 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJian Hu
RIIT: Rethinking the Importance of Implementation Tricks in Multi-Agent Reinforcement Learning
Mar 01, 2021
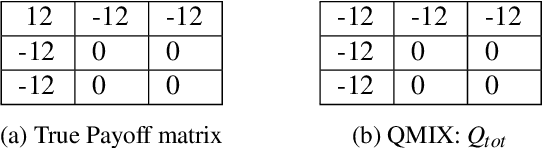


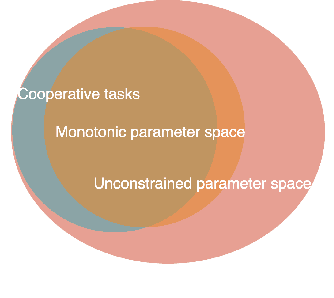
In recent years, Multi-Agent Deep Reinforcement Learning (MADRL) has been successfully applied to various complex scenarios such as computer games and robot swarms. We investigate the impact of "implementation tricks" of state-of-the-art (SOTA) QMIX-based algorithms. Firstly, we find that such tricks, described as auxiliary details to the core algorithm, seemingly of secondary importance, have a major impact. Our finding demonstrates that, after minimal tuning, QMIX attains extraordinarily high win rates and achieves SOTA in the StarCraft Multi-Agent Challenge (SMAC). Furthermore, we find QMIX's monotonicity condition helps improve sample efficiency in some cooperative tasks, and we propose a new policy-based algorithm, called: RIIT, to prove the importance of the monotonicity condition. RIIT also achieves SOTA in policy-based algorithms. At last, we propose a hypothesis to explain the monotonicity condition. We open-sourced the code at \url{https://github.com/hijkzzz/pymarl2}.
QR-MIX: Distributional Value Function Factorisation for Cooperative Multi-Agent Reinforcement Learning
Sep 28, 2020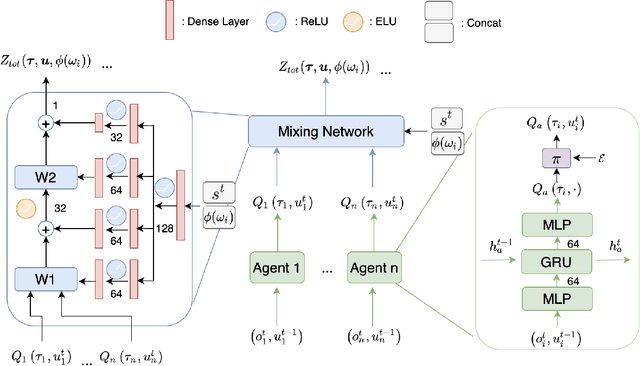
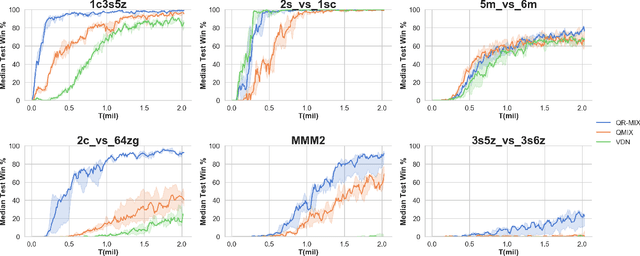
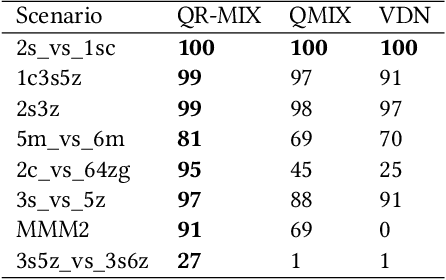

In Cooperative Multi-Agent Reinforcement Learning (MARL) and under the setting of Centralized Training with Decentralized Execution (CTDE), agents observe and interact with their environment locally and independently. With local observation and random sampling, the randomness in rewards and observations leads to randomness in long-term returns. Existing methods such as Value Decomposition Network (VDN) and QMIX estimate the mean value of long-term returns while ignoring randomness. Our proposed model QR-MIX introduces quantile regression, modeling joint state-action values as a distribution, combining QMIX with Implicit Quantile Network (IQN). Besides, because the monotonicity in QMIX limits the expression of joint state-action value distribution and may lead to incorrect estimation results in nonmonotonic cases, we design a flexible loss function to replace the absolute weights found in QMIX. Our methods enhance the expressiveness of our mixing network and are more tolerant of randomness and nonmonotonicity. The experiments demonstrate that QR-MIX outperforms prior works in the StarCraft Multi-Agent Challenge (SMAC) environment.
