 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Poisoning Attacks on Federated Machine Learning
Apr 19, 2020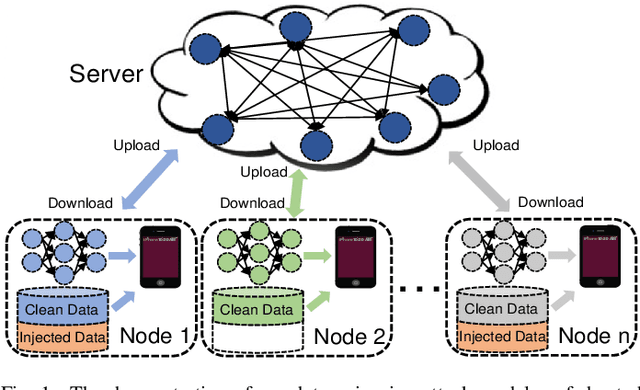
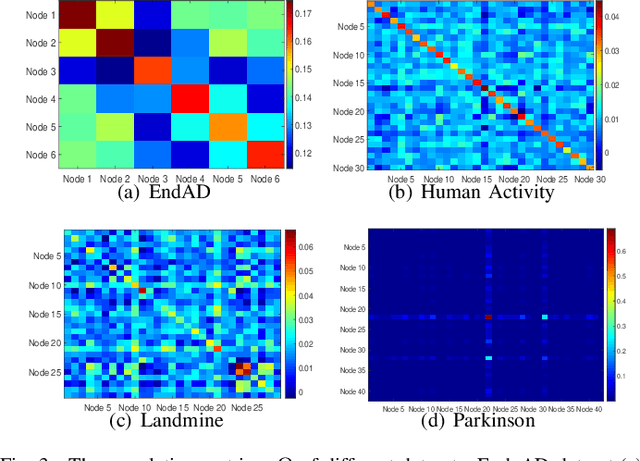
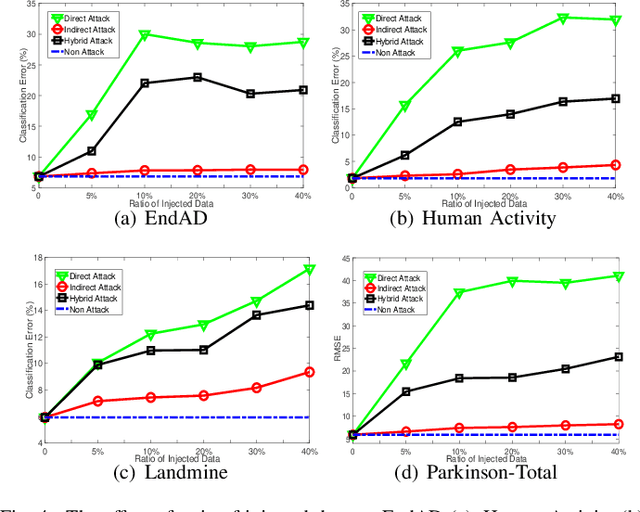
Federated machine learning which enables resource constrained node devices (e.g., mobile phones and IoT devices) to learn a shared model while keeping the training data local, can provide privacy, security and economic benefits by designing an effective communication protocol. However, the communication protocol amongst different nodes could be exploited by attackers to launch data poisoning attacks, which has been demonstrated as a big threat to most machine learning models. In this paper, we attempt to explore the vulnerability of federated machine learning. More specifically, we focus on attacking a federated multi-task learning framework, which is a federated learning framework via adopting a general multi-task learning framework to handle statistical challenges. We formulate the problem of computing optimal poisoning attacks on federated multi-task learning as a bilevel program that is adaptive to arbitrary choice of target nodes and source attacking nodes. Then we propose a novel systems-aware optimization method, ATTack on Federated Learning (AT2FL), which is efficiency to derive the implicit gradients for poisoned data, and further compute optimal attack strategies in the federated machine learning. Our work is an earlier study that considers issues of data poisoning attack for federated learning. To the end, experimental results on real-world datasets show that federated multi-task learning model is very sensitive to poisoning attacks, when the attackers either directly poison the target nodes or indirectly poison the related nodes by exploiting the communication protocol.
