 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLPrompt: Optimizing Discrete Text Prompts With Reinforcement Learning
May 25, 2022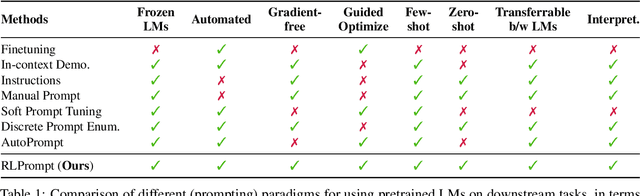
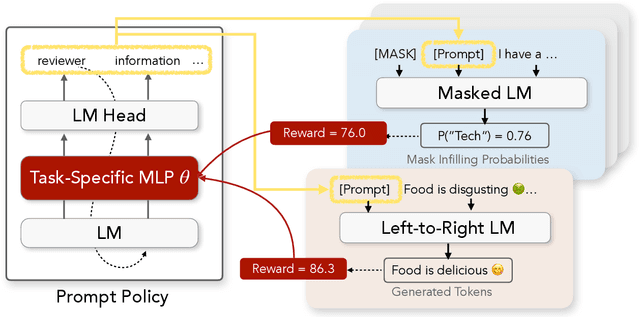
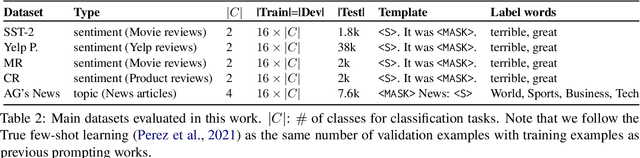
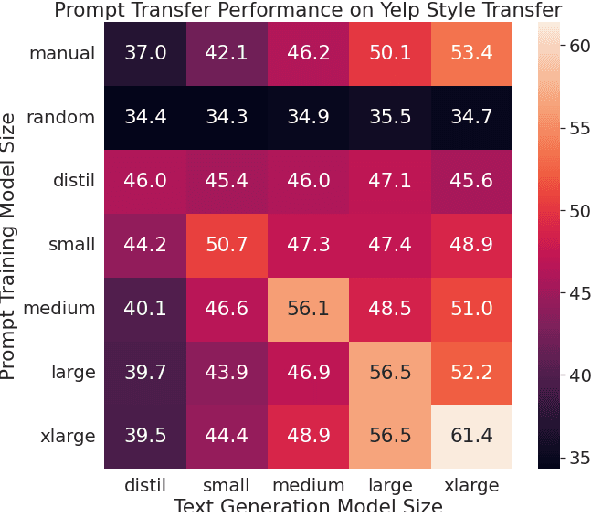
Prompting has shown impressive success in enabling large pretrained language models (LMs) to perform diverse NLP tasks, especially when only few downstream data are available. Automatically finding the optimal prompt for each task, however, is challenging. Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by "enumeration (e.g., paraphrasing)-then-selection" heuristics that do not explore the prompt space systematically. This paper proposes RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt formulates a parameter-efficient policy network that generates the desired discrete prompt after training with reward. To overcome the complexity and stochasticity of reward signals by the large LM environment, we incorporate effective reward stabilization that substantially enhances the training efficiency. RLPrompt is flexibly applicable to different types of LMs, such as masked (e.g., BERT) and left-to-right models (e.g., GPTs), for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods. Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating LM prompting may not follow human language patterns.
FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients
Feb 16, 2022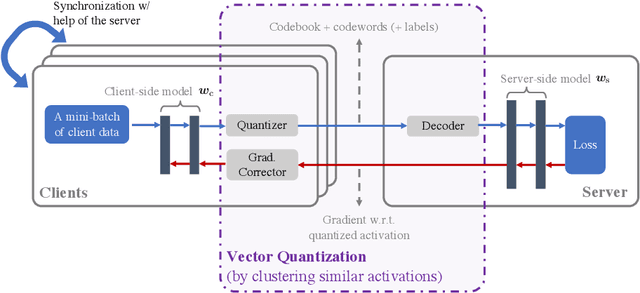

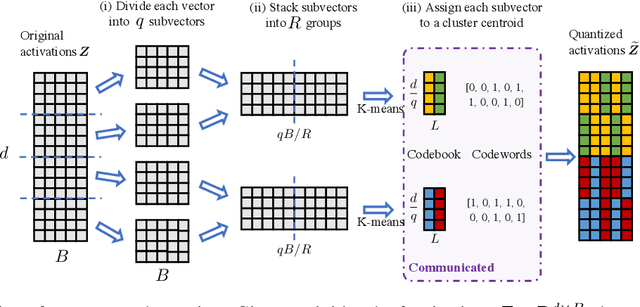
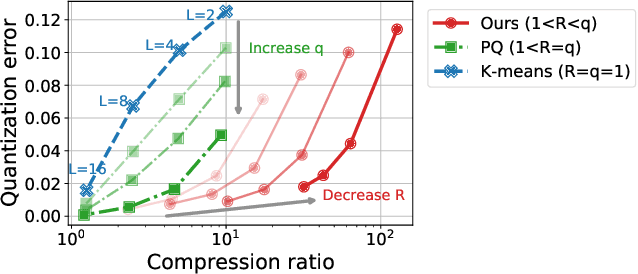
In classical federated learning, the clients contribute to the overall training by communicating local updates for the underlying model on their private data to a coordinating server. However, updating and communicating the entire model becomes prohibitively expensive when resource-constrained clients collectively aim to train a large machine learning model. Split learning provides a natural solution in such a setting, where only a small part of the model is stored and trained on clients while the remaining large part of the model only stays at the servers. However, the model partitioning employed in split learning introduces a significant amount of communication cost. This paper addresses this issue by compressing the additional communication using a novel clustering scheme accompanied by a gradient correction method. Extensive empirical evaluations on image and text benchmarks show that the proposed method can achieve up to $490\times$ communication cost reduction with minimal drop in accuracy, and enables a desirable performance vs. communication trade-off.
Personalized Federated Learning for Heterogeneous Clients with Clustered Knowledge Transfer
Sep 16, 2021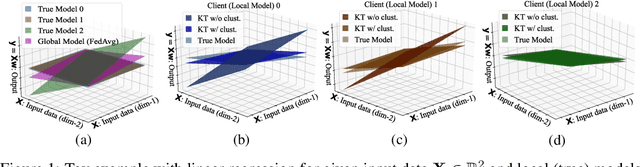
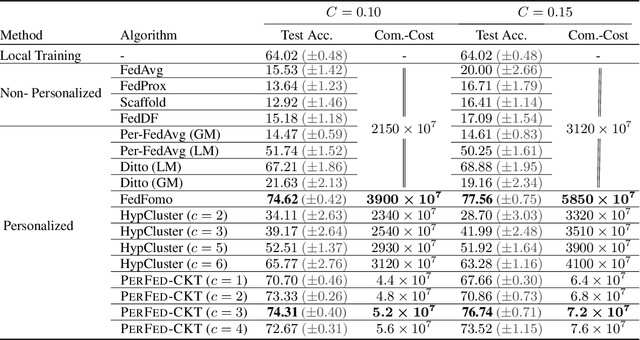
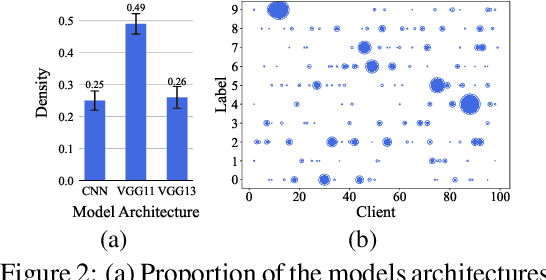
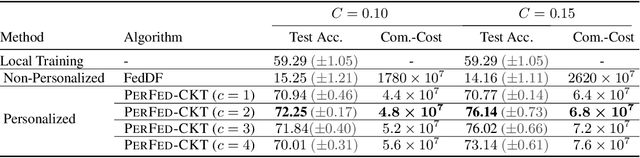
Personalized federated learning (FL) aims to train model(s) that can perform well for individual clients that are highly data and system heterogeneous. Most work in personalized FL, however, assumes using the same model architecture at all clients and increases the communication cost by sending/receiving models. This may not be feasible for realistic scenarios of FL. In practice, clients have highly heterogeneous system-capabilities and limited communication resources. In our work, we propose a personalized FL framework, PerFed-CKT, where clients can use heterogeneous model architectures and do not directly communicate their model parameters. PerFed-CKT uses clustered co-distillation, where clients use logits to transfer their knowledge to other clients that have similar data-distributions. We theoretically show the convergence and generalization properties of PerFed-CKT and empirically show that PerFed-CKT achieves high test accuracy with several orders of magnitude lower communication cost compared to the state-of-the-art personalized FL schemes.
