 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward DNN of LUTs: Learning Efficient Image Restoration with Multiple Look-Up Tables
Mar 25, 2023



The widespread usage of high-definition screens on edge devices stimulates a strong demand for efficient image restoration algorithms. The way of caching deep learning models in a look-up table (LUT) is recently introduced to respond to this demand. However, the size of a single LUT grows exponentially with the increase of its indexing capacity, which restricts its receptive field and thus the performance. To overcome this intrinsic limitation of the single-LUT solution, we propose a universal method to construct multiple LUTs like a neural network, termed MuLUT. Firstly, we devise novel complementary indexing patterns, as well as a general implementation for arbitrary patterns, to construct multiple LUTs in parallel. Secondly, we propose a re-indexing mechanism to enable hierarchical indexing between cascaded LUTs. Finally, we introduce channel indexing to allow cross-channel interaction, enabling LUTs to process color channels jointly. In these principled ways, the total size of MuLUT is linear to its indexing capacity, yielding a practical solution to obtain superior performance with the enlarged receptive field. We examine the advantage of MuLUT on various image restoration tasks, including super-resolution, demosaicing, denoising, and deblocking. MuLUT achieves a significant improvement over the single-LUT solution, e.g., up to 1.1dB PSNR for super-resolution and up to 2.8dB PSNR for grayscale denoising, while preserving its efficiency, which is 100$\times$ less in energy cost compared with lightweight deep neural networks. Our code and trained models are publicly available at https://github.com/ddlee-cn/MuLUT.
Automated deep learning segmentation of high-resolution 7 T ex vivo MRI for quantitative analysis of structure-pathology correlations in neurodegenerative diseases
Mar 21, 2023



Ex vivo MRI of the brain provides remarkable advantages over in vivo MRI for visualizing and characterizing detailed neuroanatomy, and helps to link microscale histology studies with morphometric measurements. However, automated segmentation methods for brain mapping in ex vivo MRI are not well developed, primarily due to limited availability of labeled datasets, and heterogeneity in scanner hardware and acquisition protocols. In this work, we present a high resolution dataset of 37 ex vivo post-mortem human brain tissue specimens scanned on a 7T whole-body MRI scanner. We developed a deep learning pipeline to segment the cortical mantle by benchmarking the performance of nine deep neural architectures. We then segment the four subcortical structures: caudate, putamen, globus pallidus, and thalamus; white matter hyperintensities, and the normal appearing white matter. We show excellent generalizing capabilities across whole brain hemispheres in different specimens, and also on unseen images acquired at different magnetic field strengths and different imaging sequence. We then compute volumetric and localized cortical thickness measurements across key regions, and link them with semi-quantitative neuropathological ratings. Our code, containerized executables, and the processed datasets are publicly available at: https://github.com/Pulkit-Khandelwal/upenn-picsl-brain-ex-vivo.
SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BERT Inference
Mar 16, 2023



Dynamic early exiting has been proven to improve the inference speed of the pre-trained language model like BERT. However, all samples must go through all consecutive layers before early exiting and more complex samples usually go through more layers, which still exists redundant computation. In this paper, we propose a novel dynamic early exiting combined with layer skipping for BERT inference named SmartBERT, which adds a skipping gate and an exiting operator into each layer of BERT. SmartBERT can adaptively skip some layers and adaptively choose whether to exit. Besides, we propose cross-layer contrastive learning and combine it into our training phases to boost the intermediate layers and classifiers which would be beneficial for early exiting. To keep the consistent usage of skipping gates between training and inference phases, we propose a hard weight mechanism during training phase. We conduct experiments on eight classification datasets of the GLUE benchmark. Experimental results show that SmartBERT achieves 2-3x computation reduction with minimal accuracy drops compared with BERT and our method outperforms previous methods in both efficiency and accuracy. Moreover, in some complex datasets like RTE and WNLI, we prove that the early exiting based on entropy hardly works, and the skipping mechanism is essential for reducing computation.
Lformer: Text-to-Image Generation with L-shape Block Parallel Decoding
Mar 07, 2023Generative transformers have shown their superiority in synthesizing high-fidelity and high-resolution images, such as good diversity and training stability. However, they suffer from the problem of slow generation since they need to generate a long token sequence autoregressively. To better accelerate the generative transformers while keeping good generation quality, we propose Lformer, a semi-autoregressive text-to-image generation model. Lformer firstly encodes an image into $h{\times}h$ discrete tokens, then divides these tokens into $h$ mirrored L-shape blocks from the top left to the bottom right and decodes the tokens in a block parallelly in each step. Lformer predicts the area adjacent to the previous context like autoregressive models thus it is more stable while accelerating. By leveraging the 2D structure of image tokens, Lformer achieves faster speed than the existing transformer-based methods while keeping good generation quality. Moreover, the pretrained Lformer can edit images without the requirement for finetuning. We can roll back to the early steps for regeneration or edit the image with a bounding box and a text prompt.
An advanced YOLOv3 method for small object detection
Dec 06, 2022



