 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Scaling Agents for Computer Use
Oct 02, 2025Computer-use agents (CUAs) hold promise for automating everyday digital tasks, but their unreliability and high variance hinder their application to long-horizon, complex tasks. We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives that describe the agents' rollouts. It enables both wide exploration and principled trajectory selection, substantially improving robustness and success rates. On OSWorld, our bBoN scaling method establishes a new state of the art (SoTA) at 69.9%, significantly outperforming prior methods and approaching human-level performance at 72%, with comprehensive ablations validating key design choices. We further demonstrate strong generalization results to different operating systems on WindowsAgentArena and AndroidWorld. Crucially, our results highlight the unreasonable effectiveness of scaling CUAs, when you do it right: effective scaling requires structured trajectory understanding and selection, and bBoN provides a practical framework to achieve this.
Deep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
IIKL: Isometric Immersion Kernel Learning with Riemannian Manifold for Geometric Preservation
May 07, 2025Geometric representation learning in preserving the intrinsic geometric and topological properties for discrete non-Euclidean data is crucial in scientific applications. Previous research generally mapped non-Euclidean discrete data into Euclidean space during representation learning, which may lead to the loss of some critical geometric information. In this paper, we propose a novel Isometric Immersion Kernel Learning (IIKL) method to build Riemannian manifold and isometrically induce Riemannian metric from discrete non-Euclidean data. We prove that Isometric immersion is equivalent to the kernel function in the tangent bundle on the manifold, which explicitly guarantees the invariance of the inner product between vectors in the arbitrary tangent space throughout the learning process, thus maintaining the geometric structure of the original data. Moreover, a novel parameterized learning model based on IIKL is introduced, and an alternating training method for this model is derived using Maximum Likelihood Estimation (MLE), ensuring efficient convergence. Experimental results proved that using the learned Riemannian manifold and its metric, our model preserved the intrinsic geometric representation of data in both 3D and high-dimensional datasets successfully, and significantly improved the accuracy of downstream tasks, such as data reconstruction and classification. It is showed that our method could reduce the inner product invariant loss by more than 90% compared to state-of-the-art (SOTA) methods, also achieved an average 40% improvement in downstream reconstruction accuracy and a 90% reduction in error for geometric metrics involving isometric and conformal.
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Apr 01, 2025Computer use agents automate digital tasks by directly interacting with graphical user interfaces (GUIs) on computers and mobile devices, offering significant potential to enhance human productivity by completing an open-ended space of user queries. However, current agents face significant challenges: imprecise grounding of GUI elements, difficulties with long-horizon task planning, and performance bottlenecks from relying on single generalist models for diverse cognitive tasks. To this end, we introduce Agent S2, a novel compositional framework that delegates cognitive responsibilities across various generalist and specialist models. We propose a novel Mixture-of-Grounding technique to achieve precise GUI localization and introduce Proactive Hierarchical Planning, dynamically refining action plans at multiple temporal scales in response to evolving observations. Evaluations demonstrate that Agent S2 establishes new state-of-the-art (SOTA) performance on three prominent computer use benchmarks. Specifically, Agent S2 achieves 18.9% and 32.7% relative improvements over leading baseline agents such as Claude Computer Use and UI-TARS on the OSWorld 15-step and 50-step evaluation. Moreover, Agent S2 generalizes effectively to other operating systems and applications, surpassing previous best methods by 52.8% on WindowsAgentArena and by 16.52% on AndroidWorld relatively. Code available at https://github.com/simular-ai/Agent-S.
DisCo-DSO: Coupling Discrete and Continuous Optimization for Efficient Generative Design in Hybrid Spaces
Dec 15, 2024



We consider the challenge of black-box optimization within hybrid discrete-continuous and variable-length spaces, a problem that arises in various applications, such as decision tree learning and symbolic regression. We propose DisCo-DSO (Discrete-Continuous Deep Symbolic Optimization), a novel approach that uses a generative model to learn a joint distribution over discrete and continuous design variables to sample new hybrid designs. In contrast to standard decoupled approaches, in which the discrete and continuous variables are optimized separately, our joint optimization approach uses fewer objective function evaluations, is robust against non-differentiable objectives, and learns from prior samples to guide the search, leading to significant improvement in performance and sample efficiency. Our experiments on a diverse set of optimization tasks demonstrate that the advantages of DisCo-DSO become increasingly evident as the complexity of the problem increases. In particular, we illustrate DisCo-DSO's superiority over the state-of-the-art methods for interpretable reinforcement learning with decision trees.
