 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOUD: Contrastive Learning of Unsupervised Dynamics
Oct 23, 2020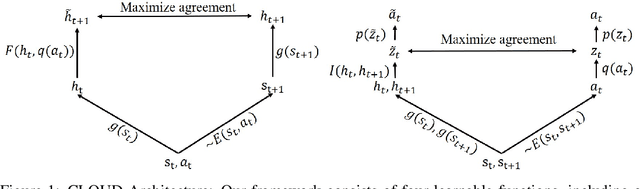
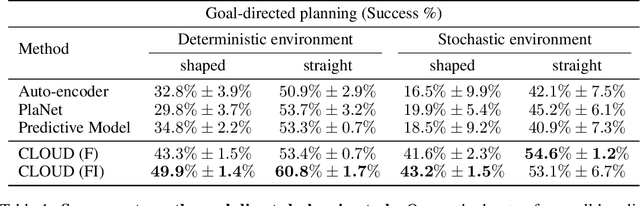

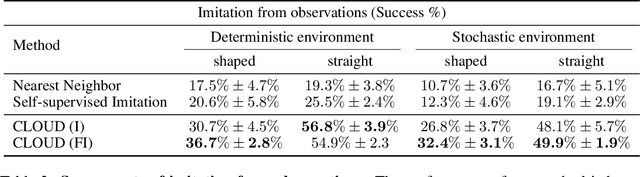
Developing agents that can perform complex control tasks from high dimensional observations such as pixels is challenging due to difficulties in learning dynamics efficiently. In this work, we propose to learn forward and inverse dynamics in a fully unsupervised manner via contrastive estimation. Specifically, we train a forward dynamics model and an inverse dynamics model in the feature space of states and actions with data collected from random exploration. Unlike most existing deterministic models, our energy-based model takes into account the stochastic nature of agent-environment interactions. We demonstrate the efficacy of our approach across a variety of tasks including goal-directed planning and imitation from observations. Project videos and code are at https://jianrenw.github.io/cloud/.
SEMI: Self-supervised Exploration via Multisensory Incongruity
Sep 26, 2020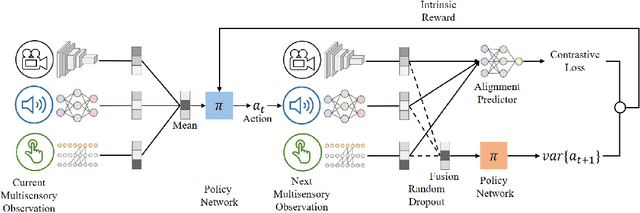
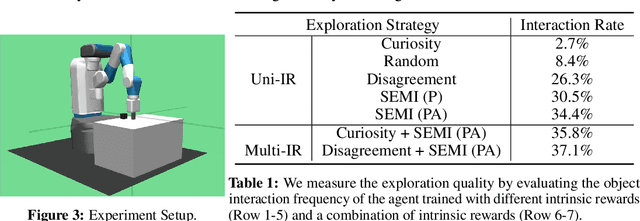
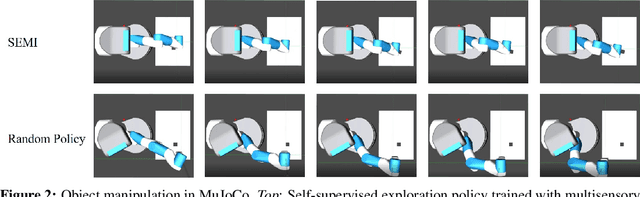
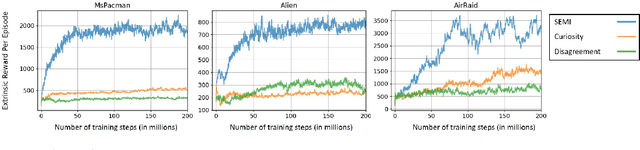
Efficient exploration is a long-standing problem in reinforcement learning. In this work, we introduce a self-supervised exploration policy by incentivizing the agent to maximize multisensory incongruity, which can be measured in two aspects: perception incongruity and action incongruity. The former represents the uncertainty in multisensory fusion model, while the latter represents the uncertainty in an agent's policy. Specifically, an alignment predictor is trained to detect whether multiple sensory inputs are aligned, the error of which is used to measure perception incongruity. The policy takes the multisensory observations with sensory-wise dropout as input and outputs actions for exploration. The variance of actions is further used to measure action incongruity. Our formulation allows the agent to learn skills by exploring in a self-supervised manner without any external rewards. Besides, our method enables the agent to learn a compact multimodal representation from hard examples, which further improves the sample efficiency of our policy learning. We demonstrate the efficacy of this formulation across a variety of benchmark environments including object manipulation and audio-visual games.