In recent years, object detection has achieved a very large performance improvement, but the detection result of small objects is still not very satisfactory. This work proposes a strategy based on feature fusion and dilated convolution that employs dilated convolution to broaden the receptive field of feature maps at various scales in order to address this issue. On the one hand, it can improve the detection accuracy of larger objects. On the other hand, it provides more contextual information for small objects, which is beneficial to improving the detection accuracy of small objects. The shallow semantic information of small objects is obtained by filtering out the noise in the feature map, and the feature information of more small objects is preserved by using multi-scale fusion feature module and attention mechanism. The fusion of these shallow feature information and deep semantic information can generate richer feature maps for small object detection. Experiments show that this method can have higher accuracy than the traditional YOLOv3 network in the detection of small objects and occluded objects. In addition, we achieve 32.8\% Mean Average Precision on the detection of small objects on MS COCO2017 test set. For 640*640 input, this method has 88.76\% mAP on the PASCAL VOC2012 dataset.
CLIP also Understands Text: Prompting CLIP for Phrase Understanding
Oct 11, 2022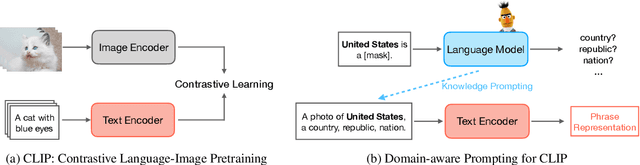
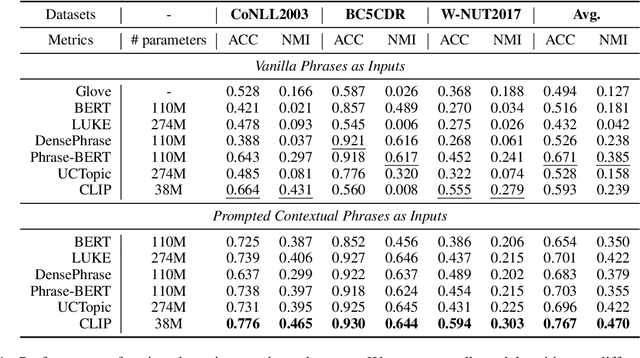
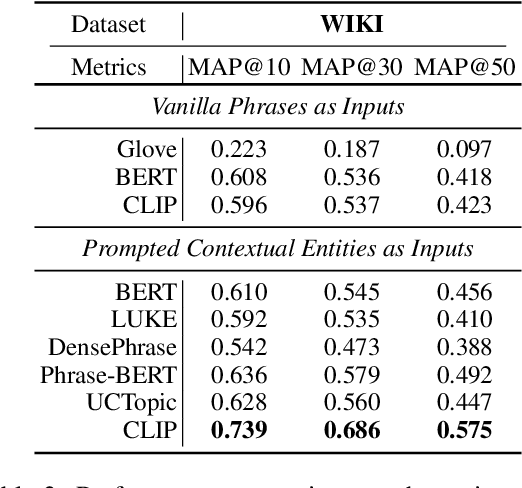
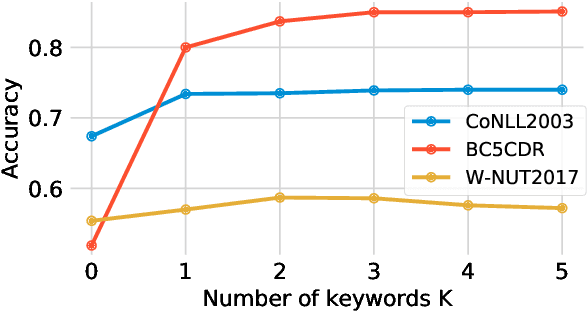
Contrastive Language-Image Pretraining (CLIP) efficiently learns visual concepts by pre-training with natural language supervision. CLIP and its visual encoder have been explored on various vision and language tasks and achieve strong zero-shot or transfer learning performance. However, the application of its text encoder solely for text understanding has been less explored. In this paper, we find that the text encoder of CLIP actually demonstrates strong ability for phrase understanding, and can even significantly outperform popular language models such as BERT with a properly designed prompt. Extensive experiments validate the effectiveness of our method across different datasets and domains on entity clustering and entity set expansion tasks.
Deep Learning for Logo Detection: A Survey
Oct 10, 2022
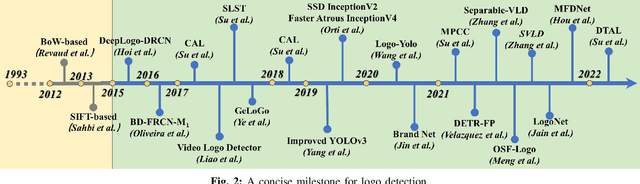

