 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced generative adversarial network for 3D brain MRI super-resolution
Jul 15, 2019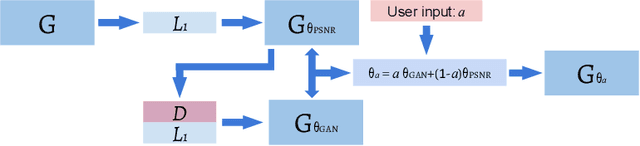
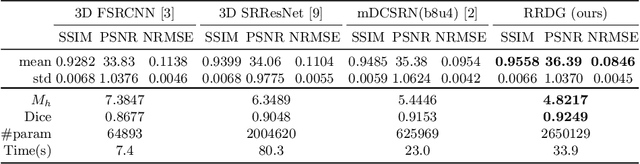
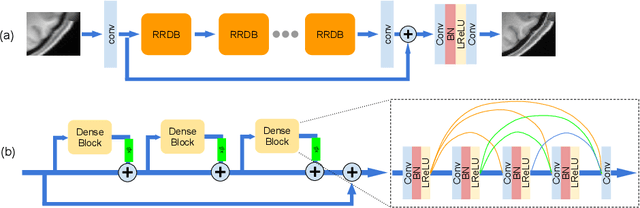

Single image super-resolution (SISR) reconstruction for magnetic resonance imaging (MRI) has generated significant interest because of its potential to not only speed up imaging but to improve quantitative processing and analysis of available image data. Generative Adversarial Networks (GAN) have proven to perform well in recovering image texture detail, and many variants have therefore been proposed for SISR. In this work, we develop an enhancement to tackle GAN-based 3D SISR by introducing a new residual-in-residual dense block (RRDG) generator that is both memory efficient and achieves state-of-the-art performance in terms of PSNR (Peak Signal to Noise Ratio), SSIM (Structural Similarity) and NRMSE (Normalized Root Mean Squared Error) metrics. We also introduce a patch GAN discriminator with improved convergence behavior to better model brain image texture. We proposed a novel the anatomical fidelity evaluation of the results using a pre-trained brain parcellation network. Finally, these developments are combined through a simple and efficient method to balance etween image and texture quality in the final output.
Neural Embedding for Physical Manipulations
Jul 13, 2019

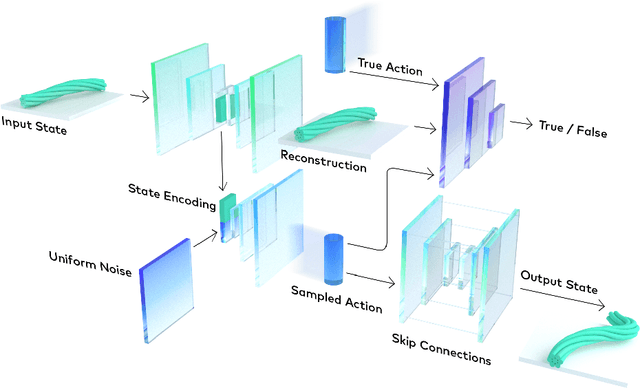

In common real-world robotic operations, action and state spaces can be vast and sometimes unknown, and observations are often relatively sparse. How do we learn the full topology of action and state spaces when given only few and sparse observations? Inspired by the properties of grid cells in mammalian brains, we build a generative model that enforces a normalized pairwise distance constraint between the latent space and output space to achieve data-efficient discovery of output spaces. This method achieves substantially better results than prior generative models, such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs). Prior models have the common issue of mode collapse and thus fail to explore the full topology of output space. We demonstrate the effectiveness of our model on various datasets both qualitatively and quantitatively.
Learning Temporal Pose Estimation from Sparsely-Labeled Videos
Jun 06, 2019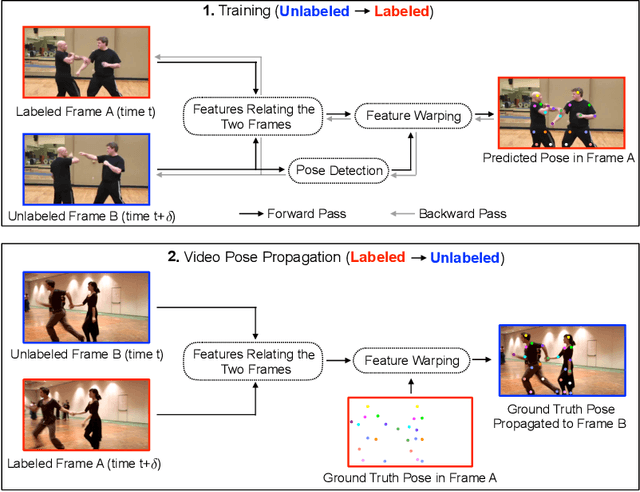