A hybrid model based on deep LSTM for predicting high-dimensional chaotic systems
Jan 21, 2020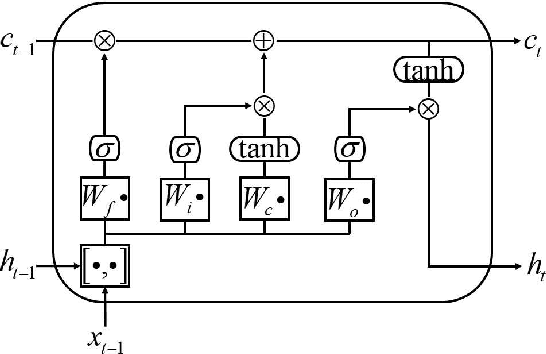
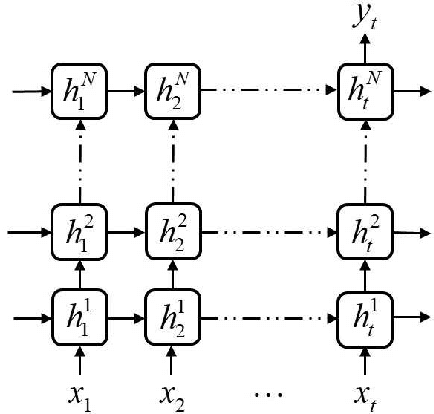
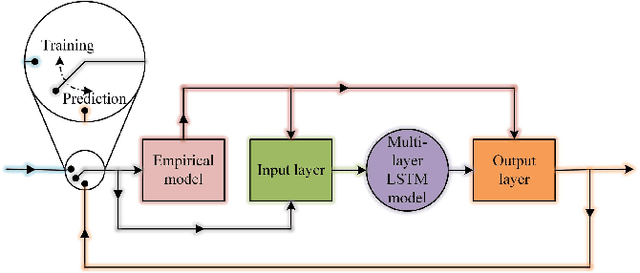
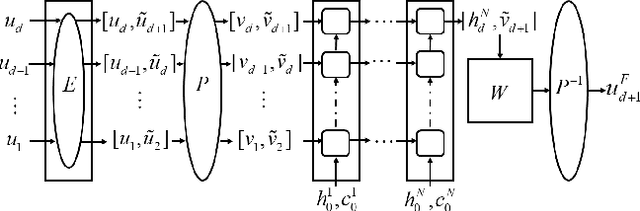
We propose a hybrid method combining the deep long short-term memory (LSTM) model with the inexact empirical model of dynamical systems to predict high-dimensional chaotic systems. The deep hierarchy is encoded into the LSTM by superimposing multiple recurrent neural network layers and the hybrid model is trained with the Adam optimization algorithm. The statistical results of the Mackey-Glass system and the Kuramoto-Sivashinsky system are obtained under the criteria of root mean square error (RMSE) and anomaly correlation coefficient (ACC) using the singe-layer LSTM, the multi-layer LSTM, and the corresponding hybrid method, respectively. The numerical results show that the proposed method can effectively avoid the rapid divergence of the multi-layer LSTM model when reconstructing chaotic attractors, and demonstrate the feasibility of the combination of deep learning based on the gradient descent method and the empirical model.
The Trajectory of Voice Onset Time with Vocal Aging
Oct 15, 2018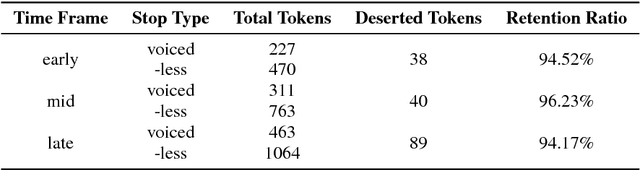
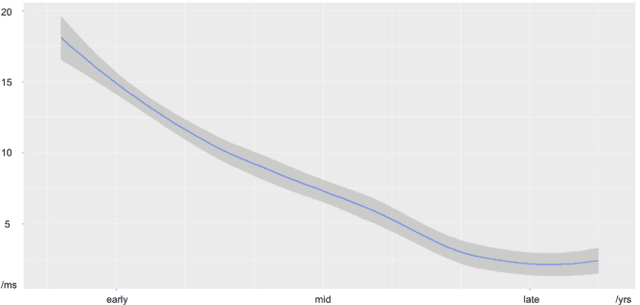
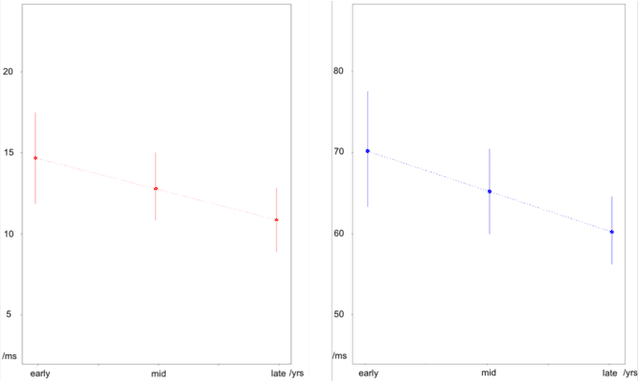
Vocal aging, a universal process of human aging, can largely affect one's language use, possibly including some subtle acoustic features of one's utterances like Voice Onset Time. To figure out the time effects, Queen Elizabeth's Christmas speeches are documented and analyzed in the long-term trend. We build statistical models of time dependence in Voice Onset Time, controlling a wide range of other fixed factors, to present annual variations and the simulated trajectory. It is revealed that the variation range of Voice Onset Time has been narrowing over fifty years with a slight reduction in the mean value, which, possibly, is an effect of diminishing exertion, resulting from subdued muscle contraction, transcending other non-linguistic factors in forming Voice Onset Time patterns over a long time.
* conference