Depth Edge Guided CNNs for Sparse Depth Upsampling
Mar 23, 2020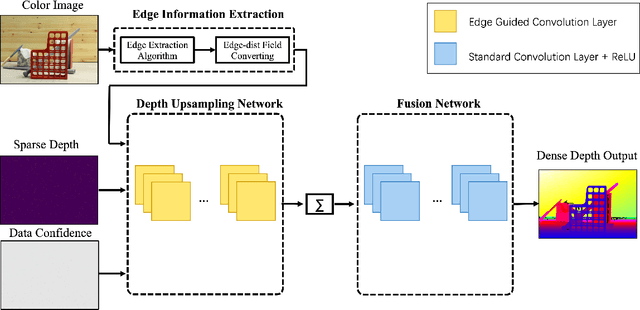
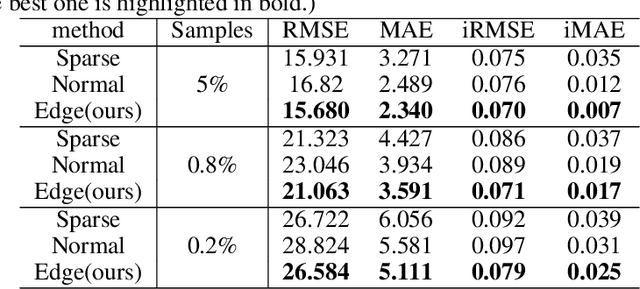
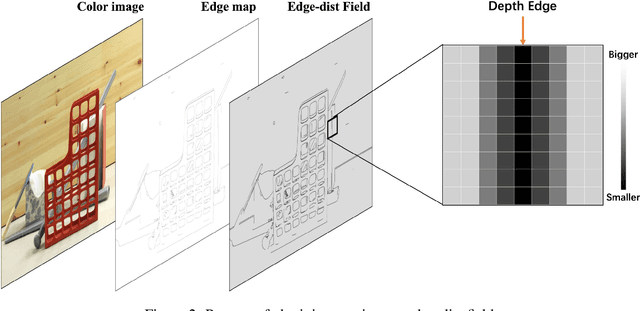
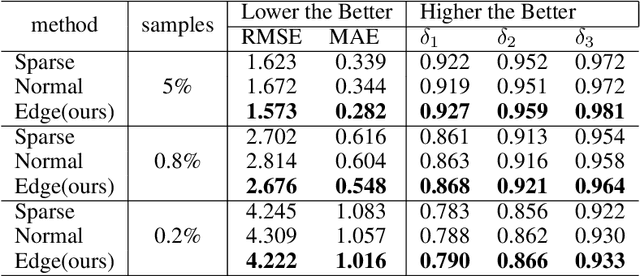
Guided sparse depth upsampling aims to upsample an irregularly sampled sparse depth map when an aligned high-resolution color image is given as guidance. Many neural networks have been designed for this task. However, they often ignore the structural difference between the depth and the color image, resulting in obvious artifacts such as texture copy and depth blur at the upsampling depth. Inspired by the normalized convolution operation, we propose a guided convolutional layer to recover dense depth from sparse and irregular depth image with an depth edge image as guidance. Our novel guided network can prevent the depth value from crossing the depth edge to facilitate upsampling. We further design a convolution network based on proposed convolutional layer to combine the advantages of different algorithms and achieve better performance. We conduct comprehensive experiments to verify our method on real-world indoor and synthetic outdoor datasets. Our method produces strong results. It outperforms state-of-the-art methods on the Virtual KITTI dataset and the Middlebury dataset. It also presents strong generalization capability under different 3D point densities, various lighting and weather conditions.
