 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
Jan 20, 2026Although Mixture-of-Experts (MoE) Large Language Models (LLMs) deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.
Yuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
Yuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024



Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
Dec 04, 2023



In this work, we develop and release Yuan 2.0, a series of large language models with parameters ranging from 2.1 billion to 102.6 billion. The Localized Filtering-based Attention (LFA) is introduced to incorporate prior knowledge of local dependencies of natural language into Attention. A data filtering and generating system is presented to build pre-training and fine-tuning dataset in high quality. A distributed training method with non-uniform pipeline parallel, data parallel, and optimizer parallel is proposed, which greatly reduces the bandwidth requirements of intra-node communication, and achieves good performance in large-scale distributed training. Yuan 2.0 models display impressive ability in code generation, math problem-solving, and chatting compared with existing models. The latest version of YUAN 2.0, including model weights and source code, is accessible at Github.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Oct 12, 2021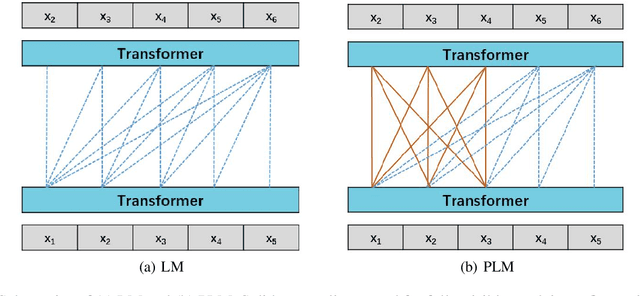

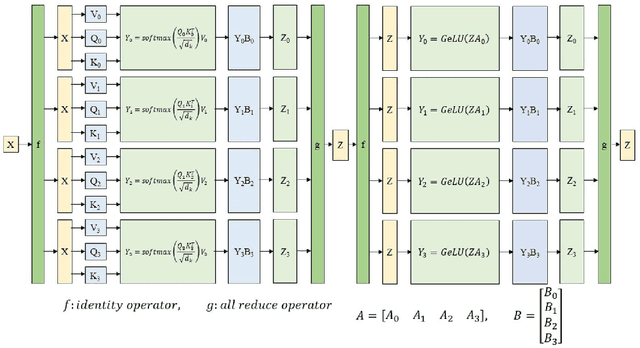

Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. In this work, we propose a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.