Agent S: An Open Agentic Framework that Uses Computers Like a Human
Oct 10, 2024



We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at https://github.com/simular-ai/Agent-S.
Multi-Agent Reinforcement Learning for Adaptive Mesh Refinement
Nov 04, 2022



Adaptive mesh refinement (AMR) is necessary for efficient finite element simulations of complex physical phenomenon, as it allocates limited computational budget based on the need for higher or lower resolution, which varies over space and time. We present a novel formulation of AMR as a fully-cooperative Markov game, in which each element is an independent agent who makes refinement and de-refinement choices based on local information. We design a novel deep multi-agent reinforcement learning (MARL) algorithm called Value Decomposition Graph Network (VDGN), which solves the two core challenges that AMR poses for MARL: posthumous credit assignment due to agent creation and deletion, and unstructured observations due to the diversity of mesh geometries. For the first time, we show that MARL enables anticipatory refinement of regions that will encounter complex features at future times, thereby unlocking entirely new regions of the error-cost objective landscape that are inaccessible by traditional methods based on local error estimators. Comprehensive experiments show that VDGN policies significantly outperform error threshold-based policies in global error and cost metrics. We show that learned policies generalize to test problems with physical features, mesh geometries, and longer simulation times that were not seen in training. We also extend VDGN with multi-objective optimization capabilities to find the Pareto front of the tradeoff between cost and error.
