 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Deep Learning: Interpretations, Interpretability, Trustworthiness, and Beyond
Mar 19, 2021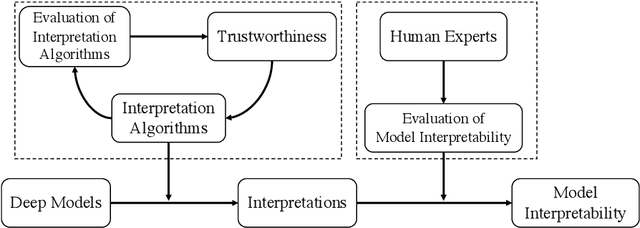
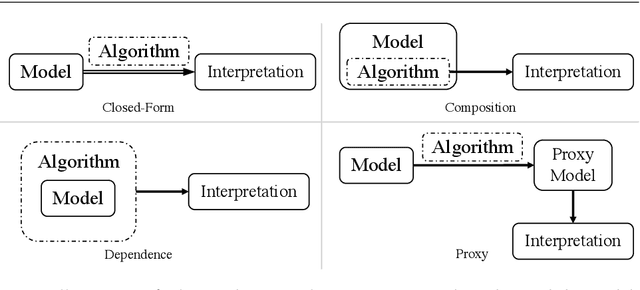
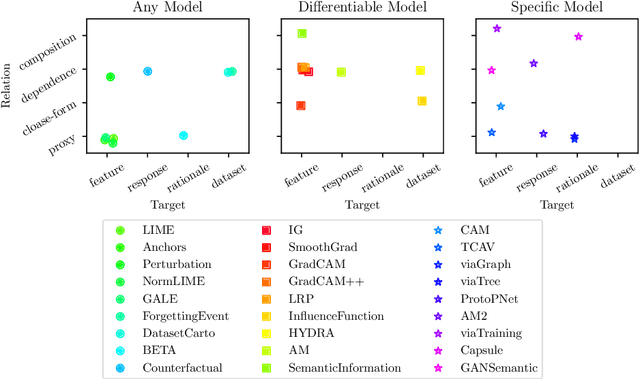

Deep neural networks have been well-known for their superb performance in handling various machine learning and artificial intelligence tasks. However, due to their over-parameterized black-box nature, it is often difficult to understand the prediction results of deep models. In recent years, many interpretation tools have been proposed to explain or reveal the ways that deep models make decisions. In this paper, we review this line of research and try to make a comprehensive survey. Specifically, we introduce and clarify two basic concepts-interpretations and interpretability-that people usually get confused. First of all, to address the research efforts in interpretations, we elaborate the design of several recent interpretation algorithms, from different perspectives, through proposing a new taxonomy. Then, to understand the results of interpretation, we also survey the performance metrics for evaluating interpretation algorithms. Further, we summarize the existing work in evaluating models' interpretability using "trustworthy" interpretation algorithms. Finally, we review and discuss the connections between deep models' interpretations and other factors, such as adversarial robustness and data augmentations, and we introduce several open-source libraries for interpretation algorithms and evaluation approaches.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021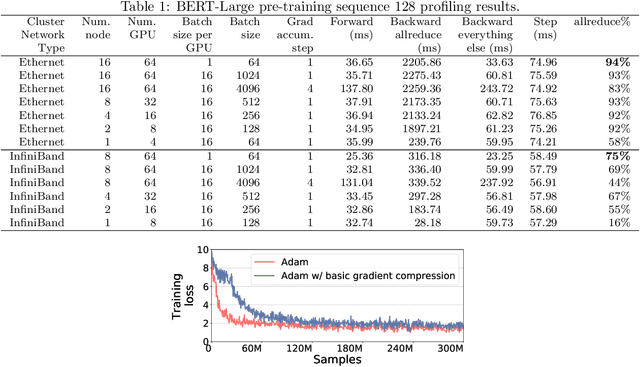
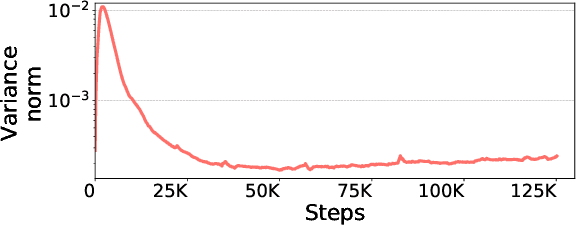
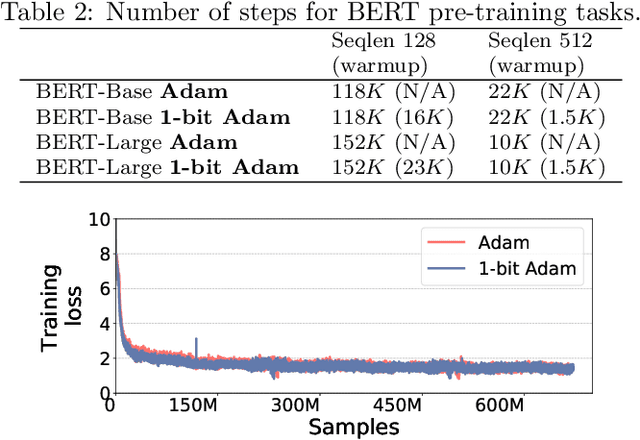

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments
Feb 04, 2021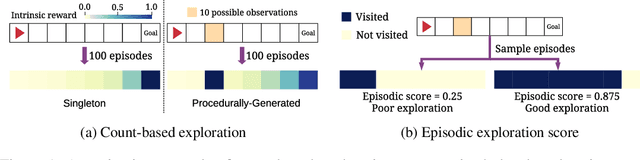
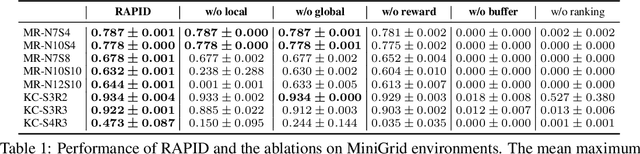
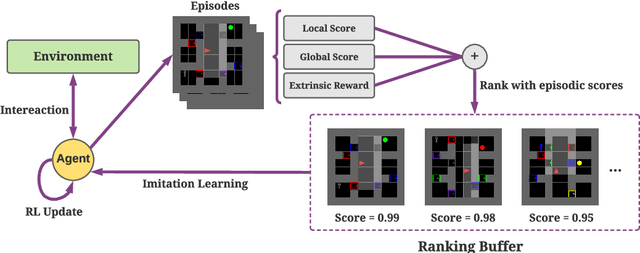

Exploration under sparse reward is a long-standing challenge of model-free reinforcement learning. The state-of-the-art methods address this challenge by introducing intrinsic rewards to encourage exploration in novel states or uncertain environment dynamics. Unfortunately, methods based on intrinsic rewards often fall short in procedurally-generated environments, where a different