A Field Guide to Federated Optimization
Jul 14, 2021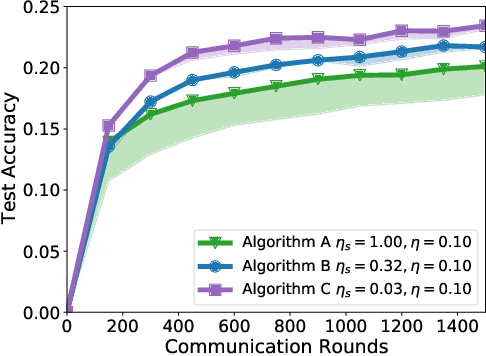


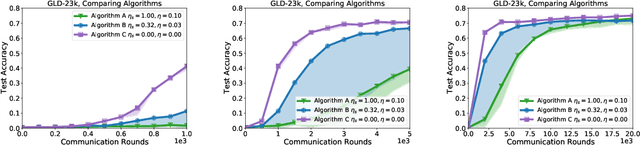
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
DualVGR: A Dual-Visual Graph Reasoning Unit for Video Question Answering
Jul 10, 2021
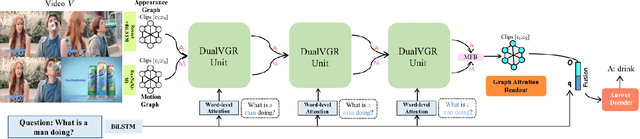
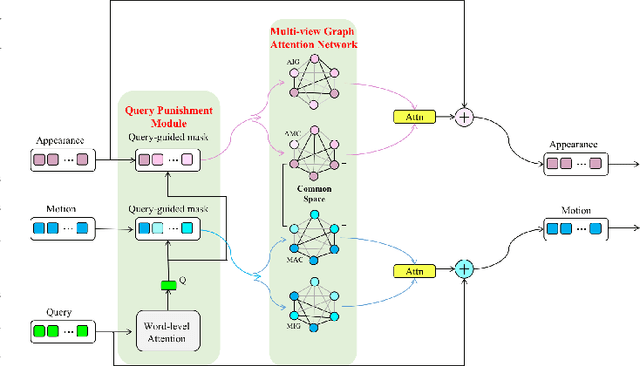
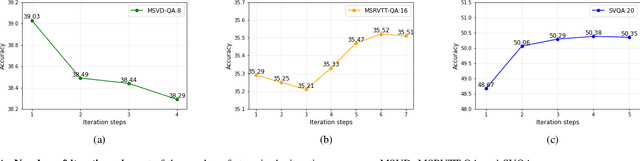
Video question answering is a challenging task, which requires agents to be able to understand rich video contents and perform spatial-temporal reasoning. However, existing graph-based methods fail to perform multi-step reasoning well, neglecting two properties of VideoQA: (1) Even for the same video, different questions may require different amount of video clips or objects to infer the answer with relational reasoning; (2) During reasoning, appearance and motion features have complicated interdependence which are correlated and complementary to each other. Based on these observations, we propose a Dual-Visual Graph Reasoning Unit (DualVGR) which reasons over videos in an end-to-end fashion. The first contribution of our DualVGR is the design of an explainable Query Punishment Module, which can filter out irrelevant visual features through multiple cycles of reasoning. The second contribution is the proposed Video-based Multi-view Graph Attention Network, which captures the relations between appearance and motion features. Our DualVGR network achieves state-of-the-art performance on the benchmark MSVD-QA and SVQA datasets, and demonstrates competitive results on benchmark MSRVTT-QA datasets. Our code is available at https://github.com/MMIR/DualVGR-VideoQA.
