 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJParc: Joint cortical surface parcellation with registration
Dec 27, 2025Cortical surface parcellation is a fundamental task in both basic neuroscience research and clinical applications, enabling more accurate mapping of brain regions. Model-based and learning-based approaches for automated parcellation alleviate the need for manual labeling. Despite the advancement in parcellation performance, learning-based methods shift away from registration and atlas propagation without exploring the reason for the improvement compared to traditional methods. In this study, we present JParc, a joint cortical registration and parcellation framework, that outperforms existing state-of-the-art parcellation methods. In rigorous experiments, we demonstrate that the enhanced performance of JParc is primarily attributable to accurate cortical registration and a learned parcellation atlas. By leveraging a shallow subnetwork to fine-tune the propagated atlas labels, JParc achieves a Dice score greater than 90% on the Mindboggle dataset, using only basic geometric features (sulcal depth, curvature) that describe cortical folding patterns. The superior accuracy of JParc can significantly increase the statistical power in brain mapping studies as well as support applications in surgical planning and many other downstream neuroscientific and clinical tasks.
HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
Dec 17, 20253D Scene Graphs (3DSGs) constitute a powerful representation of the physical world, distinguished by their abilities to explicitly model the complex spatial, semantic, and functional relationships between entities, rendering a foundational understanding that enables agents to interact intelligently with their environment and execute versatile behaviors. Embodied navigation, as a crucial component of such capabilities, leverages the compact and expressive nature of 3DSGs to enable long-horizon reasoning and planning in complex, large-scale environments. However, prior works rely on a static-world assumption, defining traversable space solely based on static spatial layouts and thereby treating interactable obstacles as non-traversable. This fundamental limitation severely undermines their effectiveness in real-world scenarios, leading to limited reachability, low efficiency, and inferior extensibility. To address these issues, we propose HERO, a novel framework for constructing Hierarchical Traversable 3DSGs, that redefines traversability by modeling operable obstacles as pathways, capturing their physical interactivity, functional semantics, and the scene's relational hierarchy. The results show that, relative to its baseline, HERO reduces PL by 35.1% in partially obstructed environments and increases SR by 79.4% in fully obstructed ones, demonstrating substantially higher efficiency and reachability.
TAO-Net: Two-stage Adaptive OOD Classification Network for Fine-grained Encrypted Traffic Classification
Dec 11, 2025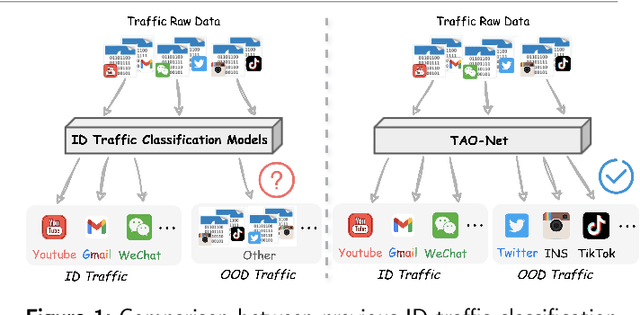

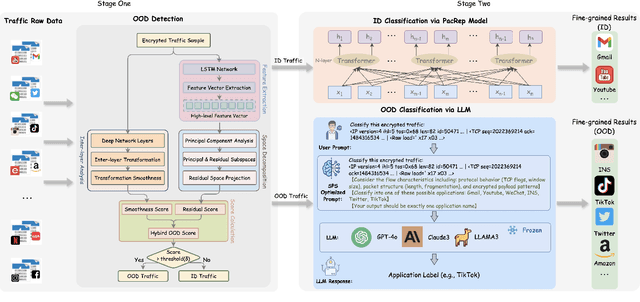
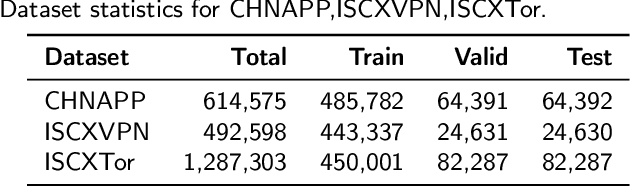
Encrypted traffic classification aims to identify applications or services by analyzing network traffic data. One of the critical challenges is the continuous emergence of new applications, which generates Out-of-Distribution (OOD) traffic patterns that deviate from known categories and are not well represented by predefined models. Current approaches rely on predefined categories, which limits their effectiveness in handling unknown traffic types. Although some methods mitigate this limitation by simply classifying unknown traffic into a single "Other" category, they fail to make a fine-grained classification. In this paper, we propose a Two-stage Adaptive OOD classification Network (TAO-Net) that achieves accurate classification for both In-Distribution (ID) and OOD encrypted traffic. The method incorporates an innovative two-stage design: the first stage employs a hybrid OOD detection mechanism that integrates transformer-based inter-layer transformation smoothness and feature analysis to effectively distinguish between ID and OOD traffic, while the second stage leverages large language models with a novel semantic-enhanced prompt strategy to transform OOD traffic classification into a generation task, enabling flexible fine-grained classification without relying on predefined labels. Experiments on three datasets demonstrate that TAO-Net achieves 96.81-97.70% macro-precision and 96.77-97.68% macro-F1, outperforming previous methods that only reach 44.73-86.30% macro-precision, particularly in identifying emerging network applications.