Uncertainty-aware Self-supervised 3D Data Association
Aug 18, 2020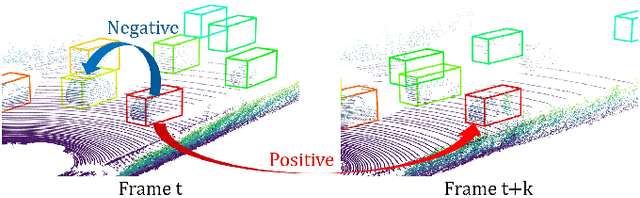

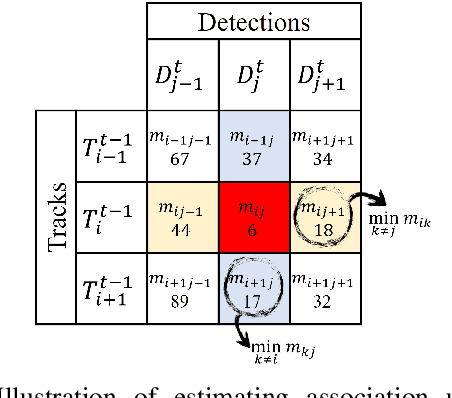
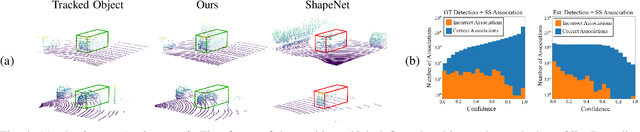
3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking. Project videos and code are at https://jianrenw.github.io/Self-Supervised-3D-Data-Association.
AB3DMOT: A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics
Aug 18, 2020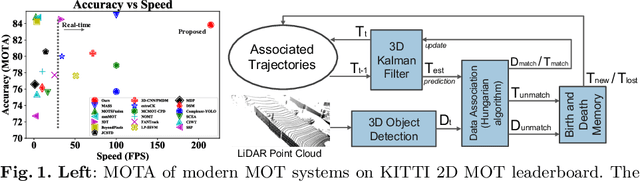
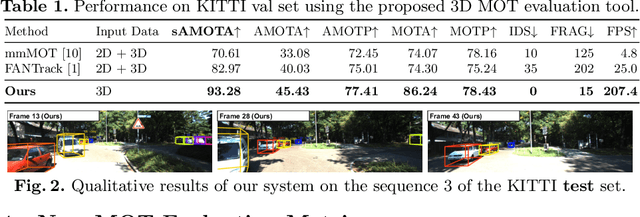
3D multi-object tracking (MOT) is essential to applications such as autonomous driving. Recent work focuses on developing accurate systems giving less attention to computational cost and system complexity. In contrast, this work proposes a simple real-time 3D MOT system with strong performance. Our system first obtains 3D detections from a LiDAR point cloud. Then, a straightforward combination of a 3D Kalman filter and the Hungarian algorithm is used for state estimation and data association. Additionally, 3D MOT datasets such as KITTI evaluate MOT methods in 2D space and standardized 3D MOT evaluation tools are missing for a fair comparison of 3D MOT methods. We propose a new 3D MOT evaluation tool along with three new metrics to comprehensively evaluate 3D MOT methods. We show that, our proposed method achieves strong 3D MOT performance on KITTI and runs at a rate of $207.4$ FPS on the KITTI dataset, achieving the fastest speed among modern 3D MOT systems. Our code is publicly available at http://www.xinshuoweng.com/projects/AB3DMOT.