environment is generated in each episode so that the agent is not likely to visit the same state more than once. Motivated by how humans distinguish good exploration behaviors by looking into the entire episode, we introduce RAPID, a simple yet effective episode-level exploration method for procedurally-generated environments. RAPID regards each episode as a whole and gives an episodic exploration score from both per-episode and long-term views. Those highly scored episodes are treated as good exploration behaviors and are stored in a small ranking buffer. The agent then imitates the episodes in the buffer to reproduce the past good exploration behaviors. We demonstrate our method on several procedurally-generated MiniGrid environments, a first-person-view 3D Maze navigation task from MiniWorld, and several sparse MuJoCo tasks. The results show that RAPID significantly outperforms the state-of-the-art intrinsic reward strategies in terms of sample efficiency and final performance. The code is available at https://github.com/daochenzha/rapid
C-Watcher: A Framework for Early Detection of High-Risk Neighborhoods Ahead of COVID-19 Outbreak
Jan 27, 2021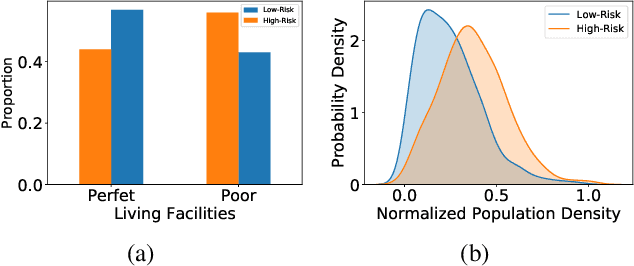
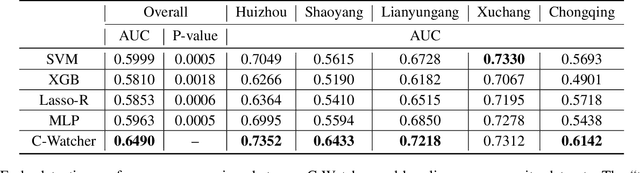
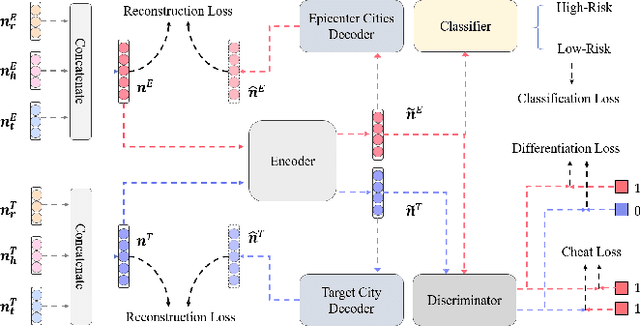
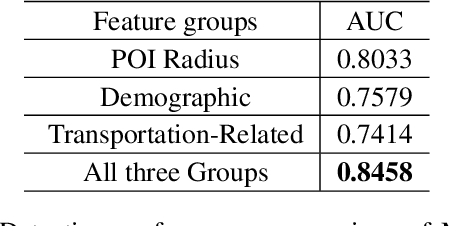
The novel coronavirus disease (COVID-19) has crushed daily routines and is still rampaging through the world. Existing solution for nonpharmaceutical interventions usually needs to timely and precisely select a subset of residential urban areas for containment or even quarantine, where the spatial distribution of confirmed cases has been considered as a key criterion for the subset selection. While such containment measure has successfully stopped or slowed down the spread of COVID-19 in some countries, it is criticized for being inefficient or ineffective, as the statistics of confirmed cases are usually time-delayed and coarse-grained. To tackle the issues, we propose C-Watcher, a novel data-driven framework that aims at screening every neighborhood in a target city and predicting infection risks, prior to the spread of COVID-19 from epicenters to the city. In terms of design, C-Watcher collects large-scale long-term human mobility data from Baidu Maps, then characterizes every residential neighborhood in the