Stochastic Recursive Momentum for Policy Gradient Methods
Mar 09, 2020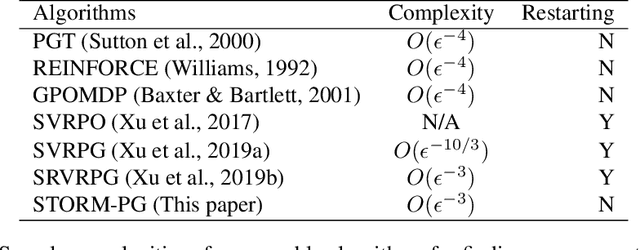
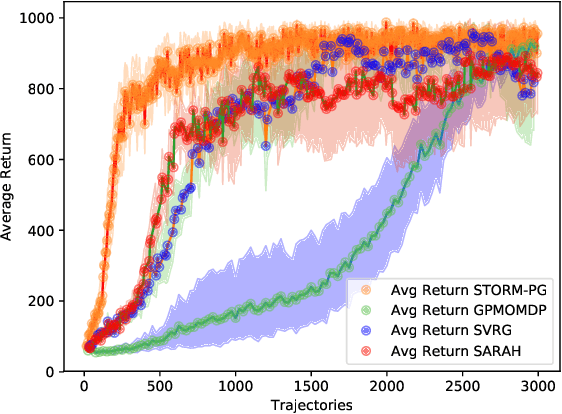
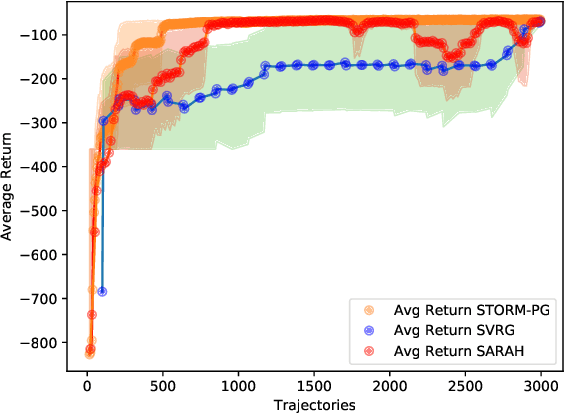
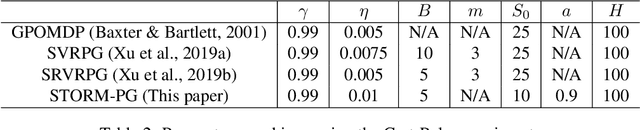
In this paper, we propose a novel algorithm named STOchastic Recursive Momentum for Policy Gradient (STORM-PG), which operates a SARAH-type stochastic recursive variance-reduced policy gradient in an exponential moving average fashion. STORM-PG enjoys a provably sharp $O(1/\epsilon^3)$ sample complexity bound for STORM-PG, matching the best-known convergence rate for policy gradient algorithm. In the mean time, STORM-PG avoids the alternations between large batches and small batches which persists in comparable variance-reduced policy gradient methods, allowing considerably simpler parameter tuning. Numerical experiments depicts the superiority of our algorithm over comparative policy gradient algorithms.
IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
Mar 08, 2020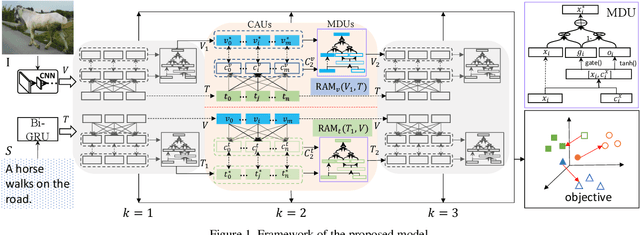
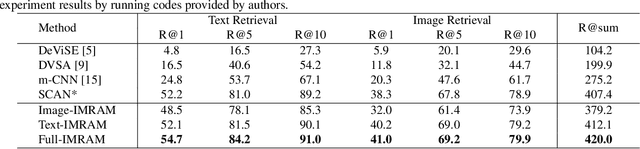
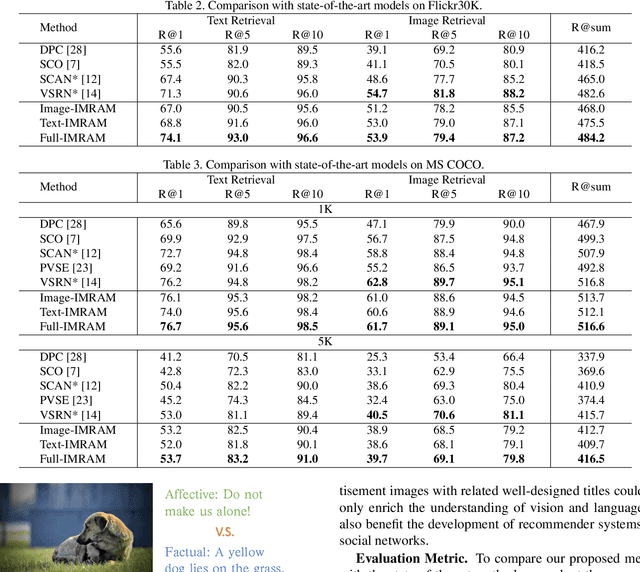

Enabling bi-directional retrieval of images and texts is important for understanding the correspondence between vision and language. Existing methods leverage the attention mechanism to explore such correspondence in a fine-grained manner. However, most of them consider all semantics equally and thus align them uniformly, regardless of their diverse complexities. In fact, semantics are diverse (i.e. involving different kinds of semantic concepts), and humans usually follow a latent structure to combine them into understandable languages. It may be difficult to optimally capture such sophisticated correspondences in existing methods. In this paper, to address such a deficiency, we propose an Iterative Matching with Recurrent Attention Memory (IMRAM) method, in which correspondences between images and texts are captured with multiple steps of alignments. Specifically, we introduce an iterative matching scheme to explore such fine-grained correspondence progressively. A memory distillation unit is used to refine alignment knowledge from early steps to later ones. Experiment results on three benchmark datasets, i.e. Flickr8K, Flickr30K, and MS COCO, show that our IMRAM achieves state-of-the-art performance, well demonstrating its effectiveness. Experiments on a practical business advertisement dataset, named \Ads{}, further validates the applicability of our method in practical scenarios.
