CLAPScore metric provides an effective evaluation of the semantic relevance of the separated audio to the text query, as compared to the SDR metric, offering an alternative for the performance evaluation of LASS systems.
Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions
Oct 23, 2023



Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking.
Dual Transformer Decoder based Features Fusion Network for Automated Audio Captioning
May 30, 2023Automated audio captioning (AAC) which generates textual descriptions of audio content. Existing AAC models achieve good results but only use the high-dimensional representation of the encoder. There is always insufficient information learning of high-dimensional methods owing to high-dimensional representations having a large amount of information. In this paper, a new encoder-decoder model called the Low- and High-Dimensional Feature Fusion (LHDFF) is proposed. LHDFF uses a new PANNs encoder called Residual PANNs (RPANNs) to fuse low- and high-dimensional features. Low-dimensional features contain limited information about specific audio scenes. The fusion of low- and high-dimensional features can improve model performance by repeatedly emphasizing specific audio scene information. To fully exploit the fused features, LHDFF uses a dual transformer decoder structure to generate captions in parallel. Experimental results show that LHDFF outperforms existing audio captioning models.
Towards Generating Diverse Audio Captions via Adversarial Training
Dec 05, 2022



Automated audio captioning is a cross-modal translation task for describing the content of audio clips with natural language sentences. This task has attracted increasing attention and substantial progress has been made in recent years. Captions generated by existing models are generally faithful to the content of audio clips, however, these machine-generated captions are often deterministic (e.g., generating a fixed caption for a given audio clip), simple (e.g., using common words and simple grammar), and generic (e.g., generating the same caption for similar audio clips). When people are asked to describe the content of an audio clip, different people tend to focus on different sound events and describe an audio clip diversely from various aspects using distinct words and grammar. We believe that an audio captioning system should have the ability to generate diverse captions, either for a fixed audio clip, or across similar audio clips. To this end, we propose an adversarial training framework based on a conditional generative adversarial network (C-GAN) to improve diversity of audio captioning systems. A caption generator and two hybrid discriminators compete and are learned jointly, where the caption generator can be any standard encoder-decoder captioning model used to generate captions, and the hybrid discriminators assess the generated captions from different criteria, such as their naturalness and semantics. We conduct experiments on the Clotho dataset. The results show that our proposed model can generate captions with better diversity as compared to state-of-the-art methods.
Visually-Aware Audio Captioning With Adaptive Audio-Visual Attention
Oct 28, 2022Audio captioning is the task of generating captions that describe the content of audio clips. In the real world, many objects produce similar sounds. It is difficult to identify these auditory ambiguous sound events with access to audio information only. How to accurately recognize ambiguous sounds is a major challenge for audio captioning systems. In this work, inspired by the audio-visual multi-modal perception of human beings, we propose visually-aware audio captioning, which makes use of visual information to help the recognition of ambiguous sounding objects. Specifically, we introduce an off-the-shelf visual encoder to process the video inputs, and incorporate the extracted visual features into an audio captioning system. Furthermore, to better exploit complementary contexts from redundant audio-visual streams, we propose an audio-visual attention mechanism that integrates audio and visual information adaptively according to their confidence levels. Experimental results on AudioCaps, the largest publicly available audio captioning dataset, show that the proposed method achieves significant improvement over a strong baseline audio captioning system and is on par with the state-of-the-art result.
