 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLUX-Makeup: High-Fidelity, Identity-Consistent, and Robust Makeup Transfer via Diffusion Transformer
Aug 07, 2025



Makeup transfer aims to apply the makeup style from a reference face to a target face and has been increasingly adopted in practical applications. Existing GAN-based approaches typically rely on carefully designed loss functions to balance transfer quality and facial identity consistency, while diffusion-based methods often depend on additional face-control modules or algorithms to preserve identity. However, these auxiliary components tend to introduce extra errors, leading to suboptimal transfer results. To overcome these limitations, we propose FLUX-Makeup, a high-fidelity, identity-consistent, and robust makeup transfer framework that eliminates the need for any auxiliary face-control components. Instead, our method directly leverages source-reference image pairs to achieve superior transfer performance. Specifically, we build our framework upon FLUX-Kontext, using the source image as its native conditional input. Furthermore, we introduce RefLoRAInjector, a lightweight makeup feature injector that decouples the reference pathway from the backbone, enabling efficient and comprehensive extraction of makeup-related information. In parallel, we design a robust and scalable data generation pipeline to provide more accurate supervision during training. The paired makeup datasets produced by this pipeline significantly surpass the quality of all existing datasets. Extensive experiments demonstrate that FLUX-Makeup achieves state-of-the-art performance, exhibiting strong robustness across diverse scenarios.
ZIPA: A family of efficient models for multilingual phone recognition
May 29, 2025We present ZIPA, a family of efficient speech models that advances the state-of-the-art performance of crosslinguistic phone recognition. We first curated IPAPack++, a large-scale multilingual speech corpus with 17,132 hours of normalized phone transcriptions and a novel evaluation set capturing unseen languages and sociophonetic variation. With the large-scale training data, ZIPA, including transducer (ZIPA-T) and CTC-based (ZIPA-CR) variants, leverage the efficient Zipformer backbones and outperform existing phone recognition systems with much fewer parameters. Further scaling via noisy student training on 11,000 hours of pseudo-labeled multilingual data yields further improvement. While ZIPA achieves strong performance on benchmarks, error analysis reveals persistent limitations in modeling sociophonetic diversity, underscoring challenges for future research.
CaseReportBench: An LLM Benchmark Dataset for Dense Information Extraction in Clinical Case Reports
May 22, 2025Rare diseases, including Inborn Errors of Metabolism (IEM), pose significant diagnostic challenges. Case reports serve as key but computationally underutilized resources to inform diagnosis. Clinical dense information extraction refers to organizing medical information into structured predefined categories. Large Language Models (LLMs) may enable scalable information extraction from case reports but are rarely evaluated for this task. We introduce CaseReportBench, an expert-annotated dataset for dense information extraction of case reports, focusing on IEMs. Using this dataset, we assess various models and prompting strategies, introducing novel approaches such as category-specific prompting and subheading-filtered data integration. Zero-shot chain-of-thought prompting offers little advantage over standard zero-shot prompting. Category-specific prompting improves alignment with the benchmark. The open-source model Qwen2.5-7B outperforms GPT-4o for this task. Our clinician evaluations show that LLMs can extract clinically relevant details from case reports, supporting rare disease diagnosis and management. We also highlight areas for improvement, such as LLMs' limitations in recognizing negative findings important for differential diagnosis. This work advances LLM-driven clinical natural language processing and paves the way for scalable medical AI applications.
Self-Learning Hyperspectral and Multispectral Image Fusion via Adaptive Residual Guided Subspace Diffusion Model
May 17, 2025Hyperspectral and multispectral image (HSI-MSI) fusion involves combining a low-resolution hyperspectral image (LR-HSI) with a high-resolution multispectral image (HR-MSI) to generate a high-resolution hyperspectral image (HR-HSI). Most deep learning-based methods for HSI-MSI fusion rely on large amounts of hyperspectral data for supervised training, which is often scarce in practical applications. In this paper, we propose a self-learning Adaptive Residual Guided Subspace Diffusion Model (ARGS-Diff), which only utilizes the observed images without any extra training data. Specifically, as the LR-HSI contains spectral information and the HR-MSI contains spatial information, we design two lightweight spectral and spatial diffusion models to separately learn the spectral and spatial distributions from them. Then, we use these two models to reconstruct HR-HSI from two low-dimensional components, i.e, the spectral basis and the reduced coefficient, during the reverse diffusion process. Furthermore, we introduce an Adaptive Residual Guided Module (ARGM), which refines the two components through a residual guided function at each sampling step, thereby stabilizing the sampling process. Extensive experimental results demonstrate that ARGS-Diff outperforms existing state-of-the-art methods in terms of both performance and computational efficiency in the field of HSI-MSI fusion. Code is available at https://github.com/Zhu1116/ARGS-Diff.
Other Vehicle Trajectories Are Also Needed: A Driving World Model Unifies Ego-Other Vehicle Trajectories in Video Latant Space
Mar 12, 2025Advanced end-to-end autonomous driving systems predict other vehicles' motions and plan ego vehicle's trajectory. The world model that can foresee the outcome of the trajectory has been used to evaluate the end-to-end autonomous driving system. However, existing world models predominantly emphasize the trajectory of the ego vehicle and leave other vehicles uncontrollable. This limitation hinders their ability to realistically simulate the interaction between the ego vehicle and the driving scenario. In addition, it remains a challenge to match multiple trajectories with each vehicle in the video to control the video generation. To address above issues, a driving \textbf{W}orld \textbf{M}odel named EOT-WM is proposed in this paper, unifying \textbf{E}go-\textbf{O}ther vehicle \textbf{T}rajectories in videos. Specifically, we first project ego and other vehicle trajectories in the BEV space into the image coordinate to match each trajectory with its corresponding vehicle in the video. Then, trajectory videos are encoded by the Spatial-Temporal Variational Auto Encoder to align with driving video latents spatially and temporally in the unified visual space. A trajectory-injected diffusion Transformer is further designed to denoise the noisy video latents for video generation with the guidance of ego-other vehicle trajectories. In addition, we propose a metric based on control latent similarity to evaluate the controllability of trajectories. Extensive experiments are conducted on the nuScenes dataset, and the proposed model outperforms the state-of-the-art method by 30\% in FID and 55\% in FVD. The model can also predict unseen driving scenes with self-produced trajectories.
Neurobiber: Fast and Interpretable Stylistic Feature Extraction
Feb 25, 2025



