 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models for Policy Refinement in StarCraft II
Feb 16, 2026Large Language Models (LLMs) have recently shown strong reasoning and generalization capabilities, motivating their use as decision-making policies in complex environments. StarCraft II (SC2), with its massive state-action space and partial observability, is a challenging testbed. However, existing LLM-based SC2 agents primarily focus on improving the policy itself and overlook integrating a learnable, action-conditioned transition model into the decision loop. To bridge this gap, we propose StarWM, the first world model for SC2 that predicts future observations under partial observability. To facilitate learning SC2's hybrid dynamics, we introduce a structured textual representation that factorizes observations into five semantic modules, and construct SC2-Dynamics-50k, the first instruction-tuning dataset for SC2 dynamics prediction. We further develop a multi-dimensional offline evaluation framework for predicted structured observations. Offline results show StarWM's substantial gains over zero-shot baselines, including nearly 60% improvements in resource prediction accuracy and self-side macro-situation consistency. Finally, we propose StarWM-Agent, a world-model-augmented decision system that integrates StarWM into a Generate--Simulate--Refine decision loop for foresight-driven policy refinement. Online evaluation against SC2's built-in AI demonstrates consistent improvements, yielding win-rate gains of 30%, 15%, and 30% against Hard (LV5), Harder (LV6), and VeryHard (LV7), respectively, alongside improved macro-management stability and tactical risk assessment.
CLIP Multi-modal Hashing for Multimedia Retrieval
Oct 10, 2024

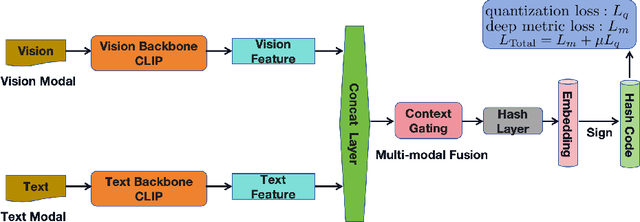
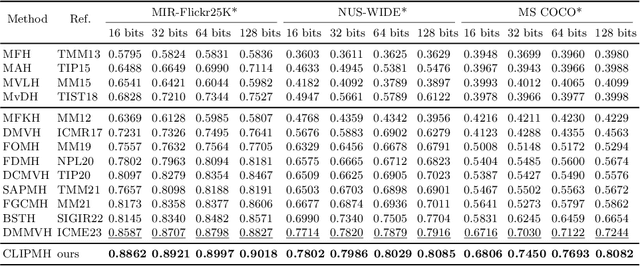
Multi-modal hashing methods are widely used in multimedia retrieval, which can fuse multi-source data to generate binary hash code. However, the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data, resulting in low retrieval accuracy. To address this issue, we propose a novel CLIP Multi-modal Hashing (CLIPMH) method. Our method employs the CLIP framework to extract both text and vision features and then fuses them to generate hash code. Due to enhancement on each modal feature, our method has great improvement in the retrieval performance of multi-modal hashing methods. Compared with state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly improve performance (a maximum increase of 8.38% in mAP).