PanoNet: Real-time Panoptic Segmentation through Position-Sensitive Feature Embedding
Aug 01, 2020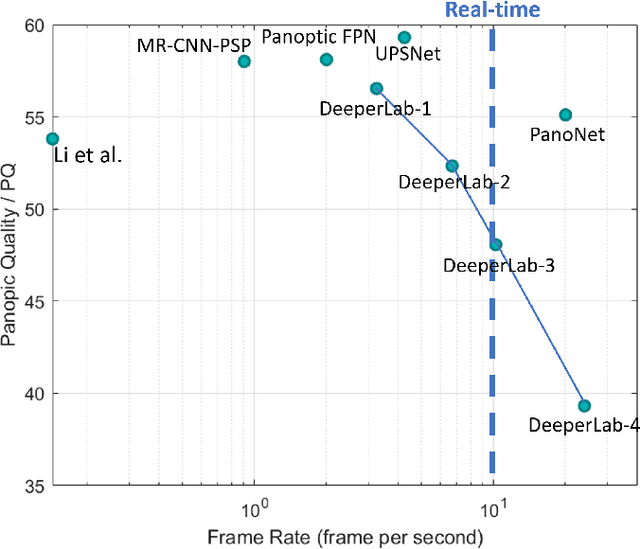
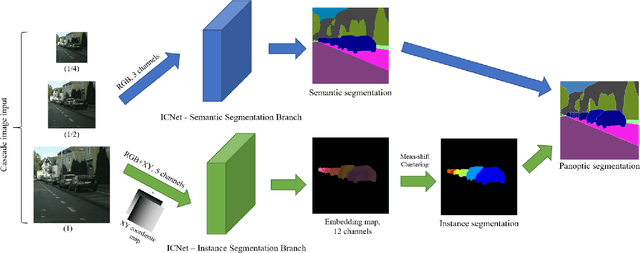


We propose a simple, fast, and flexible framework to generate simultaneously semantic and instance masks for panoptic segmentation. Our method, called PanoNet, incorporates a clean and natural structure design that tackles the problem purely as a segmentation task without the time-consuming detection process. We also introduce position-sensitive embedding for instance grouping by accounting for both object's appearance and its spatial location. Overall, PanoNet yields high panoptic quality results of high-resolution Cityscapes images in real-time, significantly faster than all other methods with comparable performance. Our approach well satisfies the practical speed and memory requirement for many applications like autonomous driving and augmented reality.
Motion Prediction in Visual Object Tracking
Jul 01, 2020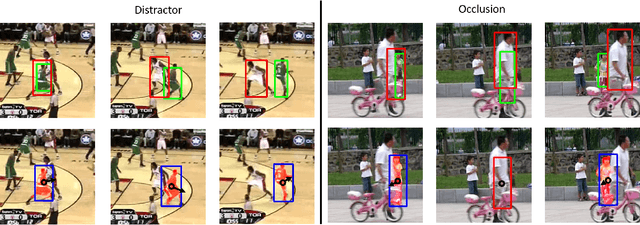



Visual object tracking (VOT) is an essential component for many applications, such as autonomous driving or assistive robotics. However, recent works tend to develop accurate systems based on more computationally expensive feature extractors for better instance matching. In contrast, this work addresses the importance of motion prediction in VOT. We use an off-the-shelf object detector to obtain instance bounding boxes. Then, a combination of camera motion decouple and Kalman filter is used for state estimation. Although our baseline system is a straightforward combination of standard methods, we obtain state-of-the-art results. Our method establishes new state-of-the-art performance on VOT (VOT-2016 and VOT-2018). Our proposed method improves the EAO on VOT-2016 from 0.472 of prior art to 0.505, from 0.410 to 0.431 on VOT-2018. To show the generalizability, we also test our method on video object segmentation (VOS: DAVIS-2016 and DAVIS-2017) and observe consistent improvement.
Unsupervised Sequence Forecasting of 100,000 Points for Unsupervised Trajectory Forecasting
Mar 29, 2020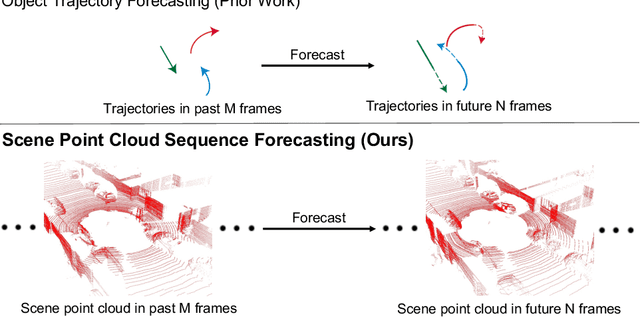
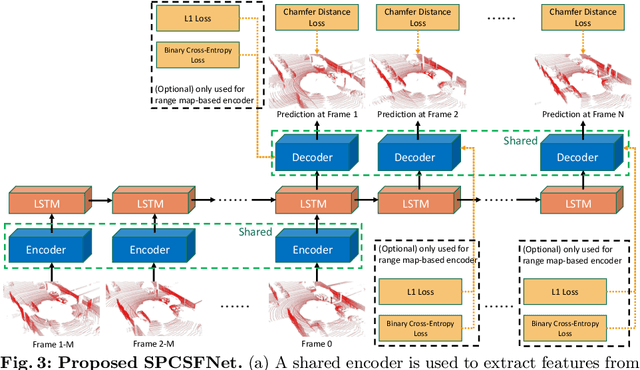
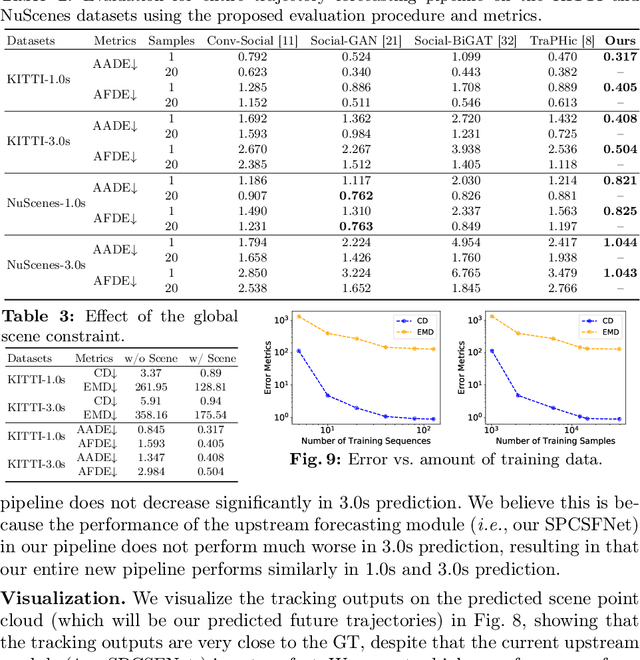
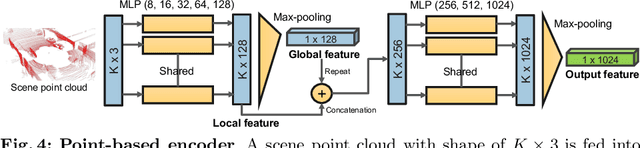