End-to-end Robustness for Sensing-Reasoning Machine Learning Pipelines
Mar 06, 2020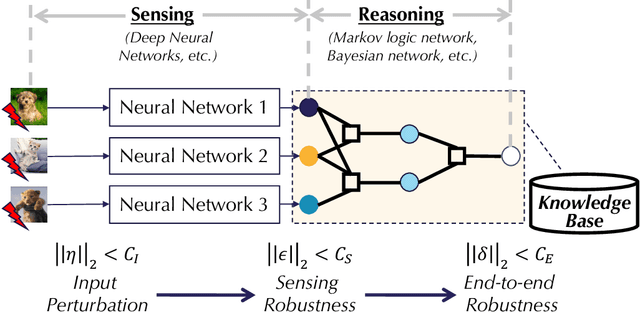
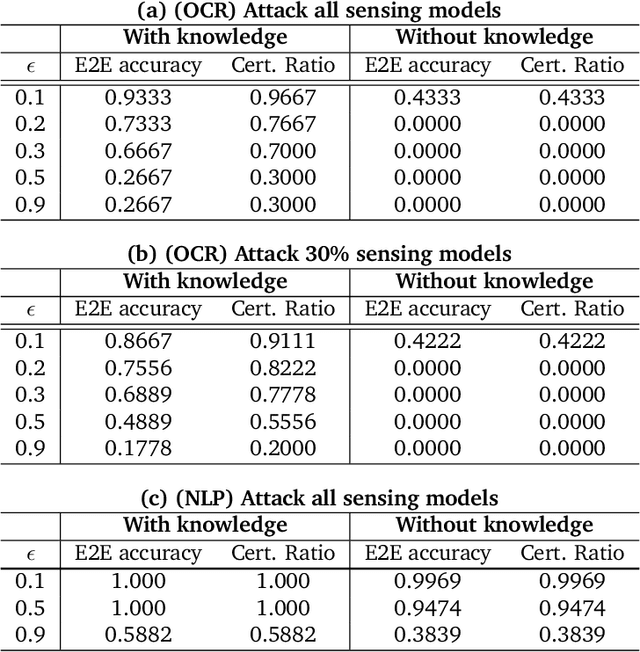
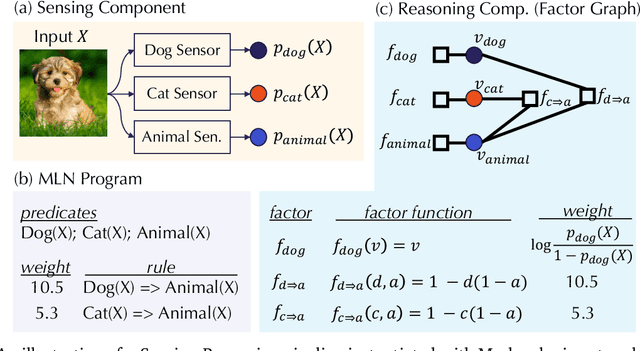
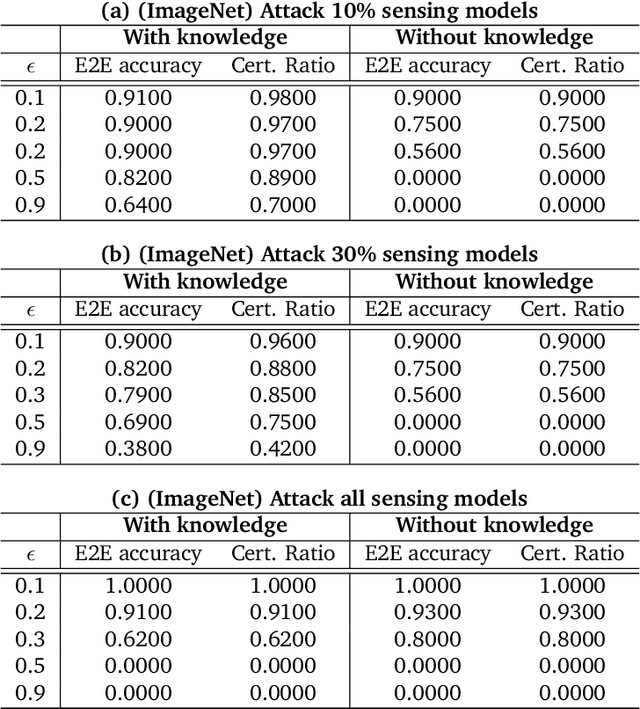
As machine learning (ML) being applied to many mission-critical scenarios, certifying ML model robustness becomes increasingly important. Many previous works focuses on the robustness of independent ML and ensemble models, and can only certify a very small magnitude of the adversarial perturbation. In this paper, we take a different viewpoint and improve learning robustness by going beyond independent ML and ensemble models. We aim at promoting the generic Sensing-Reasoning machine learning pipeline which contains both the sensing (e.g. deep neural networks) and reasoning (e.g. Markov logic networks (MLN)) components enriched with domain knowledge. Can domain knowledge help improve learning robustness? Can we formally certify the end-to-end robustness of such an ML pipeline? We first theoretically analyze the computational complexity of checking the provable robustness in the reasoning component. We then derive the provable robustness bound