* 12 pages, 12 figures
Local Adaptivity in Federated Learning: Convergence and Consistency
Jun 04, 2021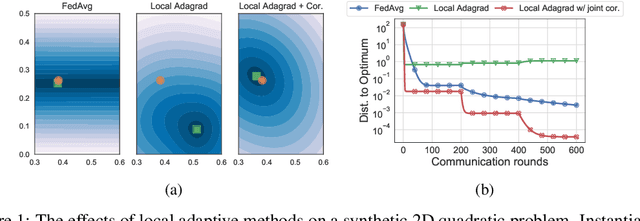

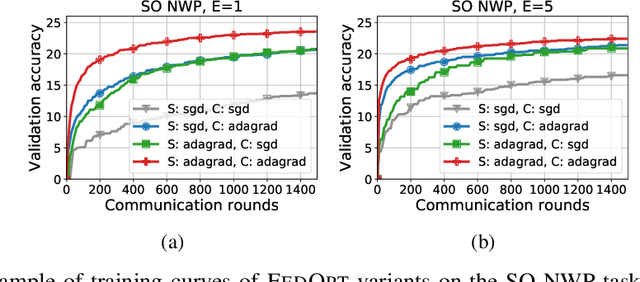
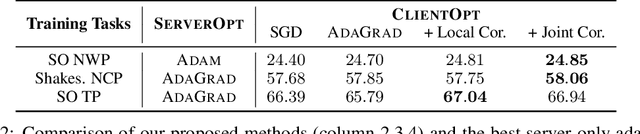
The federated learning (FL) framework trains a machine learning model using decentralized data stored at edge client devices by periodically aggregating locally trained models. Popular optimization algorithms of FL use vanilla (stochastic) gradient descent for both local updates at clients and global updates at the aggregating server. Recently, adaptive optimization methods such as AdaGrad have been studied for server updates. However, the effect of using adaptive optimization methods for local updates at clients is not yet understood. We show in both theory and practice that while local adaptive methods can accelerate convergence, they can cause a non-vanishing solution bias, where the final converged solution may be different from the stationary point of the global objective function. We propose correction techniques to overcome this inconsistency and complement the local adaptive methods for FL. Extensive experiments on realistic federated training tasks show that the proposed algorithms can achieve faster convergence and higher test accuracy than the baselines without local adaptivity.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021