Automated Audio Captioning via Fusion of Low- and High- Dimensional Features
Oct 10, 2022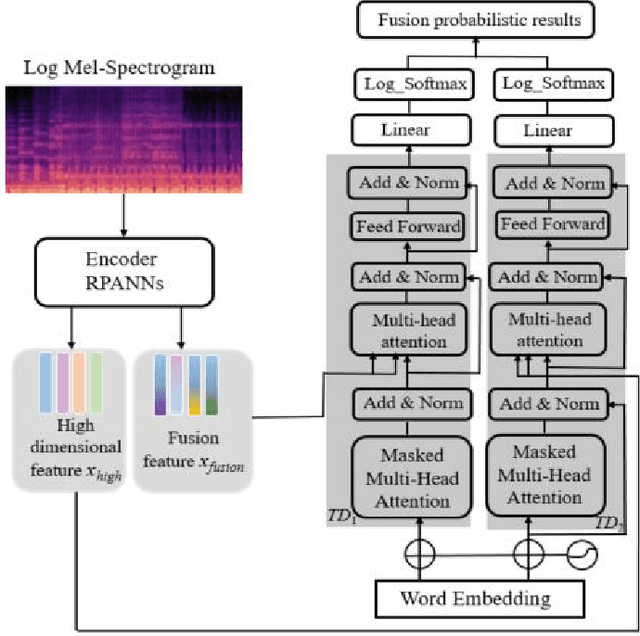
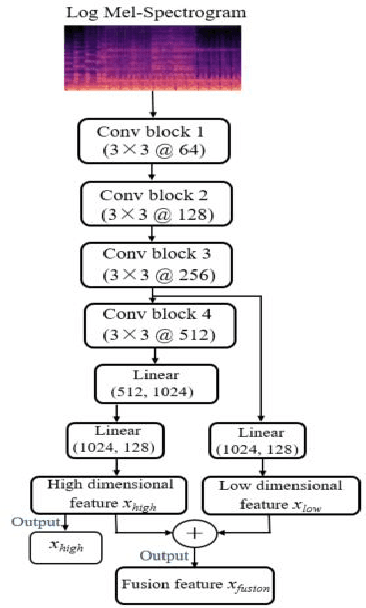
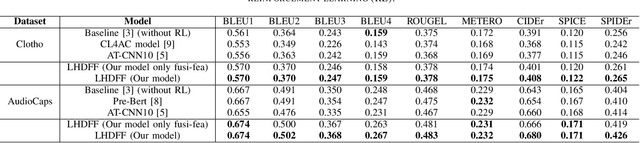
Automated audio captioning (AAC) aims to describe the content of an audio clip using simple sentences. Existing AAC methods are developed based on an encoder-decoder architecture that success is attributed to the use of a pre-trained CNN10 called PANNs as the encoder to learn rich audio representations. AAC is a highly challenging task due to its high-dimensional talent space involves audio of various scenarios. Existing methods only use the high-dimensional representation of the PANNs as the input of the decoder. However, the low-dimension representation may retain as much audio information as the high-dimensional representation may be neglected. In addition, although the high-dimensional approach may predict the audio captions by learning from existing audio captions, which lacks robustness and efficiency. To deal with these challenges, a fusion model which integrates low- and high-dimensional features AAC framework is proposed. In this paper, a new encoder-decoder framework is proposed called the Low- and High-Dimensional Feature Fusion (LHDFF) model for AAC. Moreover, in LHDFF, a new PANNs encoder is proposed called Residual PANNs (RPANNs) by fusing the low-dimensional feature from the intermediate convolution layer output and the high-dimensional feature from the final layer output of PANNs. To fully explore the information of the low- and high-dimensional fusion feature and high-dimensional feature respectively, we proposed dual transformer decoder structures to generate the captions in parallel. Especially, a probabilistic fusion approach is proposed that can ensure the overall performance of the system is improved by concentrating on the respective advantages of the two transformer decoders. Experimental results show that LHDFF achieves the best performance on the Clotho and AudioCaps datasets compared with other existing models
On Metric Learning for Audio-Text Cross-Modal Retrieval
Apr 13, 2022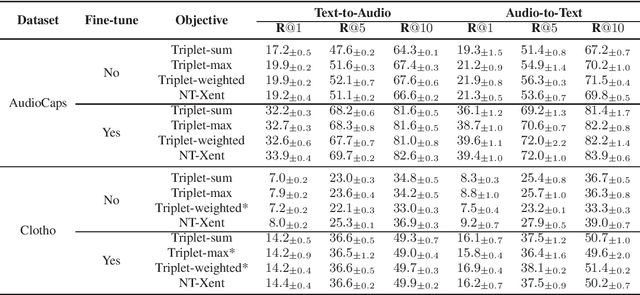
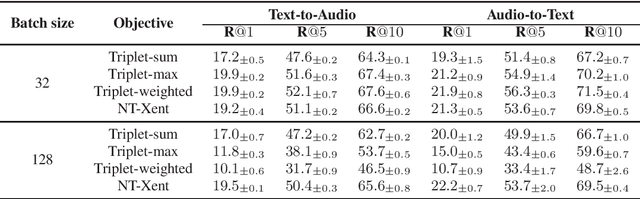
Audio-text retrieval aims at retrieving a target audio clip or caption from a pool of candidates given a query in another modality. Solving such cross-modal retrieval task is challenging because it not only requires learning robust feature representations for both modalities, but also requires capturing the fine-grained alignment between these two modalities. Existing cross-modal retrieval models are mostly optimized by metric learning objectives as both of them attempt to map data to an embedding space, where similar data are close together and dissimilar data are far apart. Unlike other cross-modal retrieval tasks such as image-text and video-text retrievals, audio-text retrieval is still an unexplored task. In this work, we aim to study the impact of different metric learning objectives on the audio-text retrieval task. We present an extensive evaluation of popular metric learning objectives on the AudioCaps and Clotho datasets. We demonstrate that NT-Xent loss adapted from self-supervised learning shows stable performance across different datasets and training settings, and outperforms the popular triplet-based losses.