RoleRMBench & RoleRM: Towards Reward Modeling for Profile-Based Role Play in Dialogue Systems
Dec 11, 2025Reward modeling has become a cornerstone of aligning large language models (LLMs) with human preferences. Yet, when extended to subjective and open-ended domains such as role play, existing reward models exhibit severe degradation, struggling to capture nuanced and persona-grounded human judgments. To address this gap, we introduce RoleRMBench, the first systematic benchmark for reward modeling in role-playing dialogue, covering seven fine-grained capabilities from narrative management to role consistency and engagement. Evaluation on RoleRMBench reveals large and consistent gaps between general-purpose reward models and human judgment, particularly in narrative and stylistic dimensions. We further propose RoleRM, a reward model trained with Continuous Implicit Preferences (CIP), which reformulates subjective evaluation as continuous consistent pairwise supervision under multiple structuring strategies. Comprehensive experiments show that RoleRM surpasses strong open- and closed-source reward models by over 24% on average, demonstrating substantial gains in narrative coherence and stylistic fidelity. Our findings highlight the importance of continuous preference representation and annotation consistency, establishing a foundation for subjective alignment in human-centered dialogue systems.
SMART: Shot-Aware Multimodal Video Moment Retrieval with Audio-Enhanced MLLM
Nov 18, 2025Video Moment Retrieval is a task in video understanding that aims to localize a specific temporal segment in an untrimmed video based on a natural language query. Despite recent progress in moment retrieval from videos using both traditional techniques and Multimodal Large Language Models (MLLM), most existing methods still rely on coarse temporal understanding and a single visual modality, limiting performance on complex videos. To address this, we introduce \textit{S}hot-aware \textit{M}ultimodal \textit{A}udio-enhanced \textit{R}etrieval of \textit{T}emporal \textit{S}egments (SMART), an MLLM-based framework that integrates audio cues and leverages shot-level temporal structure. SMART enriches multimodal representations by combining audio and visual features while applying \textbf{Shot-aware Token Compression}, which selectively retains high-information tokens within each shot to reduce redundancy and preserve fine-grained temporal details. We also refine prompt design to better utilize audio-visual cues. Evaluations on Charades-STA and QVHighlights show that SMART achieves significant improvements over state-of-the-art methods, including a 1.61\% increase in R1@0.5 and 2.59\% gain in R1@0.7 on Charades-STA.
RadarMP: Motion Perception for 4D mmWave Radar in Autonomous Driving
Nov 15, 2025



Accurate 3D scene motion perception significantly enhances the safety and reliability of an autonomous driving system. Benefiting from its all-weather operational capability and unique perceptual properties, 4D mmWave radar has emerged as an essential component in advanced autonomous driving. However, sparse and noisy radar points often lead to imprecise motion perception, leaving autonomous vehicles with limited sensing capabilities when optical sensors degrade under adverse weather conditions. In this paper, we propose RadarMP, a novel method for precise 3D scene motion perception using low-level radar echo signals from two consecutive frames. Unlike existing methods that separate radar target detection and motion estimation, RadarMP jointly models both tasks in a unified architecture, enabling consistent radar point cloud generation and pointwise 3D scene flow prediction. Tailored to radar characteristics, we design specialized self-supervised loss functions guided by Doppler shifts and echo intensity, effectively supervising spatial and motion consistency without explicit annotations. Extensive experiments on the public dataset demonstrate that RadarMP achieves reliable motion perception across diverse weather and illumination conditions, outperforming radar-based decoupled motion perception pipelines and enhancing perception capabilities for full-scenario autonomous driving systems.