Linguistic style is pivotal for understanding how texts convey meaning and fulfill communicative purposes, yet extracting detailed stylistic features at scale remains challenging. We present Neurobiber, a transformer-based system for fast, interpretable style profiling built on Biber's Multidimensional Analysis (MDA). Neurobiber predicts 96 Biber-style features from our open-source BiberPlus library (a Python toolkit that computes stylistic features and provides integrated analytics, e.g., PCA and factor analysis). Despite being up to 56 times faster than existing open source systems, Neurobiber replicates classic MDA insights on the CORE corpus and achieves competitive performance on the PAN 2020 authorship verification task without extensive retraining. Its efficient and interpretable representations readily integrate into downstream NLP pipelines, facilitating large-scale stylometric research, forensic analysis, and real-time text monitoring. All components are made publicly available.
Developing multilingual speech synthesis system for Ojibwe, Mi'kmaq, and Maliseet
Feb 04, 2025


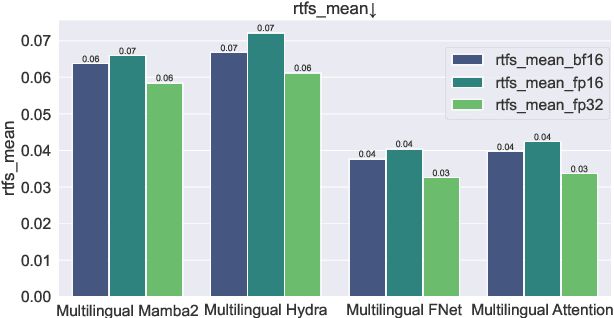
We present lightweight flow matching multilingual text-to-speech (TTS) systems for Ojibwe, Mi'kmaq, and Maliseet, three Indigenous languages in North America. Our results show that training a multilingual TTS model on three typologically similar languages can improve the performance over monolingual models, especially when data are scarce. Attention-free architectures are highly competitive with self-attention architecture with higher memory efficiency. Our research not only advances technical development for the revitalization of low-resource languages but also highlights the cultural gap in human evaluation protocols, calling for a more community-centered approach to human evaluation.
Trusted Mamba Contrastive Network for Multi-View Clustering
Dec 21, 2024