Leveraging Pre-trained BERT for Audio Captioning
Mar 27, 2022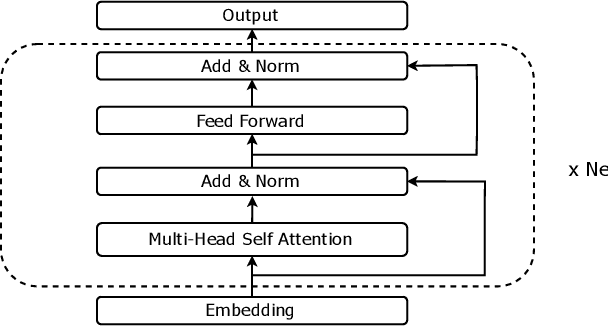
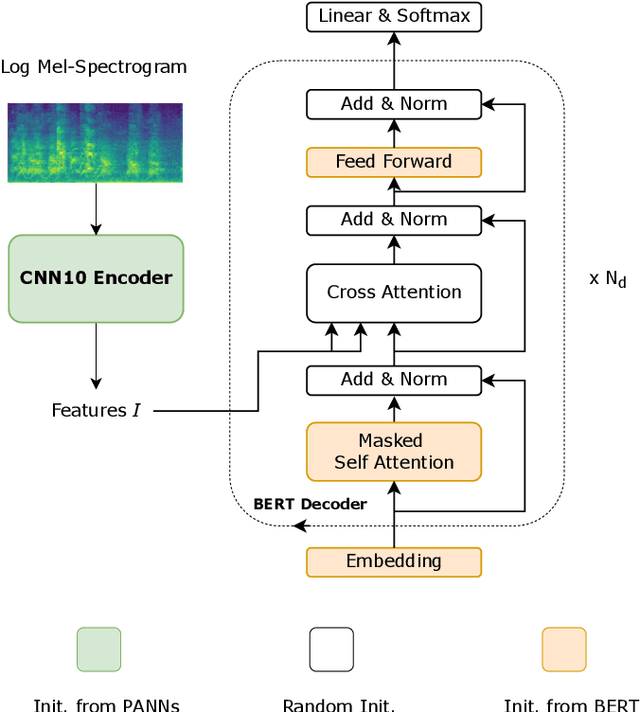
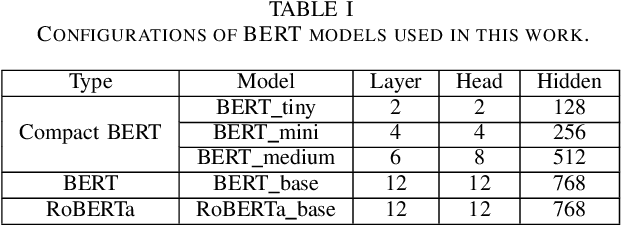
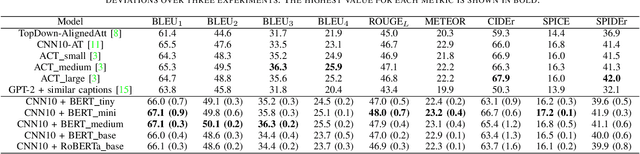
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.