When logos are increasingly created, logo detection has gradually become a research hotspot across many domains and tasks. Recent advances in this area are dominated by deep learning-based solutions, where many datasets, learning strategies, network architectures, etc. have been employed. This paper reviews the advance in applying deep learning techniques to logo detection. Firstly, we discuss a comprehensive account of public datasets designed to facilitate performance evaluation of logo detection algorithms, which tend to be more diverse, more challenging, and more reflective of real life. Next, we perform an in-depth analysis of the existing logo detection strategies and the strengths and weaknesses of each learning strategy. Subsequently, we summarize the applications of logo detection in various fields, from intelligent transportation and brand monitoring to copyright and trademark compliance. Finally, we analyze the potential challenges and present the future directions for the development of logo detection to complete this survey.
UCEpic: Unifying Aspect Planning and Lexical Constraints for Explainable Recommendation
Sep 28, 2022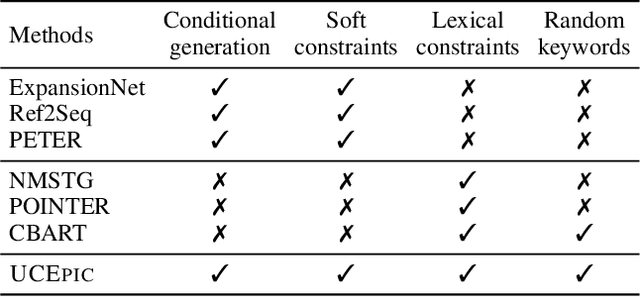
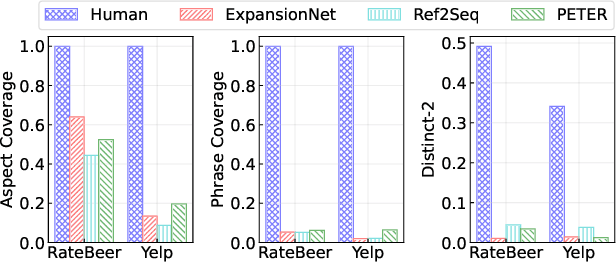
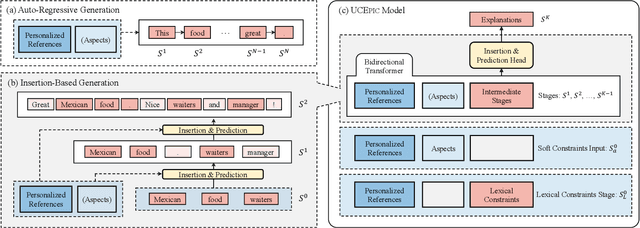

