 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generation
Mar 16, 2023



Language-guided image generation has achieved great success nowadays by using diffusion models. However, texts can be less detailed to describe highly-specific subjects such as a particular dog or a certain car, which makes pure text-to-image generation not accurate enough to satisfy user requirements. In this work, we present a novel Unified Multi-Modal Latent Diffusion (UMM-Diffusion) which takes joint texts and images containing specified subjects as input sequences and generates customized images with the subjects. To be more specific, both input texts and images are encoded into one unified multi-modal latent space, in which the input images are learned to be projected to pseudo word embedding and can be further combined with text to guide image generation. Besides, to eliminate the irrelevant parts of the input images such as background or illumination, we propose a novel sampling technique of diffusion models used by the image generator which fuses the results guided by multi-modal input and pure text input. By leveraging the large-scale pre-trained text-to-image generator and the designed image encoder, our method is able to generate high-quality images with complex semantics from both aspects of input texts and images.
Learning Spatiotemporal Frequency-Transformer for Low-Quality Video Super-Resolution
Dec 27, 2022Video Super-Resolution (VSR) aims to restore high-resolution (HR) videos from low-resolution (LR) videos. Existing VSR techniques usually recover HR frames by extracting pertinent textures from nearby frames with known degradation processes. Despite significant progress, grand challenges are remained to effectively extract and transmit high-quality textures from high-degraded low-quality sequences, such as blur, additive noises, and compression artifacts. In this work, a novel Frequency-Transformer (FTVSR) is proposed for handling low-quality videos that carry out self-attention in a combined space-time-frequency domain. First, video frames are split into patches and each patch is transformed into spectral maps in which each channel represents a frequency band. It permits a fine-grained self-attention on each frequency band, so that real visual texture can be distinguished from artifacts. Second, a novel dual frequency attention (DFA) mechanism is proposed to capture the global frequency relations and local frequency relations, which can handle different complicated degradation processes in real-world scenarios. Third, we explore different self-attention schemes for video processing in the frequency domain and discover that a ``divided attention'' which conducts a joint space-frequency attention before applying temporal-frequency attention, leads to the best video enhancement quality. Extensive experiments on three widely-used VSR datasets show that FTVSR outperforms state-of-the-art methods on different low-quality videos with clear visual margins. Code and pre-trained models are available at https://github.com/researchmm/FTVSR.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Dec 19, 2022We propose the first joint audio-video generation framework that brings engaging watching and listening experiences simultaneously, towards high-quality realistic videos. To generate joint audio-video pairs, we propose a novel Multi-Modal Diffusion model (i.e., MM-Diffusion), with two-coupled denoising autoencoders. In contrast to existing single-modal diffusion models, MM-Diffusion consists of a sequential multi-modal U-Net for a joint denoising process by design. Two subnets for audio and video learn to gradually generate aligned audio-video pairs from Gaussian noises. To ensure semantic consistency across modalities, we propose a novel random-shift based attention block bridging over the two subnets, which enables efficient cross-modal alignment, and thus reinforces the audio-video fidelity for each other. Extensive experiments show superior results in unconditional audio-video generation, and zero-shot conditional tasks (e.g., video-to-audio). In particular, we achieve the best FVD and FAD on Landscape and AIST++ dancing datasets. Turing tests of 10k votes further demonstrate dominant preferences for our model. The code and pre-trained models can be downloaded at https://github.com/researchmm/MM-Diffusion.
Weakly-supervised Pre-training for 3D Human Pose Estimation via Perspective Knowledge
Nov 22, 2022



Modern deep learning-based 3D pose estimation approaches require plenty of 3D pose annotations. However, existing 3D datasets lack diversity, which limits the performance of current methods and their generalization ability. Although existing methods utilize 2D pose annotations to help 3D pose estimation, they mainly focus on extracting 2D structural constraints from 2D poses, ignoring the 3D information hidden in the images. In this paper, we propose a novel method to extract weak 3D information directly from 2D images without 3D pose supervision. Firstly, we utilize 2D pose annotations and perspective prior knowledge to generate the relationship of that keypoint is closer or farther from the camera, called relative depth. We collect a 2D pose dataset (MCPC) and generate relative depth labels. Based on MCPC, we propose a weakly-supervised pre-training (WSP) strategy to distinguish the depth relationship between two points in an image. WSP enables the learning of the relative depth of two keypoints on lots of in-the-wild images, which is more capable of predicting depth and generalization ability for 3D human pose estimation. After fine-tuning on 3D pose datasets, WSP achieves state-of-the-art results on two widely-used benchmarks.
Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning
Oct 12, 2022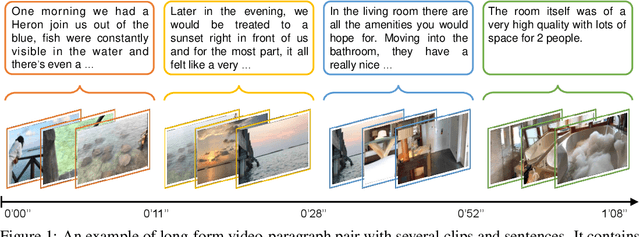
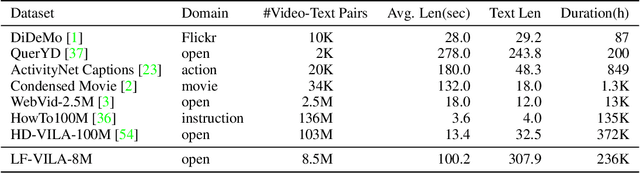
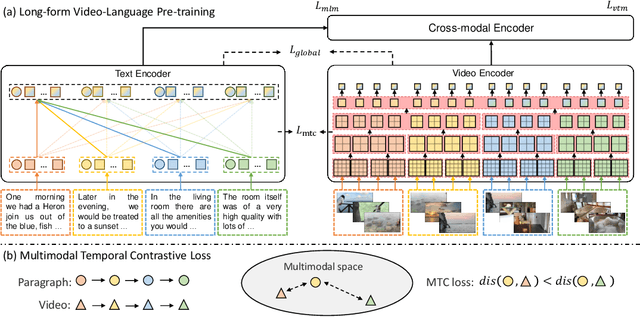
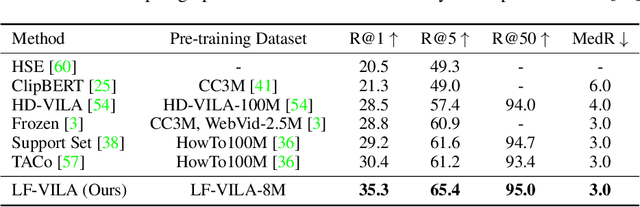
Large-scale video-language pre-training has shown significant improvement in video-language understanding tasks. Previous studies of video-language pretraining mainly focus on short-form videos (i.e., within 30 seconds) and sentences, leaving long-form video-language pre-training rarely explored. Directly learning representation from long-form videos and language may benefit many long-form video-language understanding tasks. However, it is challenging due to the difficulty of modeling long-range relationships and the heavy computational burden caused by more frames. In this paper, we introduce a Long-Form VIdeo-LAnguage pre-training model (LF-VILA) and train it on a large-scale long-form video and paragraph dataset constructed from an existing public dataset. To effectively capture the rich temporal dynamics and to better align video and language in an efficient end-to-end manner, we introduce two novel designs in our LF-VILA model. We first propose a Multimodal Temporal Contrastive (MTC) loss to learn the temporal relation across different modalities by encouraging fine-grained alignment between long-form videos and paragraphs. Second, we propose a Hierarchical Temporal Window Attention (HTWA) mechanism to effectively capture long-range dependency while reducing computational cost in Transformer. We fine-tune the pre-trained LF-VILA model on seven downstream long-form video-language understanding tasks of paragraph-to-video retrieval and long-form video question-answering, and achieve new state-of-the-art performances. Specifically, our model achieves 16.1% relative improvement on ActivityNet paragraph-to-video retrieval task and 2.4% on How2QA task, respectively. We release our code, dataset, and pre-trained models at https://github.com/microsoft/XPretrain.