city using a set of features based on urban mobility patterns. Furthermore, to transfer the firsthand knowledge (witted in epicenters) to the target city before local outbreaks, we adopt a novel adversarial encoder framework to learn "city-invariant" representations from the mobility-related features for precise early detection of high-risk neighborhoods, even before any confirmed cases known, in the target city. We carried out extensive experiments on C-Watcher using the real-data records in the early stage of COVID-19 outbreaks, where the results demonstrate the efficiency and effectiveness of C-Watcher for early detection of high-risk neighborhoods from a large number of cities.
Once-for-All Adversarial Training: In-Situ Tradeoff between Robustness and Accuracy for Free
Nov 10, 2020
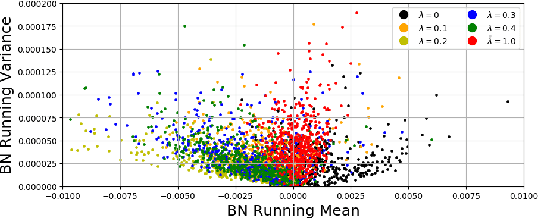
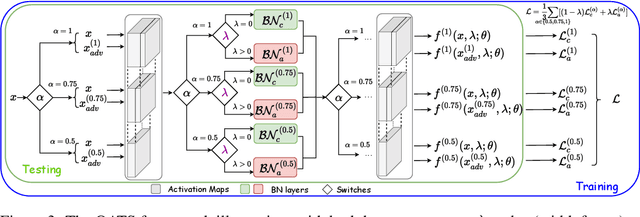
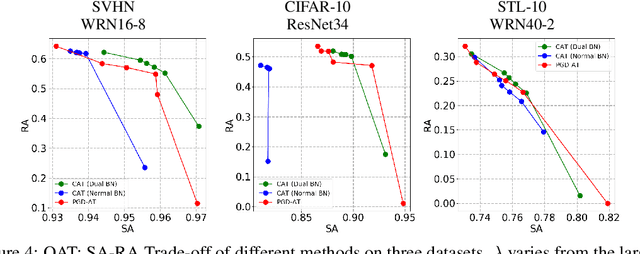
Adversarial training and its many variants substantially improve deep network robustness, yet at the cost of compromising standard accuracy. Moreover, the training process is heavy and hence it becomes impractical to thoroughly explore the trade-off between accuracy and robustness. This paper asks this new question: how to quickly calibrate a trained model in-situ, to examine the achievable trade-offs between its standard and robust accuracies, without (re-)training it many times? Our proposed framework, Once-for-all Adversarial Training (OAT), is built on an innovative model-conditional training framework, with a controlling hyper-parameter as the input. The trained model could be adjusted among different standard and robust accuracies "for free" at testing time. As an important knob, we exploit dual batch normalization to separate standard and adversarial feature statistics, so that they can be learned in one model without degrading performance. We further extend OAT to a Once-for-all Adversarial Training and Slimming (OATS) framework, that allows for the joint trade-off among accuracy, robustness and runtime efficiency. Experiments show that, without any re-training nor ensembling, OAT/OATS achieve similar or even superior performance compared to dedicatedly trained models at various configurations. Our codes and pretrained models are available at: https://github.com/VITA-Group/Once-for-All-Adversarial-Training.