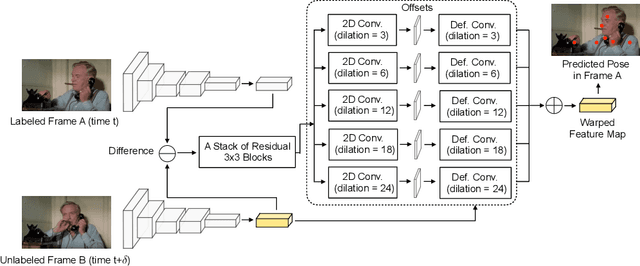
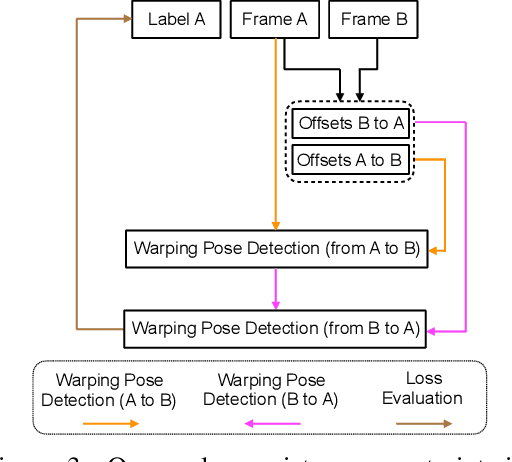
Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 dataset.
Normalized Diversification
Apr 10, 2019
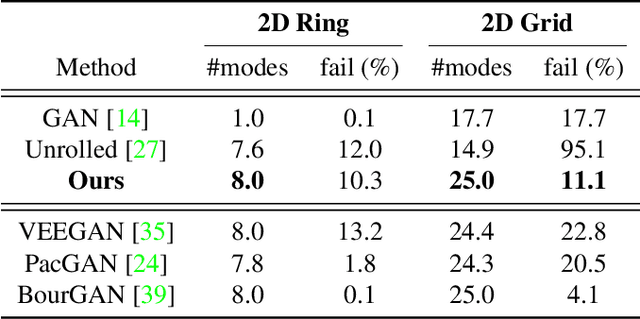
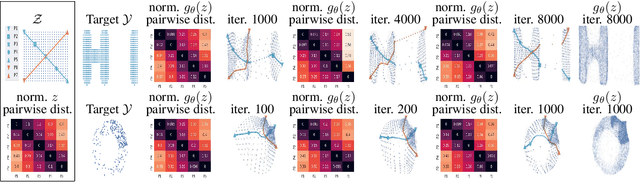
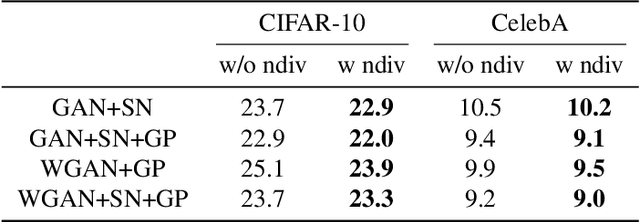
Generating diverse yet specific data is the goal of the generative adversarial network (GAN), but it suffers from the problem of mode collapse. We introduce the concept of normalized diversity which force the model to preserve the normalized pairwise distance between the sparse samples from a latent parametric distribution and their corresponding high-dimensional outputs. The normalized diversification aims to unfold the manifold of unknown topology and non-uniform distribution, which leads to safe interpolation between valid latent variables. By alternating the maximization over the pairwise distance and updating the total distance (normalizer), we encourage the model to actively explore in the high-dimensional output space. We demonstrate that by combining the normalized diversity loss and the adversarial loss, we generate diverse data without suffering from mode collapsing. Experimental results show that our method achieves consistent improvement on unsupervised image generation, conditional image generation and hand pose estimation over strong baselines.
FoveaBox: Beyond Anchor-based Object Detector
Apr 08, 2019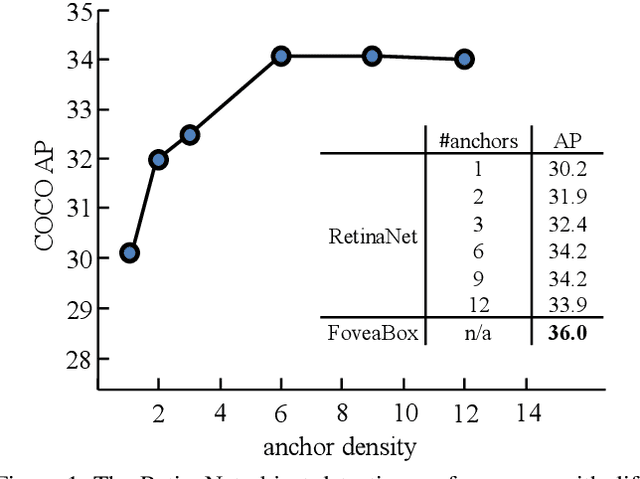