Fine-Grained Image Style Transfer with Visual Transformers
Oct 11, 2022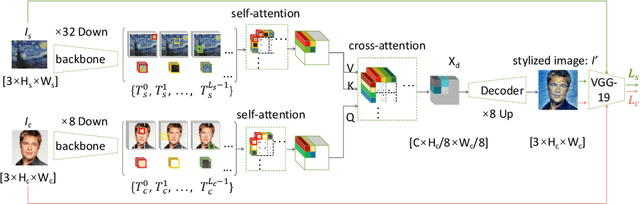
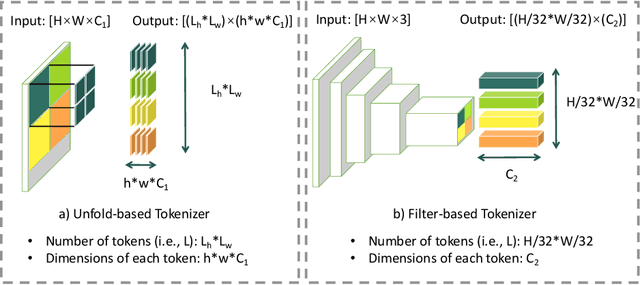

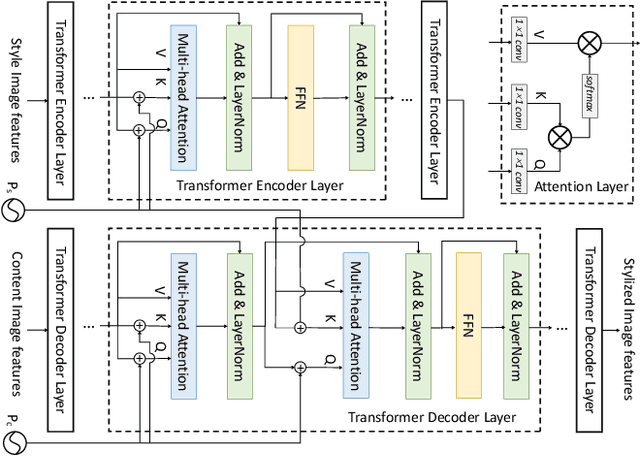
With the development of the convolutional neural network, image style transfer has drawn increasing attention. However, most existing approaches adopt a global feature transformation to transfer style patterns into content images (e.g., AdaIN and WCT). Such a design usually destroys the spatial information of the input images and fails to transfer fine-grained style patterns into style transfer results. To solve this problem, we propose a novel STyle TRansformer (STTR) network which breaks both content and style images into visual tokens to achieve a fine-grained style transformation. Specifically, two attention mechanisms are adopted in our STTR. We first propose to use self-attention to encode content and style tokens such that similar tokens can be grouped and learned together. We then adopt cross-attention between content and style tokens that encourages fine-grained style transformations. To compare STTR with existing approaches, we conduct user studies on Amazon Mechanical Turk (AMT), which are carried out with 50 human subjects with 1,000 votes in total. Extensive evaluations demonstrate the effectiveness and efficiency of the proposed STTR in generating visually pleasing style transfer results.
CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment
Sep 23, 2022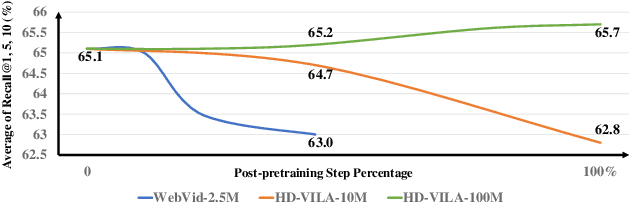
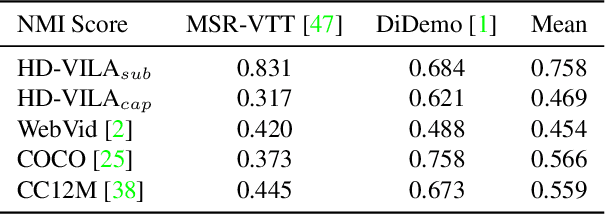
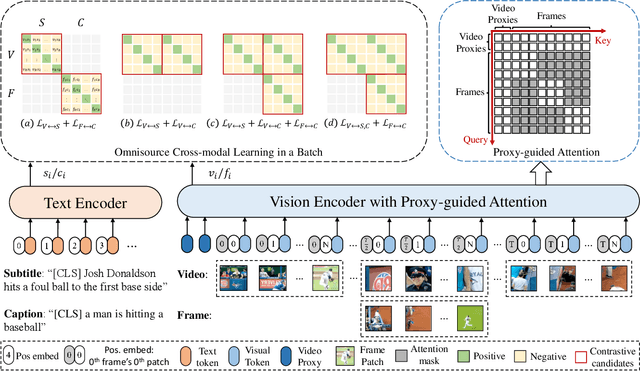
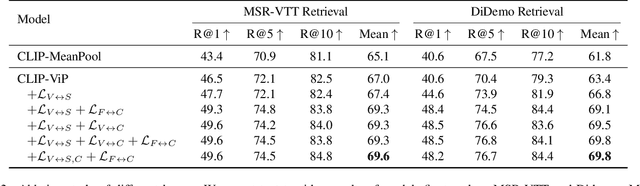
The pre-trained image-text models, like CLIP, have demonstrated the strong power of vision-language representation learned from a large scale of web-collected image-text data. In light of the well-learned visual features, some existing works transfer image representation to video domain and achieve good results. However, how to utilize image-language pre-trained model (e.g., CLIP) for video-language pre-training (post-pretraining) is still under explored. In this paper, we investigate two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? Through a series of comparative experiments and