Federated Bandit: A Gossiping Approach
Oct 24, 2020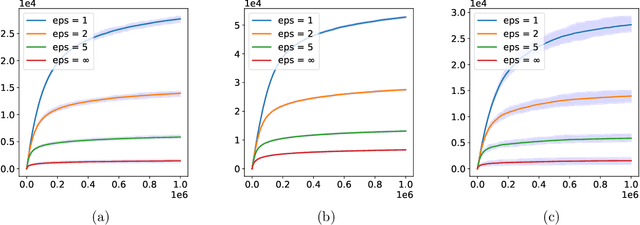
In this paper, we study \emph{Federated Bandit}, a decentralized Multi-Armed Bandit problem with a set of $N$ agents, who can only communicate their local data with neighbors described by a connected graph $G$. Each agent makes a sequence of decisions on selecting an arm from $M$ candidates, yet they only have access to local and potentially biased feedback/evaluation of the true reward for each action taken. Learning only locally will lead agents to sub-optimal actions while converging to a no-regret strategy requires a collection of distributed data. Motivated by the proposal of federated learning, we aim for a solution with which agents will never share their local observations with a central entity, and will be allowed to only share a private copy of his/her own information with their neighbors. We first propose a decentralized bandit algorithm \texttt{Gossip\_UCB}, which is a coupling of variants of both the classical gossiping algorithm and the celebrated Upper Confidence Bound (UCB) bandit algorithm. We show that \texttt{Gossip\_UCB} successfully adapts local bandit learning into a global gossiping process for sharing information among connected agents, and achieves guaranteed regret at the order of $O(\max\{ \texttt{poly}(N,M) \log T, \texttt{poly}(N,M)\log_{\lambda_2^{-1}} N\})$ for all $N$ agents, where $\lambda_2\in(0,1)$ is the second largest eigenvalue of the expected gossip matrix, which is a function of $G$. We then propose \texttt{Fed\_UCB}, a differentially private version of \texttt{Gossip\_UCB}, in which the agents preserve $\epsilon$-differential privacy of their local data while achieving $O(\max \{\frac{\texttt{poly}(N,M)}{\epsilon}\log^{2.5} T, \texttt{poly}(N,M) (\log_{\lambda_2^{-1}} N + \log T) \})$ regret.