Predicting the future is a crucial first step to effective control, since systems that can predict the future can select plans that lead to desired outcomes. In this work, we study the problem of future prediction at the level of 3D scenes, represented by point clouds captured by a LiDAR sensor, i.e., directly learning to forecast the evolution of >100,000 points that comprise a complete scene. We term this Scene Point Cloud Sequence Forecasting (SPCSF). By directly predicting the densest-possible 3D representation of the future, the output contains richer information than other representations such as future object trajectories. We design a method, SPCSFNet, evaluate it on the KITTI and nuScenes datasets, and find that it demonstrates excellent performance on the SPCSF task. To show that SPCSF can benefit downstream tasks such as object trajectory forecasting, we present a new object trajectory forecasting pipeline leveraging SPCSFNet. Specifically, instead of forecasting at the object level as in conventional trajectory forecasting, we propose to forecast at the sensor level and then apply detection and tracking on the predicted sensor data. As a result, our new pipeline can remove the need of object trajectory labels and enable large-scale training with unlabeled sensor data. Surprisingly, we found our new pipeline based on SPCSFNet was able to outperform the conventional pipeline using state-of-the-art trajectory forecasting methods, all of which require future object trajectory labels. Finally, we propose a new evaluation procedure and two new metrics to measure the end-to-end performance of the trajectory forecasting pipeline. Our code will be made publicly available at https://github.com/xinshuoweng/SPCSF
AlignNet: A Unifying Approach to Audio-Visual Alignment
Feb 12, 2020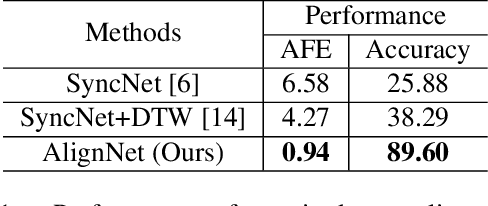
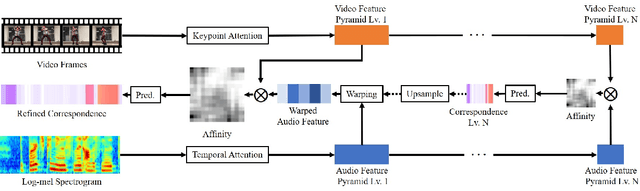

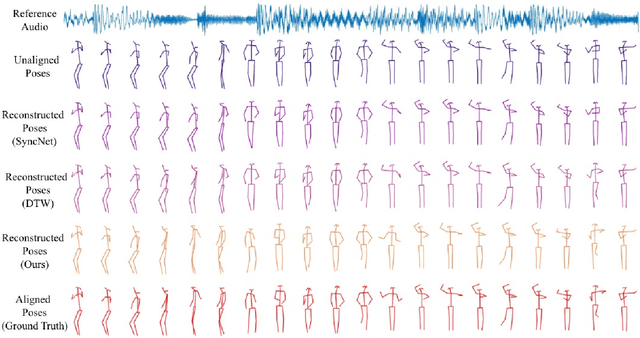
We present AlignNet, a model that synchronizes videos with reference audios under non-uniform and irregular misalignments. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed according to simple and well-established principles: attention, pyramidal processing, warping, and affinity function. Together with the model, we release a dancing dataset Dance50 for training and evaluation. Qualitative, quantitative and subjective evaluation results on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of-the-art methods. Project video and code are available at https://jianrenw.github.io/AlignNet.