We present FoveaBox, an accurate, flexible and completely anchor-free framework for object detection. While almost all state-of-the-art object detectors utilize the predefined anchors to enumerate possible locations, scales and aspect ratios for the search of the objects, their performance and generalization ability are also limited to the design of anchors. Instead, FoveaBox directly learns the object existing possibility and the bounding box coordinates without anchor reference. This is achieved by: (a) predicting category-sensitive semantic maps for the object existing possibility, and (b) producing category-agnostic bounding box for each position that potentially contains an object. The scales of target boxes are naturally associated with feature pyramid representations for each input image. Without bells and whistles, FoveaBox achieves state-of-the-art single model performance of 42.1 AP on the standard COCO detection benchmark. Specially for the objects with arbitrary aspect ratios, FoveaBox brings in significant improvement compared to the anchor-based detectors. More surprisingly, when it is challenged by the stretched testing images, FoveaBox shows great robustness and generalization ability to the changed distribution of bounding box shapes. The code will be made publicly available.
Trajectory Normalized Gradients for Distributed Optimization
Jan 24, 2019

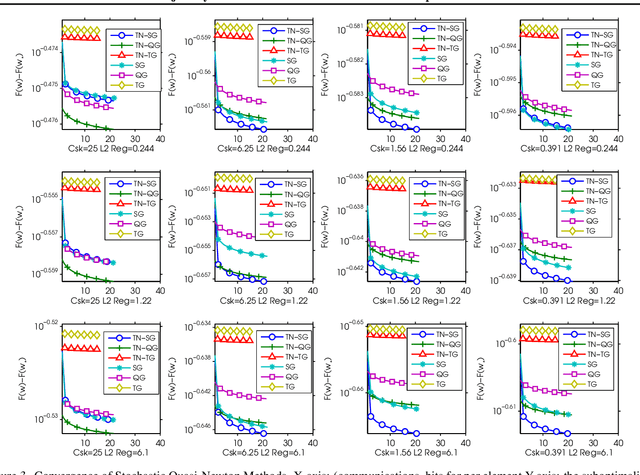

Recently, researchers proposed various low-precision gradient compression, for efficient communication in large-scale distributed optimization. Based on these work, we try to reduce the communication complexity from a new direction. We pursue an ideal bijective mapping between two spaces of gradient distribution, so that the mapped gradient carries greater information entropy after the compression. In our setting, all servers should share a reference gradient in advance, and they communicate via the normalized gradients, which are the subtraction or quotient, between current gradients and the reference. To obtain a reference vector that yields a stronger signal-to-noise ratio, dynamically in each iteration, we extract and fuse information from the past trajectory in