Do Deep Neural Networks Always Perform Better When Eating More Data?
May 30, 2022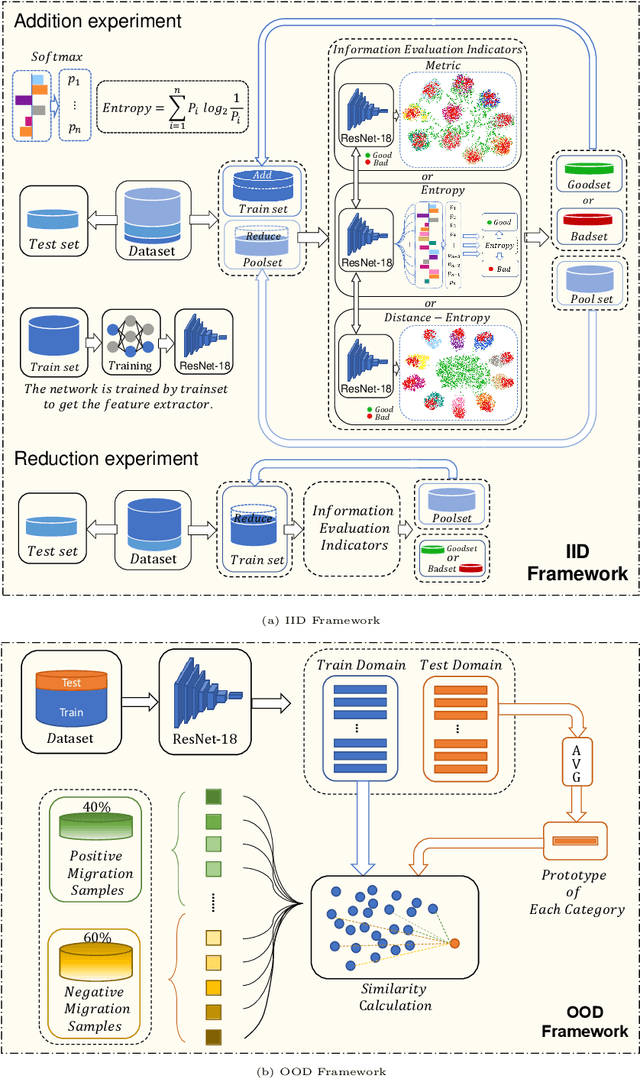
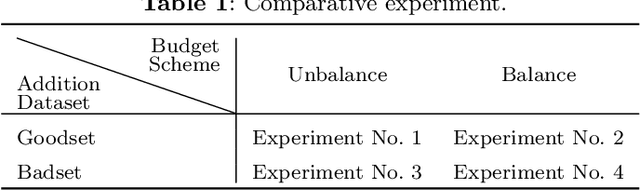
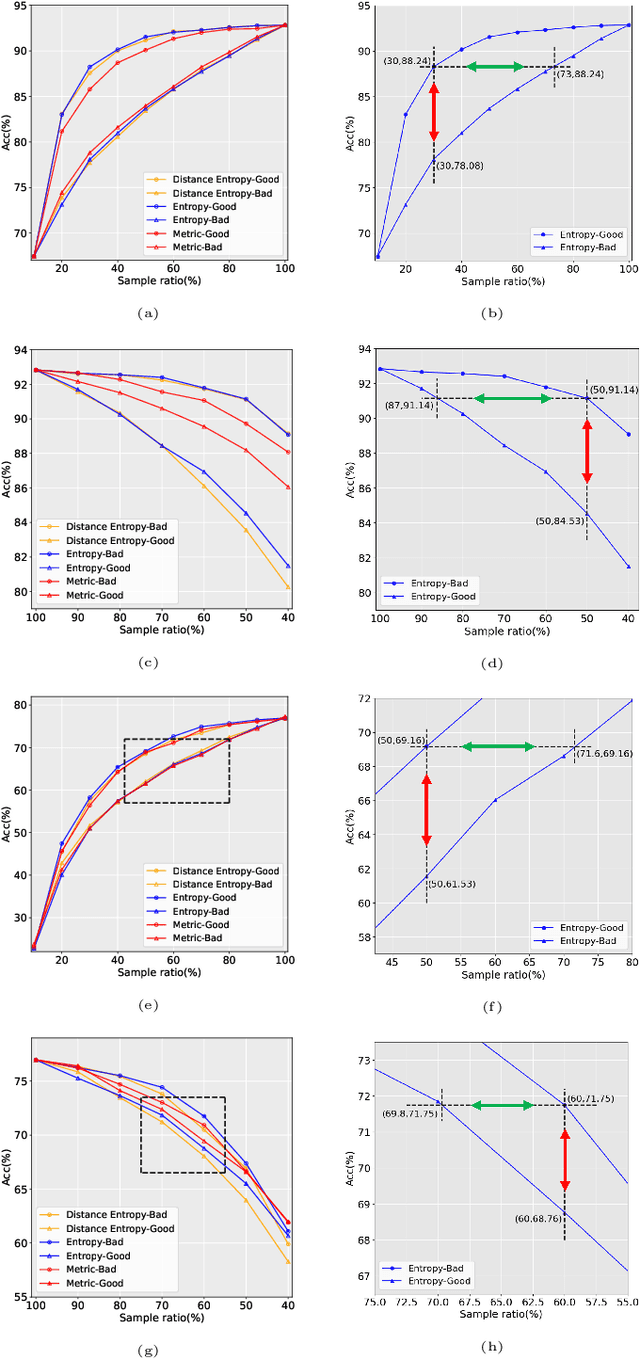
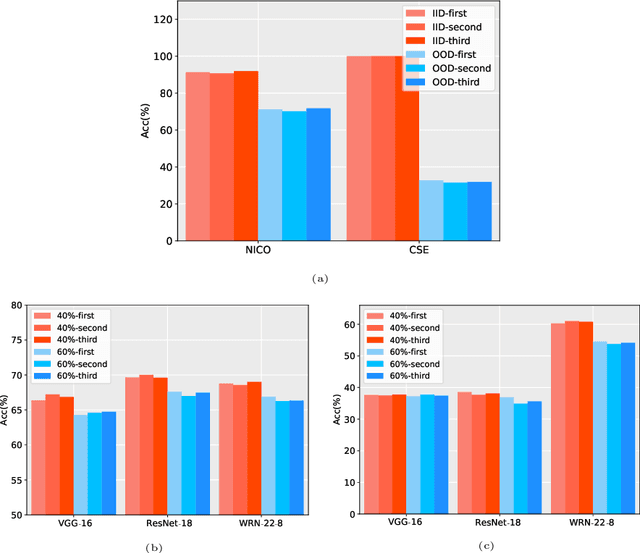
Data has now become a shortcoming of deep learning. Researchers in their own fields share the thinking that "deep neural networks might not always perform better when they eat more data," which still lacks experimental validation and a convincing guiding theory. Here to fill this lack, we design experiments from Identically Independent Distribution(IID) and Out of Distribution(OOD), which give powerful answers. For the purpose of guidance, based on the discussion of results, two theories are proposed: under IID condition, the amount of information determines the effectivity of each sample, the contribution of samples and difference between classes determine the amount of sample information and the amount of class information; under OOD condition, the cross-domain degree of samples determine the contributions, and the bias-fitting caused by irrelevant elements is a significant factor of cross-domain. The above theories provide guidance from the perspective of data, which can promote a wide range of practical applications of artificial intelligence.