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020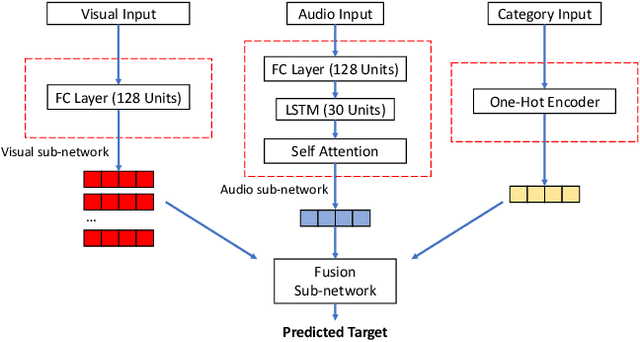
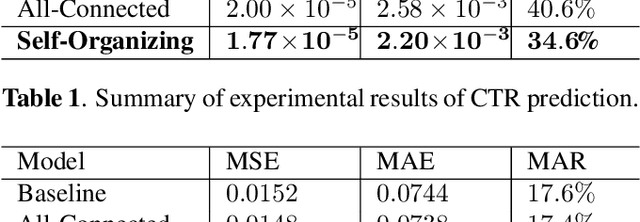
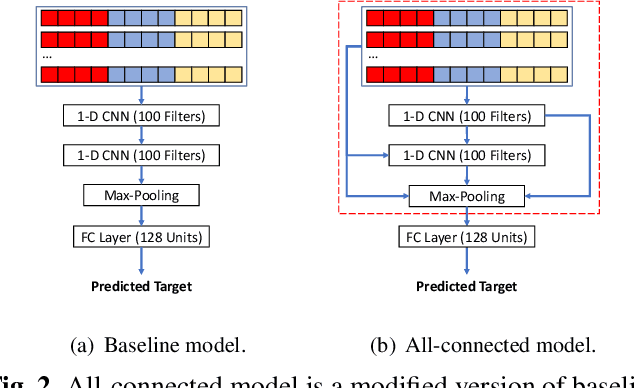
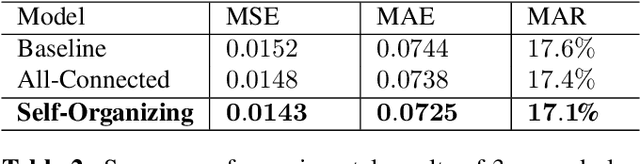
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Ensemble Chinese End-to-End Spoken Language Understanding for Abnormal Event Detection from audio stream
Oct 19, 2020
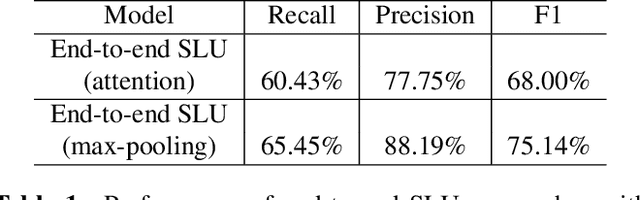

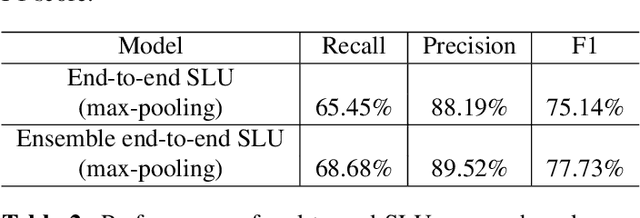
Conventional spoken language understanding (SLU) consist of two stages, the first stage maps speech to text by automatic speech recognition (ASR), and the second stage maps text to intent by natural language understanding (NLU). End-to-end SLU maps speech directly to intent through a single deep learning model. Previous end-to-end SLU models are primarily used for English environment due to lacking large scale SLU dataset in Chines, and use only one ASR model to extract features from speech. With the help of Kuaishou technology, a large scale SLU dataset in Chinese is collected to detect abnormal event in their live audio stream. Based on this dataset, this paper proposed a ensemble end-to-end SLU model used for Chinese environment. This ensemble SLU models extracted hierarchies features using multiple pre-trained ASR models, leading to better representation of phoneme level and word level information. This proposed approached achieve 9.7% increase of accuracy compared to previous end-to-end SLU model.