hindsight, and search for an optimal reference for compression. We name this to be the trajectory-based normalized gradients (TNG). It bridges the research from different societies, like coding, optimization, systems, and learning. It is easy to implement and can universally combine with existing algorithms. Our experiments on benchmarking hard non-convex functions, convex problems like logistic regression demonstrate that TNG is more compression-efficient for communication of distributed optimization of general functions.
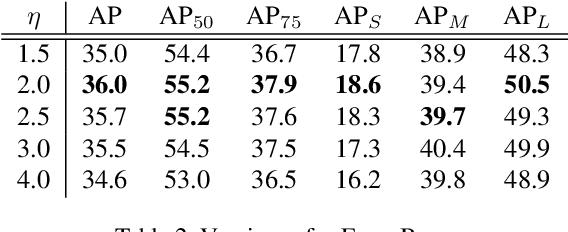
Consistent Optimization for Single-Shot Object Detection
Jan 23, 2019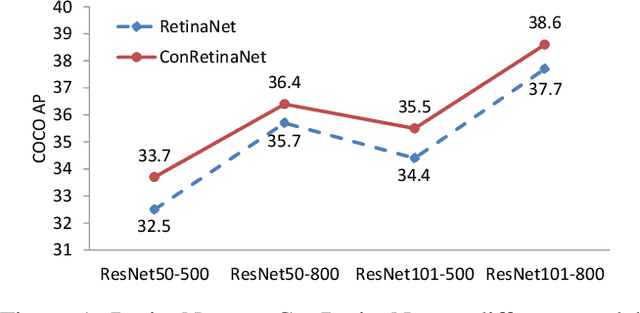
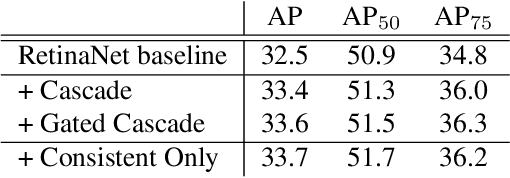


We present consistent optimization for single stage object detection. Previous works of single stage object detectors usually rely on the regular, dense sampled anchors to generate hypothesis for the optimization of the model. Through an examination of the behavior of the detector, we observe that the misalignment between the optimization target and inference configurations has hindered the performance improvement. We propose to bride this gap by consistent optimization, which is an extension of the traditional single stage detector's optimization strategy. Consistent optimization focuses on matching the training hypotheses and the inference quality by utilizing of the refined anchors during training. To evaluate its effectiveness, we conduct various design choices based on the state-of-the-art RetinaNet detector. We demonstrate it is the consistent optimization, not the architecture design, that yields the performance boosts. Consistent optimization is nearly cost-free, and achieves stable performance gains independent of the model capacities or input scales. Specifically, utilizing consistent optimization improves RetinaNet from 39.1 AP to 40.1 AP on COCO dataset without any bells or whistles, which surpasses the accuracy of all existing state-of-the-art one-stage detectors when adopting ResNet-101 as backbone. The code will be made available.
Monocular 3D Pose Recovery via Nonconvex Sparsity with Theoretical Analysis
Dec 29, 2018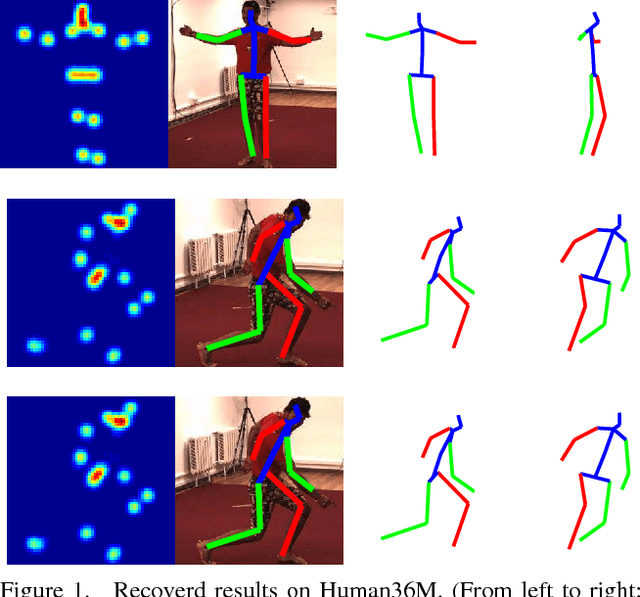