When Bias Pretends to Be Truth: How Spurious Correlations Undermine Hallucination Detection in LLMs
Nov 10, 2025Despite substantial advances, large language models (LLMs) continue to exhibit hallucinations, generating plausible yet incorrect responses. In this paper, we highlight a critical yet previously underexplored class of hallucinations driven by spurious correlations -- superficial but statistically prominent associations between features (e.g., surnames) and attributes (e.g., nationality) present in the training data. We demonstrate that these spurious correlations induce hallucinations that are confidently generated, immune to model scaling, evade current detection methods, and persist even after refusal fine-tuning. Through systematically controlled synthetic experiments and empirical evaluations on state-of-the-art open-source and proprietary LLMs (including GPT-5), we show that existing hallucination detection methods, such as confidence-based filtering and inner-state probing, fundamentally fail in the presence of spurious correlations. Our theoretical analysis further elucidates why these statistical biases intrinsically undermine confidence-based detection techniques. Our findings thus emphasize the urgent need for new approaches explicitly designed to address hallucinations caused by spurious correlations.
Gentle Manipulation Policy Learning via Demonstrations from VLM Planned Atomic Skills
Nov 08, 2025Autonomous execution of long-horizon, contact-rich manipulation tasks traditionally requires extensive real-world data and expert engineering, posing significant cost and scalability challenges. This paper proposes a novel framework integrating hierarchical semantic decomposition, reinforcement learning (RL), visual language models (VLMs), and knowledge distillation to overcome these limitations. Complex tasks are decomposed into atomic skills, with RL-trained policies for each primitive exclusively in simulation. Crucially, our RL formulation incorporates explicit force constraints to prevent object damage during delicate interactions. VLMs perform high-level task decomposition and skill planning, generating diverse expert demonstrations. These are distilled into a unified policy via Visual-Tactile Diffusion Policy for end-to-end execution. We conduct comprehensive ablation studies exploring different VLM-based task planners to identify optimal demonstration generation pipelines, and systematically compare imitation learning algorithms for skill distillation. Extensive simulation experiments and physical deployment validate that our approach achieves policy learning for long-horizon manipulation without costly human demonstrations, while the VLM-guided atomic skill framework enables scalable generalization to diverse tasks.
Correlation and Temporal Consistency Analysis of Mono-static and Bi-static ISAC Channels
Nov 05, 2025Integrated Sensing and Communication (ISAC) is critical for efficient spectrum and hardware utilization in future wireless networks like 6G. However, existing channel models lack comprehensive characterization of ISAC-specific dynamics, particularly the relationship between mono-static (co-located Tx/Rx) and bi-static (separated Tx/Rx) sensing configurations. Empirical measurements in dynamic urban microcell (UMi) environments using a 79-GHz FMCW channel sounder help bridge this gap. Two key findings are demonstrated: (1) mono-static and bi-static channels exhibit consistently low instantaneous correlation due to divergent propagation geometries; (2) despite low instantaneous correlation, both channels share unified temporal consistency, evolving predictably under environmental kinematics. These insights, validated across seven real-world scenarios with moving targets/transceivers, inform robust ISAC system design and future standardization.
M^3Detection: Multi-Frame Multi-Level Feature Fusion for Multi-Modal 3D Object Detection with Camera and 4D Imaging Radar
Oct 31, 2025Recent advances in 4D imaging radar have enabled robust perception in adverse weather, while camera sensors provide dense semantic information. Fusing the these complementary modalities has great potential for cost-effective 3D perception. However, most existing camera-radar fusion methods are limited to single-frame inputs, capturing only a partial view of the scene. The incomplete scene information, compounded by image degradation and 4D radar sparsity, hinders overall detection performance. In contrast, multi-frame fusion offers richer spatiotemporal information but faces two challenges: achieving robust and effective object feature fusion across frames and modalities, and mitigating the computational cost of redundant feature extraction. Consequently, we propose M^3Detection, a unified multi-frame 3D object detection framework that performs multi-level feature fusion on multi-modal data from camera and 4D imaging radar. Our framework leverages intermediate features from the baseline detector and employs the tracker to produce reference trajectories, improving computational efficiency and providing richer information for second-stage. In the second stage, we design a global-level inter-object feature aggregation module guided by radar information to align global features across candidate proposals and a local-level inter-grid feature aggregation module that expands local features along the reference trajectories to enhance fine-grained object representation. The aggregated features are then processed by a trajectory-level multi-frame spatiotemporal reasoning module to encode cross-frame interactions and enhance temporal representation. Extensive experiments on the VoD and TJ4DRadSet datasets demonstrate that M^3Detection achieves state-of-the-art 3D detection performance, validating its effectiveness in multi-frame detection with camera-4D imaging radar fusion.