Themes Inferred Audio-visual Correspondence Learning
Sep 14, 2020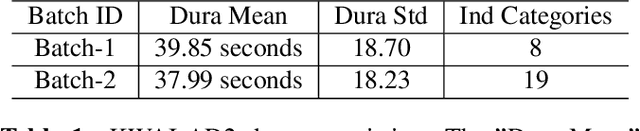
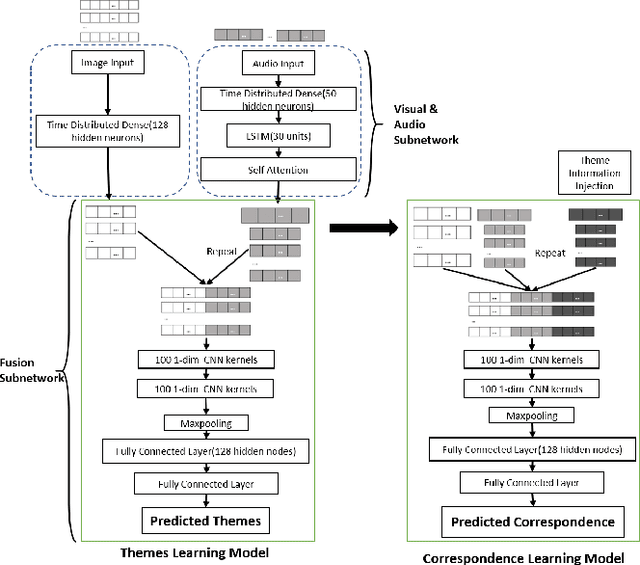
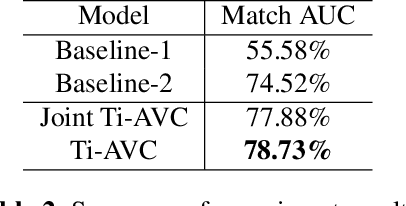
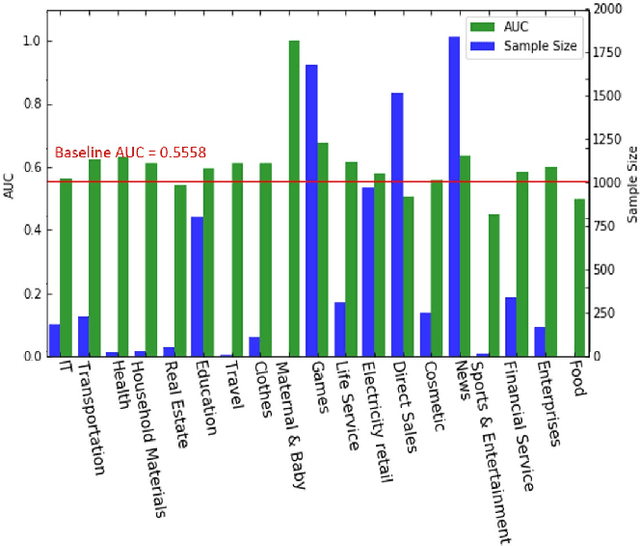
The applications of short-termuser generated video(UGV),such as snapchat, youtube short-term videos, booms recently,raising lots of multimodal machine learning tasks. Amongthem, learning the correspondence between audio and vi-sual information from videos is a challenging one. Mostprevious work of theaudio-visual correspondence(AVC)learning only investigated on constrained videos or simplesettings, which may not fit the application of UGV. In thispaper, we proposed new principles for AVC and introduced anew framework to set sight on the themes of videos to facili-tate AVC learning. We also released the KWAI-AD-AudViscorpus which contained 85432 short advertisement videos(around 913 hours) made by users. We evaluated our pro-posed approach on this corpus and it was able to outperformthe baseline by 23.15% absolute differenc
APMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Aug 28, 2020
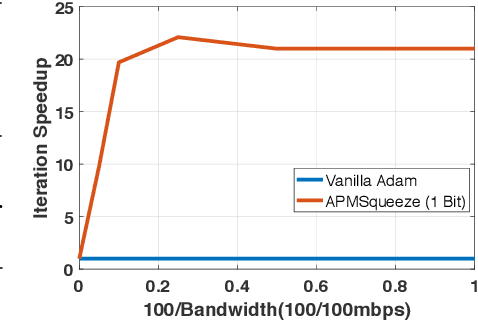
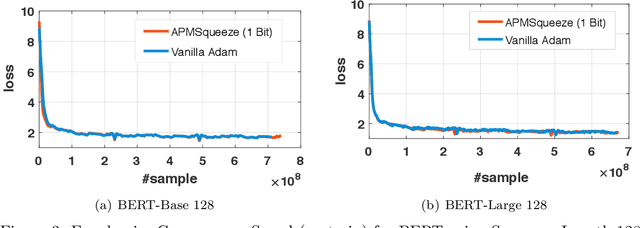
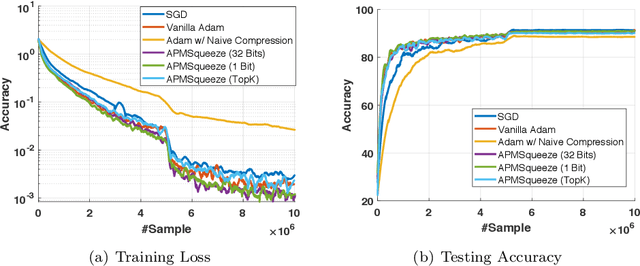
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.