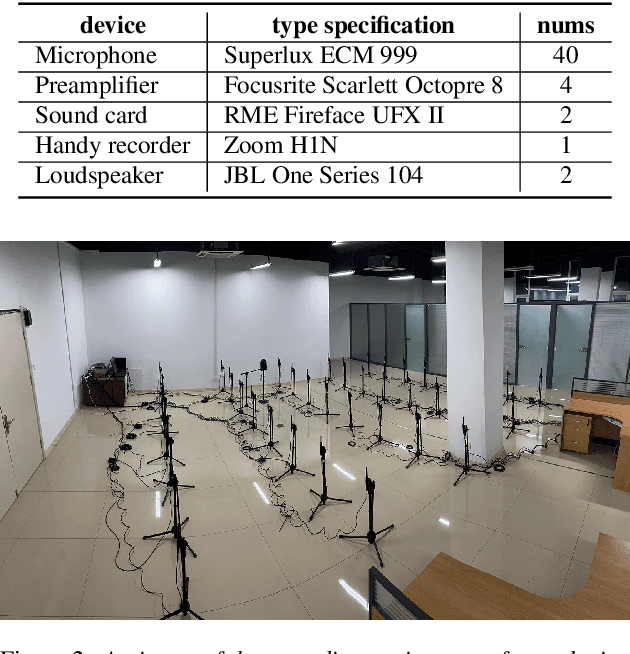
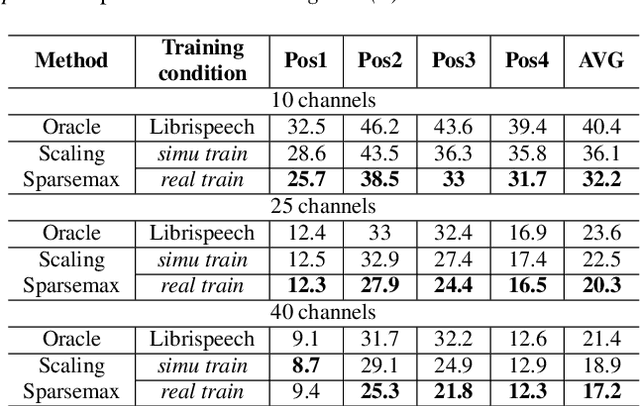
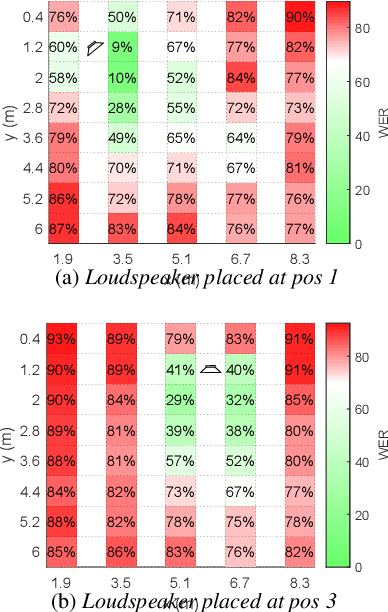
Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Minimum-volume Multichannel Nonnegative matrix factorization for blind source separation
Jan 16, 2021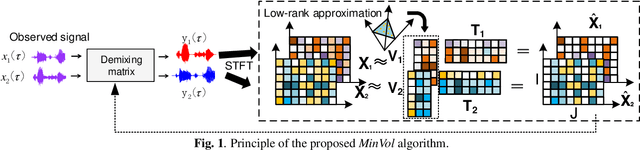
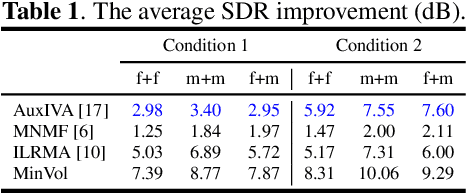

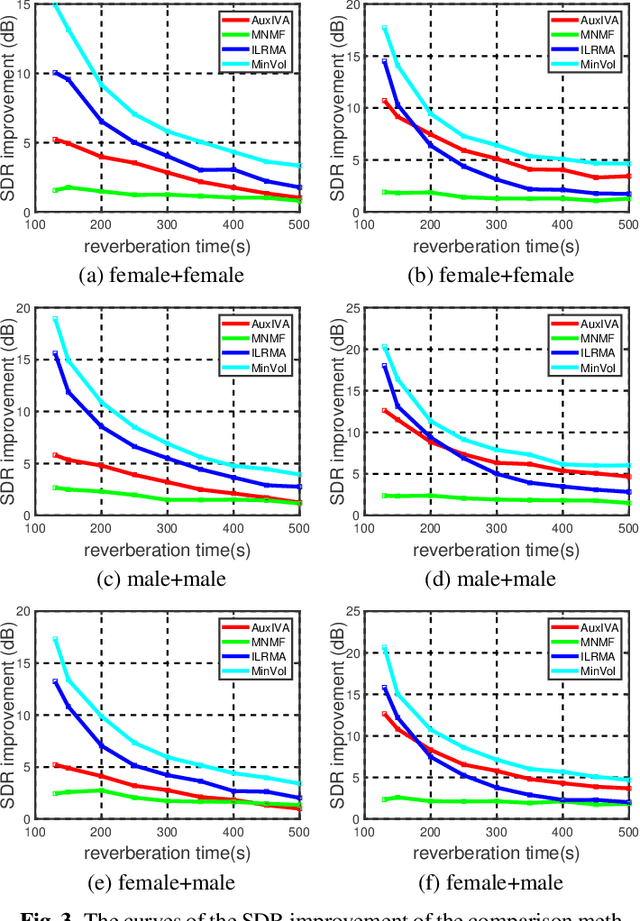
Multichannel blind source separation aims to recover the latent sources from their multichannel mixture without priors. A state-of-art blind source separation method called independent low-rank matrix analysis (ILRMA) unified independent vector analysis (IVA) and nonnegative matrix factorization (NMF). However, speech spectra modeled by NMF may not find a compact representation and it may not guarantee that each source is identifiable. To address the problem, here we propose a modified blind source separation method that enhances the identifiability of the source model. It combines ILRMA with penalty item of volume constraint. The proposed method is optimized by standard majorization-minimization framework based multiplication updating rule, which ensures the stability of convergence. Experimental results demonstrate the effectiveness of the proposed method compared with AuxIVA, MNMF and ILRMA.
Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
Oct 03, 2020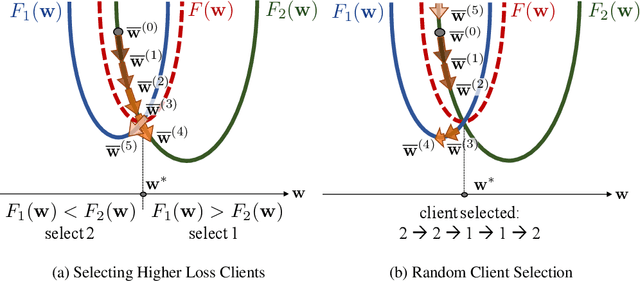

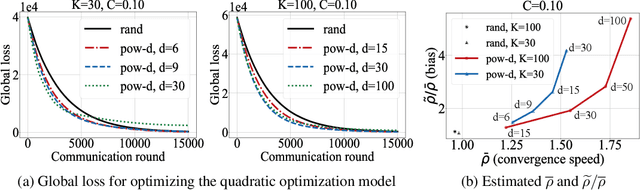

Federated learning is a distributed optimization paradigm that enables a large number of resource-limited client nodes to cooperatively train a model without data sharing. Several works have analyzed the convergence of federated learning by accounting of data heterogeneity, communication and computation limitations, and partial client participation. However, they assume unbiased client participation, where clients are selected at random or in proportion of their data sizes. In this paper, we present the first convergence analysis of federated optimization for biased client selection strategies, and quantify how the selection bias affects convergence speed. We reveal that biasing client selection towards clients with higher local loss achieves faster error convergence. Using this insight, we propose Power-of-Choice, a communication- and computation-efficient client selection framework that can flexibly span the trade-off between convergence speed and solution bias. Our experiments demonstrate that Power-of-Choice strategies converge up to 3 $\times$ faster and give $10$% higher test accuracy than the baseline random selection.
Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization
Jul 15, 2020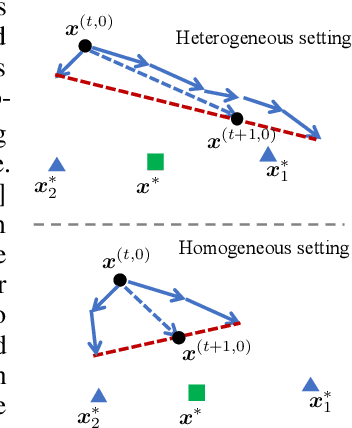

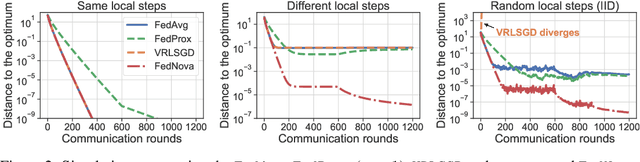
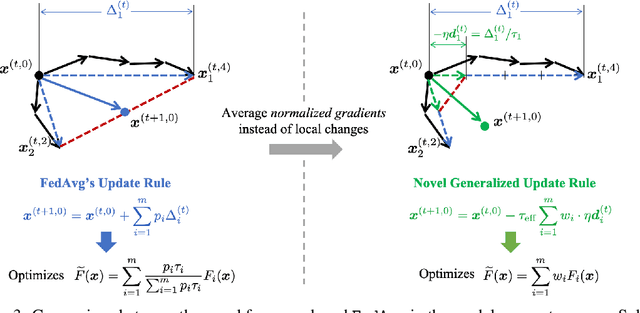
In federated optimization, heterogeneity in the clients' local datasets and computation speeds results in large variations in the number of local updates performed by each client in each communication round. Naive weighted aggregation of such models causes objective inconsistency, that is, the global model converges to a stationary point of a mismatched objective function which can be arbitrarily different from the true objective. This paper provides a general framework to analyze the convergence of federated heterogeneous optimization algorithms. It subsumes previously proposed methods such as FedAvg and FedProx and provides the first principled understanding of the solution bias and the convergence slowdown due to objective inconsistency. Using insights from this analysis, we propose FedNova, a normalized averaging method that eliminates objective inconsistency while preserving fast error convergence.