analyses, we find that the data scale and domain gap between language sources have great impacts. Motivated by these, we propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP. Extensive results show that our approach improves the performance of CLIP on video-text retrieval by a large margin. Our model also achieves SOTA results on a variety of datasets, including MSR-VTT, DiDeMo, LSMDC, and ActivityNet. We will release our code and pre-trained CLIP-ViP models at https://github.com/microsoft/XPretrain/tree/main/CLIP-ViP.
AI Illustrator: Translating Raw Descriptions into Images by Prompt-based Cross-Modal Generation
Sep 08, 2022
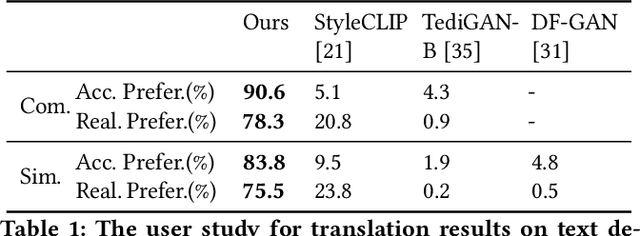
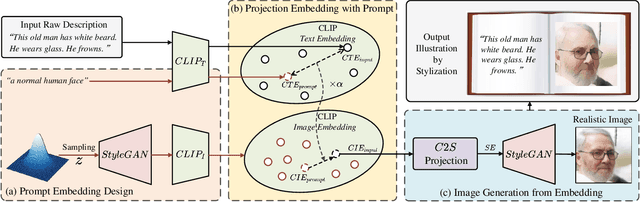
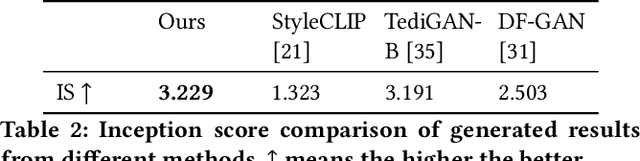
AI illustrator aims to automatically design visually appealing images for books to provoke rich thoughts and emotions. To achieve this goal, we propose a framework for translating raw descriptions with complex semantics into semantically corresponding images. The main challenge lies in the complexity of the semantics of raw descriptions, which may be hard to be visualized (e.g., "gloomy" or "Asian"). It usually poses challenges for existing methods to handle such descriptions. To address this issue, we propose a Prompt-based Cross-Modal Generation Framework (PCM-Frame) to leverage two powerful pre-trained models, including CLIP and StyleGAN. Our framework consists of two components: a projection module from Text Embeddings to Image Embeddings based on prompts, and an adapted image generation module built on StyleGAN which takes Image Embeddings as inputs and is trained by combined semantic consistency losses. To bridge the gap between realistic images and illustration designs, we further adopt a stylization model as post-processing in our framework for better visual effects. Benefiting from the pre-trained models, our method can handle complex descriptions and does not require external paired data for training. Furthermore, we have built a benchmark that consists of 200 raw descriptions. We conduct a user study to demonstrate our superiority over the competing methods with complicated texts. We release our code at https://github.com/researchmm/AI_Illustrator.