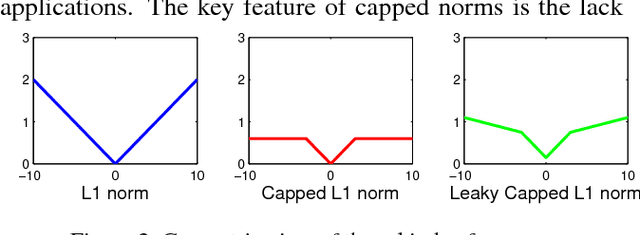

For recovering 3D object poses from 2D images, a prevalent method is to pre-train an over-complete dictionary $\mathcal D=\{B_i\}_i^D$ of 3D basis poses. During testing, the detected 2D pose $Y$ is matched to dictionary by $Y \approx \sum_i M_i B_i$ where $\{M_i\}_i^D=\{c_i \Pi R_i\}$, by estimating the rotation $R_i$, projection $\Pi$ and sparse combination coefficients $c \in \mathbb R_{+}^D$. In this paper, we propose non-convex regularization $H(c)$ to learn coefficients $c$, including novel leaky capped $\ell_1$-norm regularization (LCNR), \begin{align*} H(c)=\alpha \sum_{i } \min(|c_i|,\tau)+ \beta \sum_{i } \max(| c_i|,\tau), \end{align*} where $0\leq \beta \leq \alpha$ and $0<\tau$ is a certain threshold, so the invalid components smaller than $\tau$ are composed with larger regularization and other valid components with smaller regularization. We propose a multi-stage optimizer with convex relaxation and ADMM. We prove that the estimation error $\mathcal L(l)$ decays w.r.t. the stages $l$, \begin{align*} Pr\left(\mathcal L(l) < \rho^{l-1} \mathcal L(0) + \delta \right) \geq 1- \epsilon, \end{align*} where $0< \rho <1, 0<\delta, 0<\epsilon \ll 1$. Experiments on large 3D human datasets like H36M are conducted to support our improvement upon previous approaches. To the best of our knowledge, this is the first theoretical analysis in this line of research, to understand how the recovery error is affected by fundamental factors, e.g. dictionary size, observation noises, optimization times. We characterize the trade-off between speed and accuracy towards real-time inference in applications.
Learning Discriminative Motion Features Through Detection
Dec 11, 2018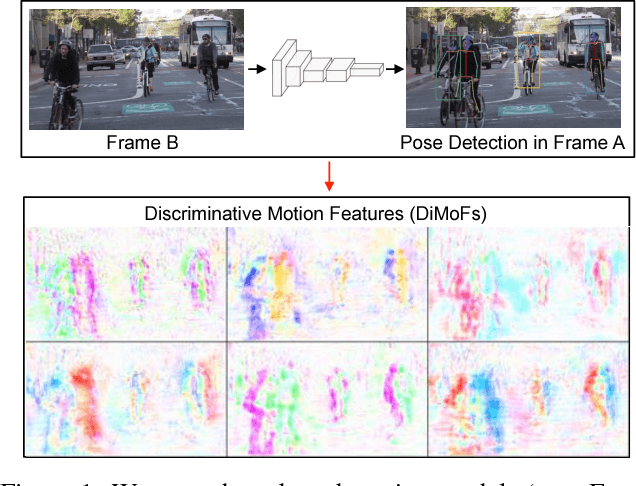