Deep Multivariate Mixture of Gaussians for Object Detection under Occlusion
Nov 24, 2019
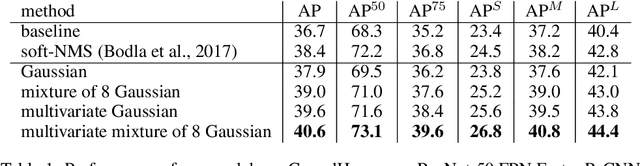
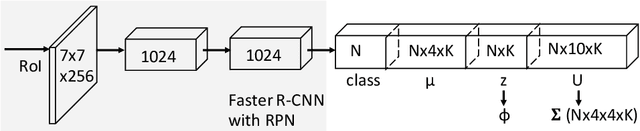

In this paper, we consider the problem of detecting object under occlusion. Most object detectors formulate bounding box regression as a unimodal task (i.e., regressing a single set of bounding box coordinates independently). However, we observe that the bounding box borders of an occluded object can have multiple plausible configurations. Also, the occluded bounding box borders have correlations with visible ones. Motivated by these two observations, we propose a deep multivariate mixture of Gaussians model for bounding box regression under occlusion. The mixture components potentially learn different configurations of an occluded part, and the covariances between variates help to learn the relationship between the occluded parts and the visible ones. Quantitatively, our model improves the AP of the baselines by 3.9% and 1.2% on CrowdHuman and MS-COCO respectively with almost no computational or memory overhead. Qualitatively, our model enjoys explainability since we can interpret the resulting bounding boxes via the covariance matrices and the mixture components.
Depth-wise Decomposition for Accelerating Separable Convolutions in Efficient Convolutional Neural Networks
Oct 21, 2019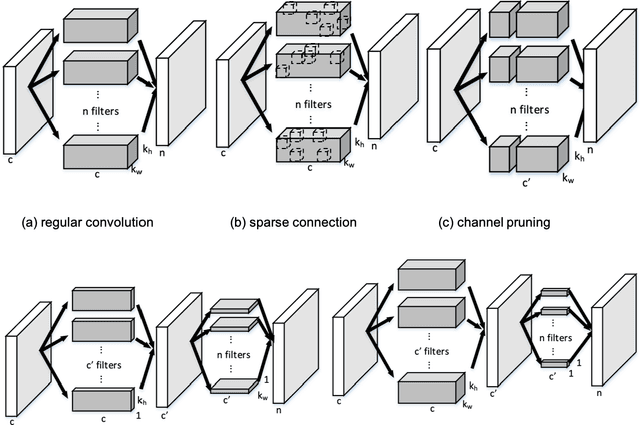
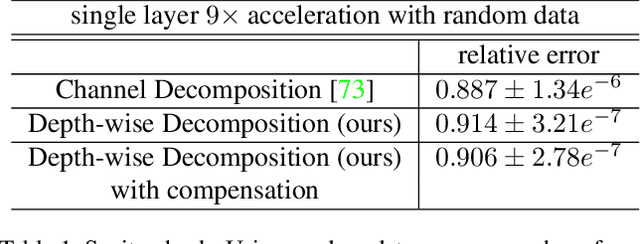


Very deep convolutional neural networks (CNNs) have been firmly established as the primary methods for many computer vision tasks. However, most state-of-the-art CNNs are large, which results in high inference latency. Recently, depth-wise separable convolution has been proposed for image recognition tasks on computationally limited platforms such as robotics and self-driving cars. Though it is much faster than its counterpart, regular convolution, accuracy is sacrificed. In this paper, we propose a novel decomposition approach based on SVD, namely depth-wise decomposition, for expanding regular convolutions into depthwise separable convolutions while maintaining high accuracy. We show our approach can be further generalized to the multi-channel and multi-layer cases, based on Generalized Singular Value Decomposition (GSVD) [59]. We conduct thorough experiments with the latest ShuffleNet V2 model [47] on both random synthesized dataset and a large-scale image recognition dataset: ImageNet [10]. Our approach outperforms channel decomposition [73] on all datasets. More importantly, our approach improves the Top-1 accuracy of ShuffleNet V2 by ~2%.