Permutation Invariant Policy Optimization for Mean-Field Multi-Agent Reinforcement Learning: A Principled Approach
May 18, 2021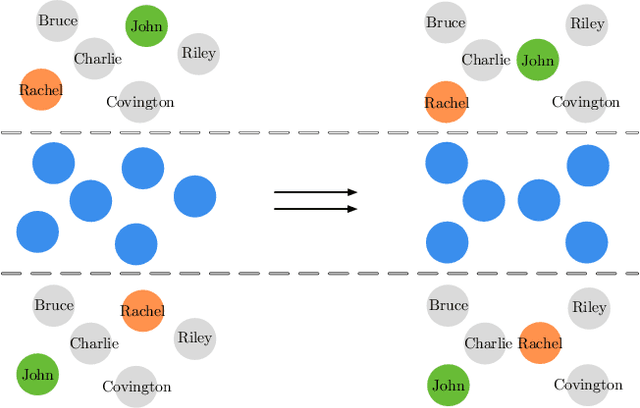
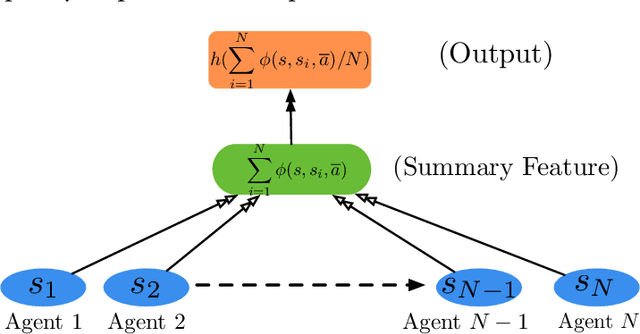
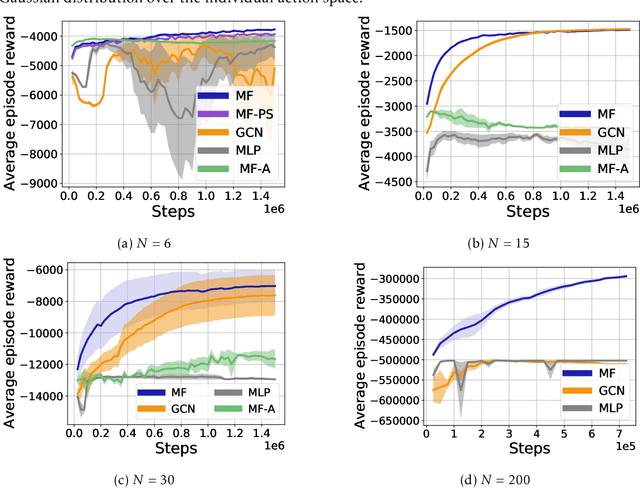
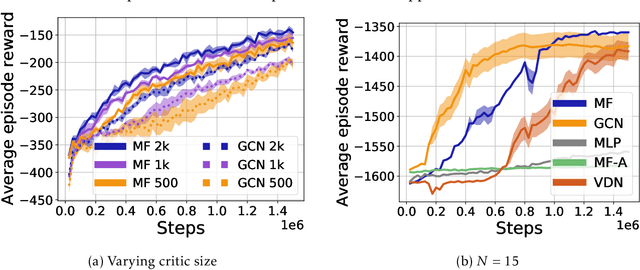
Multi-agent reinforcement learning (MARL) becomes more challenging in the presence of more agents, as the capacity of the joint state and action spaces grows exponentially in the number of agents. To address such a challenge of scale, we identify a class of cooperative MARL problems with permutation invariance, and formulate it as a mean-field Markov decision processes (MDP). To exploit the permutation invariance therein, we propose the mean-field proximal policy optimization (MF-PPO) algorithm, at the core of which is a permutation-invariant actor-critic neural architecture. We prove that MF-PPO attains the globally optimal policy at a sublinear rate of convergence. Moreover, its sample complexity is independent of the number of agents. We validate the theoretical advantages of MF-PPO with numerical experiments in the multi-agent particle environment (MPE). In particular, we show that the inductive bias introduced by the permutation-invariant neural architecture enables MF-PPO to outperform existing competitors with a smaller number of model parameters, which is the key to its generalization performance.