Multi-view clustering can partition data samples into their categories by learning a consensus representation in an unsupervised way and has received more and more attention in recent years. However, there is an untrusted fusion problem. The reasons for this problem are as follows: 1) The current methods ignore the presence of noise or redundant information in the view; 2) The similarity of contrastive learning comes from the same sample rather than the same cluster in deep multi-view clustering. It causes multi-view fusion in the wrong direction. This paper proposes a novel multi-view clustering network to address this problem, termed as Trusted Mamba Contrastive Network (TMCN). Specifically, we present a new Trusted Mamba Fusion Network (TMFN), which achieves a trusted fusion of multi-view data through a selective mechanism. Moreover, we align the fused representation and the view-specific representation using the Average-similarity Contrastive Learning (AsCL) module. AsCL increases the similarity of view presentation from the same cluster, not merely from the same sample. Extensive experiments show that the proposed method achieves state-of-the-art results in deep multi-view clustering tasks.
CLIP Multi-modal Hashing for Multimedia Retrieval
Oct 10, 2024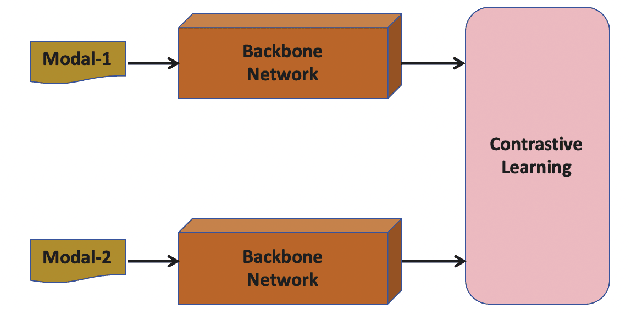

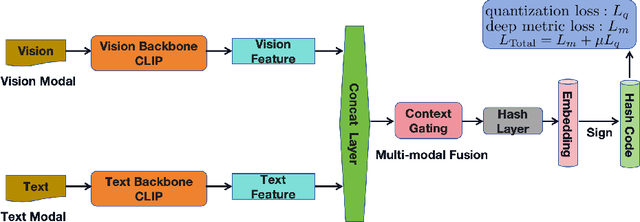
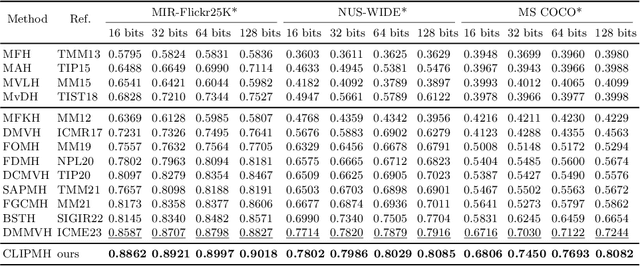
Multi-modal hashing methods are widely used in multimedia retrieval, which can fuse multi-source data to generate binary hash code. However, the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data, resulting in low retrieval accuracy. To address this issue, we propose a novel CLIP Multi-modal Hashing (CLIPMH) method. Our method employs the CLIP framework to extract both text and vision features and then fuses them to generate hash code. Due to enhancement on each modal feature, our method has great improvement in the retrieval performance of multi-modal hashing methods. Compared with state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly improve performance (a maximum increase of 8.38% in mAP).
Efficiently Identifying Low-Quality Language Subsets in Multilingual Datasets: A Case Study on a Large-Scale Multilingual Audio Dataset
Oct 05, 2024



Curating datasets that span multiple languages is challenging. To make the collection more scalable, researchers often incorporate one or more imperfect classifiers in the process, like language identification models. These models, however, are prone to failure, resulting in some language subsets being unreliable for downstream tasks. We introduce a statistical test, the Preference Proportion Test, for identifying such unreliable subsets. By annotating only 20 samples for a language subset, we're able to identify systematic transcription errors for 10 language subsets in a recent large multilingual transcribed audio dataset, X-IPAPack (Zhu et al., 2024). We find that filtering this low-quality data out when training models for the downstream task of phonetic transcription brings substantial benefits, most notably a 25.7% relative improvement on transcribing recordings in out-of-distribution languages. Our method lays a path forward for systematic and reliable multilingual dataset auditing.