Personalized natural language generation for explainable recommendations plays a key role in justifying why a recommendation might match a user's interests. Existing models usually control the generation process by soft constraints (e.g.,~aspect planning). While promising, these methods struggle to generate specific information correctly, which prevents generated explanations from being informative and diverse. In this paper, we propose UCEpic, an explanation generation model that unifies aspect planning and lexical constraints for controllable personalized generation. Specifically, we first pre-train a non-personalized text generator by our proposed robust insertion process so that the model is able to generate sentences containing lexical constraints. Then, we demonstrate the method of incorporating aspect planning and personalized references into the insertion process to obtain personalized explanations. Compared to previous work controlled by soft constraints, UCEpic incorporates specific information from keyphrases and then largely improves the diversity and informativeness of generated explanations. Extensive experiments on RateBeer and Yelp show that UCEpic can generate high-quality and diverse explanations for recommendations.
Representing Knowledge by Spans: A Knowledge-Enhanced Model for Information Extraction
Aug 20, 2022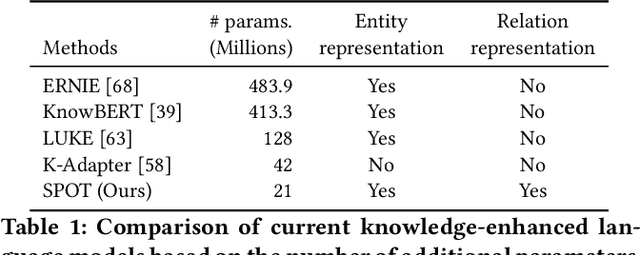
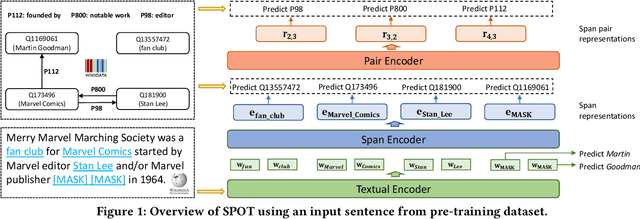
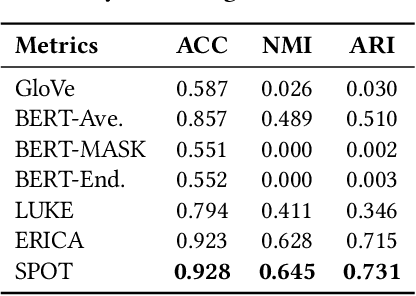
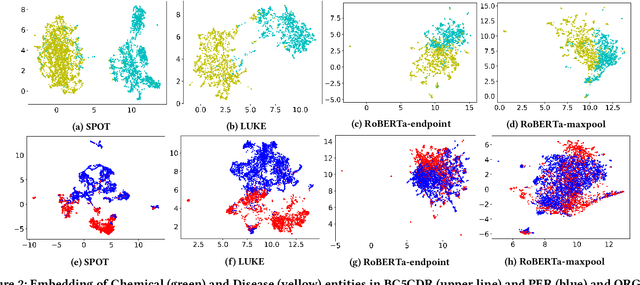
Knowledge-enhanced pre-trained models for language representation have been shown to be more effective in knowledge base construction tasks (i.e.,~relation extraction) than language models such as BERT. These knowledge-enhanced language models incorporate knowledge into pre-training to generate representations of entities or relationships. However, existing methods typically represent each entity with a separate embedding. As a result, these methods struggle to represent out-of-vocabulary entities and a large amount of parameters, on top of their underlying token models (i.e.,~the transformer), must be used and the number of entities that can be handled is limited in practice due to memory constraints. Moreover, existing models still struggle to represent entities and relationships simultaneously. To address these problems, we propose a new pre-trained model that learns representations of both entities and relationships from token spans and span pairs in the text respectively. By encoding spans efficiently with span modules, our model can represent both entities and their relationships but requires fewer parameters than existing models. We pre-trained our model with the knowledge graph extracted from Wikipedia and test it on a broad range of supervised and unsupervised information extraction tasks. Results show that our model learns better representations for both entities and relationships than baselines, while in supervised settings, fine-tuning our model outperforms RoBERTa consistently and achieves competitive results on information extraction tasks.
Personalized Showcases: Generating Multi-Modal Explanations for Recommendations
Jun 30, 2022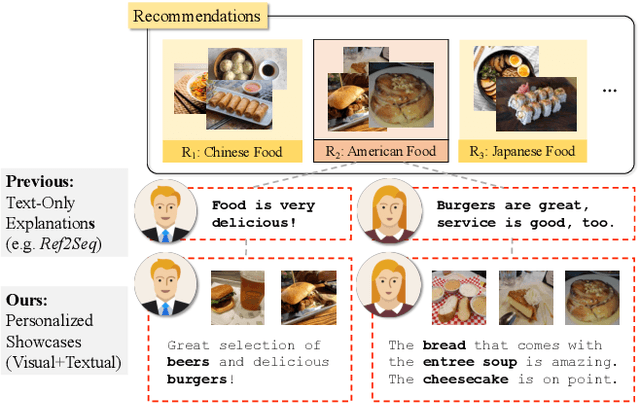
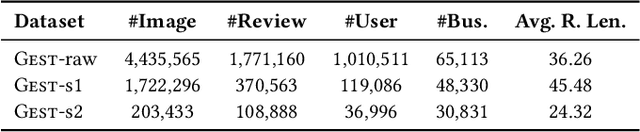

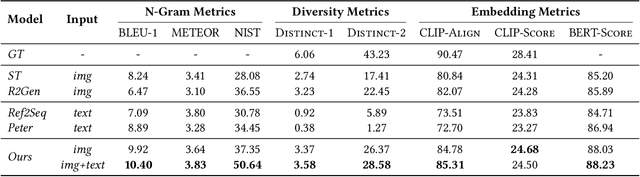
Existing explanation models generate only text for recommendations but still struggle to produce diverse contents. In this paper, to further enrich explanations, we propose a new task named personalized showcases, in which we provide both textual and visual information to explain our recommendations. Specifically, we first select a personalized image set that is the most relevant to a user's interest toward a recommended item. Then, natural language explanations are generated accordingly given our selected images. For this new task, we collect a large-scale dataset from Google Local (i.e.,~maps) and construct a high-quality subset for generating multi-modal explanations. We propose a personalized multi-modal framework which can generate diverse and visually-aligned explanations via contrastive learning. Experiments show that our framework benefits from different modalities as inputs, and is able to produce more diverse and expressive explanations compared to previous methods on a variety of evaluation metrics.