Reinforcement Learning for Adaptive Mesh Refinement
Mar 01, 2021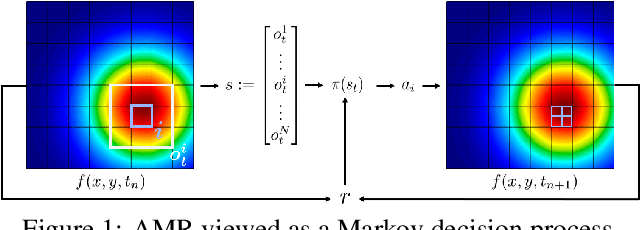
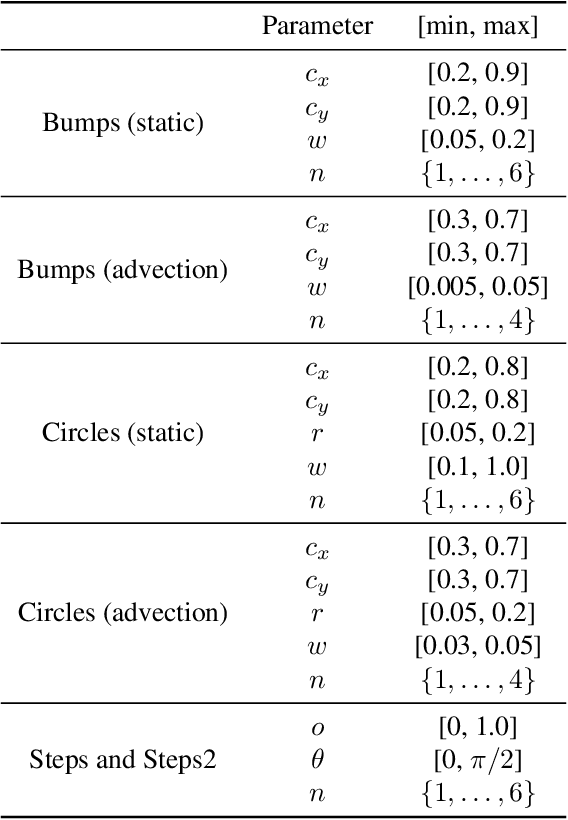
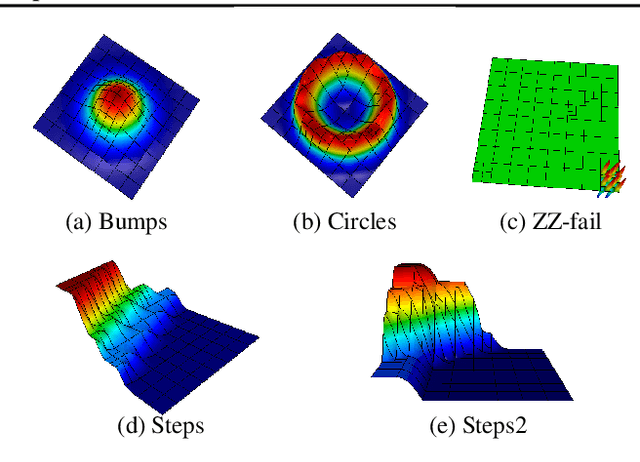

Large-scale finite element simulations of complex physical systems governed by partial differential equations crucially depend on adaptive mesh refinement (AMR) to allocate computational budget to regions where higher resolution is required. Existing scalable AMR methods make heuristic refinement decisions based on instantaneous error estimation and thus do not aim for long-term optimality over an entire simulation. We propose a novel formulation of AMR as a Markov decision process and apply deep reinforcement learning (RL) to train refinement policies directly from simulation. AMR poses a new problem for RL in that both the state dimension and available action set changes at every step, which we solve by proposing new policy architectures with differing generality and inductive bias. The model sizes of these policy architectures are independent of the mesh size and hence scale to arbitrarily large and complex simulations. We demonstrate in comprehensive experiments on static function estimation and the advection of different fields that RL policies can be competitive with a widely-used error estimator and generalize to larger, more complex, and unseen test problems.