4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
Sep 05, 2022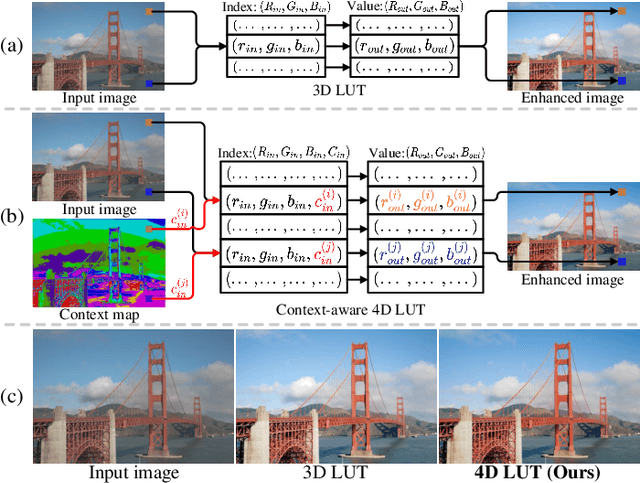
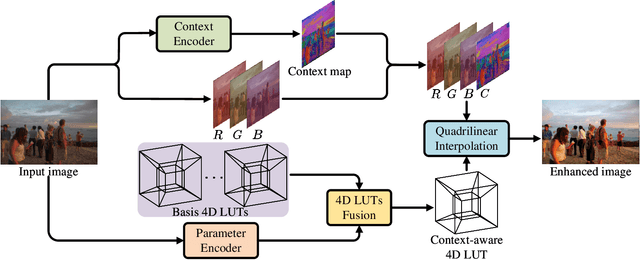


Image enhancement aims at improving the aesthetic visual quality of photos by retouching the color and tone, and is an essential technology for professional digital photography. Recent years deep learning-based image enhancement algorithms have achieved promising performance and attracted increasing popularity. However, typical efforts attempt to construct a uniform enhancer for all pixels' color transformation. It ignores the pixel differences between different content (e.g., sky, ocean, etc.) that are significant for photographs, causing unsatisfactory results. In this paper, we propose a novel learnable context-aware 4-dimensional lookup table (4D LUT), which achieves content-dependent enhancement of different contents in each image via adaptively learning of photo context. In particular, we first introduce a lightweight context encoder and a parameter encoder to learn a context map for the pixel-level category and a group of image-adaptive coefficients, respectively. Then, the context-aware 4D LUT is generated by integrating multiple basis 4D LUTs via the coefficients. Finally, the enhanced image can be obtained by feeding the source image and context map into fused context-aware 4D~LUT via quadrilinear interpolation. Compared with traditional 3D LUT, i.e., RGB mapping to RGB, which is usually used in camera imaging pipeline systems or tools, 4D LUT, i.e., RGBC(RGB+Context) mapping to RGB, enables finer control of color transformations for pixels with different content in each image, even though they have the same RGB values. Experimental results demonstrate that our method outperforms other state-of-the-art methods in widely-used benchmarks.
Language-Guided Face Animation by Recurrent StyleGAN-based Generator
Aug 11, 2022


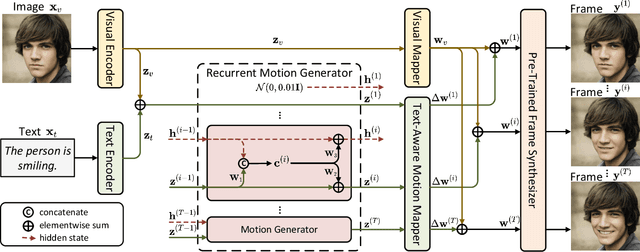
Recent works on language-guided image manipulation have shown great power of language in providing rich semantics, especially for face images. However, the other natural information, motions, in language is less explored. In this paper, we leverage the motion information and study a novel task, language-guided face animation, that aims to animate a static face image with the help of languages. To better utilize both semantics and motions from languages, we propose a simple yet effective framework. Specifically, we propose a recurrent motion generator to extract a series of semantic and motion information from the language and feed it along with visual information to a pre-trained StyleGAN to generate high-quality frames. To optimize the proposed framework, three carefully designed loss functions are proposed including a regularization loss to keep the face identity, a path length regularization loss to ensure motion smoothness, and a contrastive loss to enable video synthesis with various language guidance in one single model. Extensive experiments with both qualitative and quantitative evaluations on diverse domains (\textit{e.g.,} human face, anime face, and dog face) demonstrate the superiority of our model in generating high-quality and realistic videos from one still image with the guidance of language. Code will be available at https://github.com/TiankaiHang/language-guided-animation.git.