Deep Neural Decision Forest for Acoustic Scene Classification
Mar 07, 2022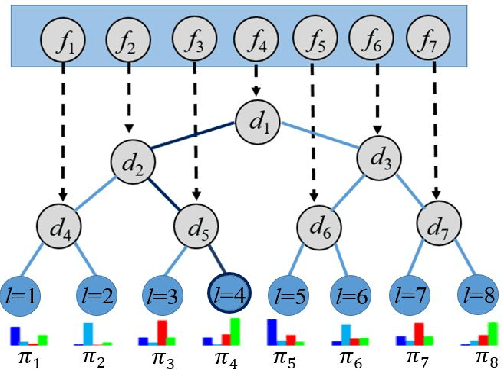
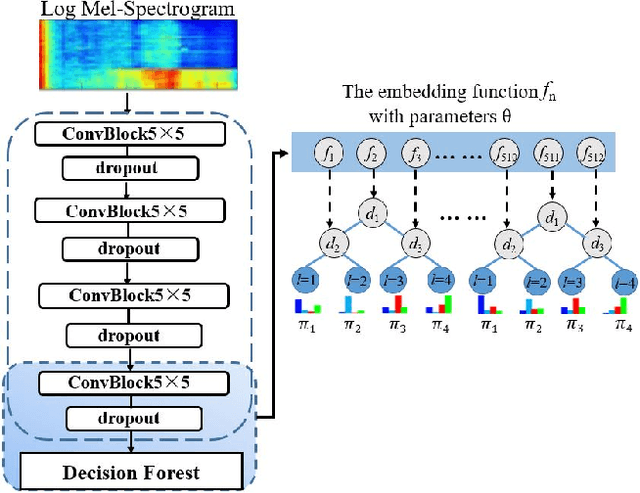

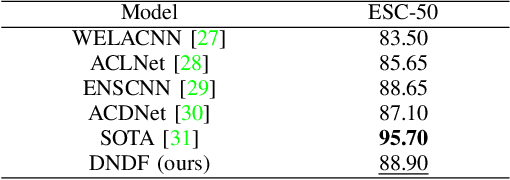
Acoustic scene classification (ASC) aims to classify an audio clip based on the characteristic of the recording environment. In this regard, deep learning based approaches have emerged as a useful tool for ASC problems. Conventional approaches to improving the classification accuracy include integrating auxiliary methods such as attention mechanism, pre-trained models and ensemble multiple sub-networks. However, due to the complexity of audio clips captured from different environments, it is difficult to distinguish their categories without using any auxiliary methods for existing deep learning models using only a single classifier. In this paper, we propose a novel approach for ASC using deep neural decision forest (DNDF). DNDF combines a fixed number of convolutional layers and a decision forest as the final classifier. The decision forest consists of a fixed number of decision tree classifiers, which have been shown to offer better classification performance than a single classifier in some datasets. In particular, the decision forest differs substantially from traditional random forests as it is stochastic, differentiable, and capable of using the back-propagation to update and learn feature representations in neural network. Experimental results on the DCASE2019 and ESC-50 datasets demonstrate that our proposed DNDF method improves the ASC performance in terms of classification accuracy and shows competitive performance as compared with state-of-the-art baselines.
Diverse Audio Captioning via Adversarial Training
Oct 13, 2021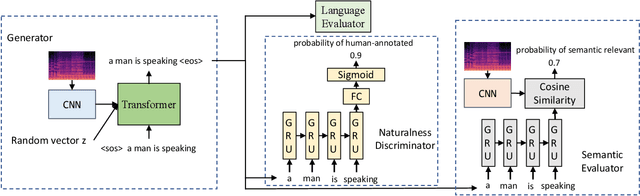


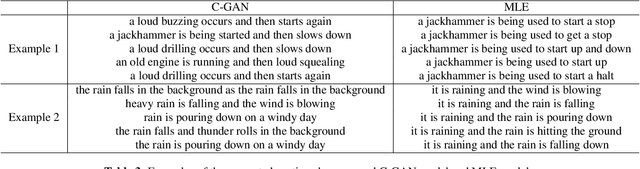
Audio captioning aims at generating natural language descriptions for audio clips automatically. Existing audio captioning models have shown promising improvement in recent years. However, these models are mostly trained via maximum likelihood estimation (MLE),which tends to make captions generic, simple and deterministic. As different people may describe an audio clip from different aspects using distinct words and grammars, we argue that an audio captioning system should have the ability to generate diverse captions for a fixed audio clip and across similar audio clips. To address this problem, we propose an adversarial training framework for audio captioning based on a conditional generative adversarial network (C-GAN), which aims at improving the naturalness and diversity of generated captions. Unlike processing data of continuous values in a classical GAN, a sentence is composed of discrete tokens and the discrete sampling process is non-differentiable. To address this issue, policy gradient, a reinforcement learning technique, is used to back-propagate the reward to the generator. The results show that our proposed model can generate more diverse captions, as compared to state-of-the-art methods.