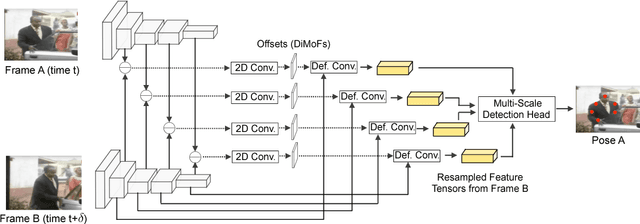

Despite huge success in the image domain, modern detection models such as Faster R-CNN have not been used nearly as much for video analysis. This is arguably due to the fact that detection models are designed to operate on single frames and as a result do not have a mechanism for learning motion representations directly from video. We propose a learning procedure that allows detection models such as Faster R-CNN to learn motion features directly from the RGB video data while being optimized with respect to a pose estimation task. Given a pair of video frames---Frame A and Frame B---we force our model to predict human pose in Frame A using the features from Frame B. We do so by leveraging deformable convolutions across space and time. Our network learns to spatially sample features from Frame B in order to maximize pose detection accuracy in Frame A. This naturally encourages our network to learn motion offsets encoding the spatial correspondences between the two frames. We refer to these motion offsets as DiMoFs (Discriminative Motion Features). In our experiments we show that our training scheme helps learn effective motion cues, which can be used to estimate and localize salient human motion. Furthermore, we demonstrate that as a byproduct, our model also learns features that lead to improved pose detection in still-images, and better keypoint tracking. Finally, we show how to leverage our learned model for the tasks of spatiotemporal action localization and fine-grained action recognition.
Zoom-In-to-Check: Boosting Video Interpolation via Instance-level Discrimination
Dec 04, 2018
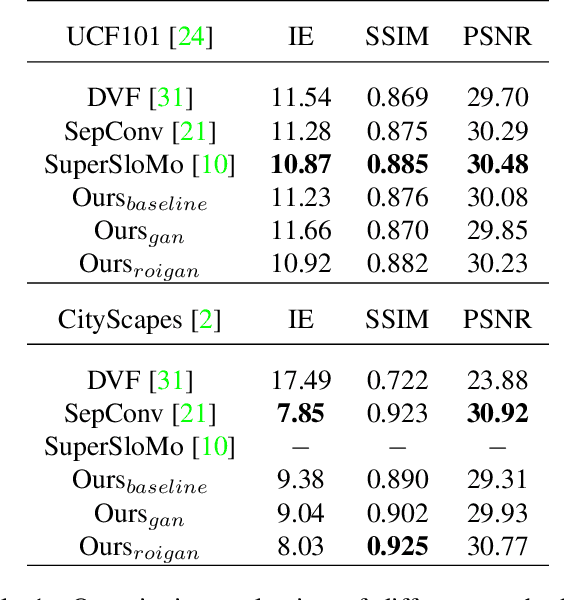
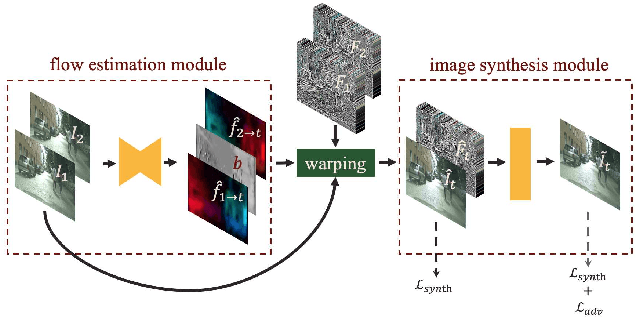
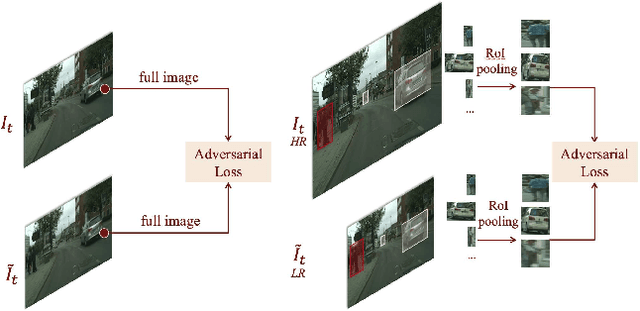
We propose a light-weight video frame interpolation algorithm. Our key innovation is an instance-level supervision that allows information to be learned from the high-resolution version of similar objects. Our experiment shows that the proposed method can generate state-of-art results across different datasets, with fractional computation resources (time and memory) with competing methods. Given two image frames, a cascade network creates an intermediate frame with 1) a flow-warping module that computes large bi-directional optical flow and creates an interpolated image via flow-based warping, followed by 2) an image synthesis module to make fine-scale corrections. In the learning stage, object detection proposals are generated on the interpolated image. Lower resolution objects are zoomed into, and the learning algorithms using an adversarial loss trained on high-resolution objects to guide the system towards the instance-level refinement corrects details of object shape and boundaries. As all our proposed network modules are fully convolutional, our proposed system can be trained end-to-end.