for several concrete reasoning components. We show that for reasoning components such as MLN and a specific family of Bayesian networks it is possible to certify the robustness of the whole pipeline even with a large magnitude of perturbation which cannot be certified by existing work. Finally, we conduct extensive real-world experiments on large scale datasets to evaluate the certified robustness for Sensing-Reasoning ML pipelines.
Stochastic Recursive Variance Reduction for Efficient Smooth Non-Convex Compositional Optimization
Jan 25, 2020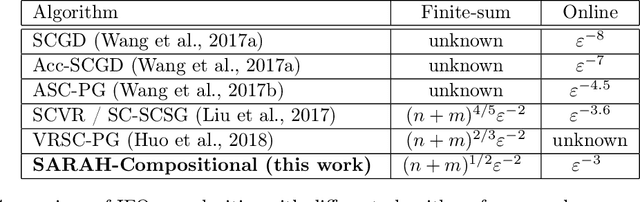
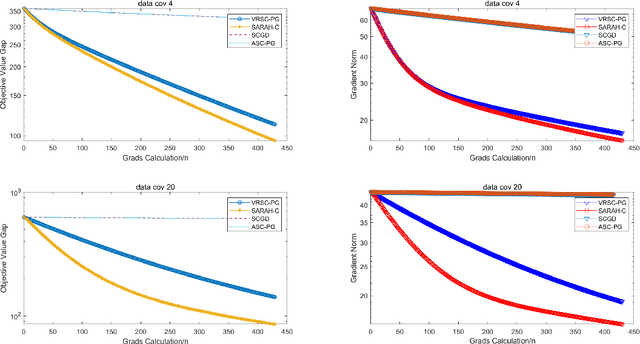
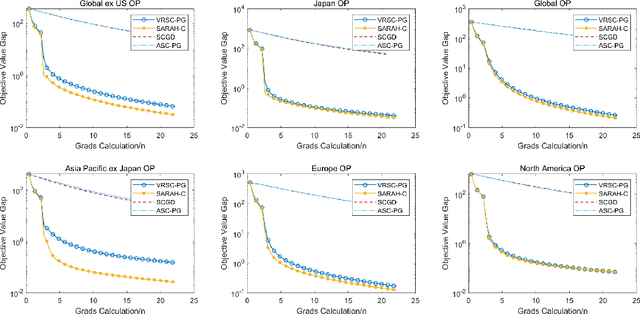
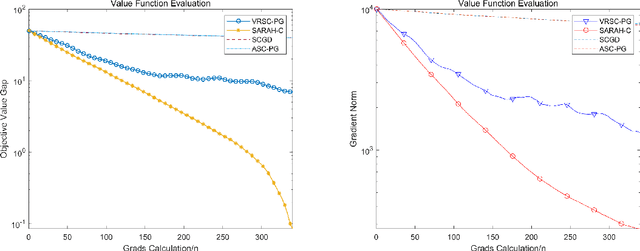
Stochastic compositional optimization arises in many important machine learning tasks such as value function evaluation in reinforcement learning and portfolio management. The objective function is the composition of two expectations of stochastic functions, and is more challenging to optimize than vanilla stochastic optimization problems. In this paper, we investigate the stochastic compositional optimization in the general smooth non-convex setting. We employ a recently developed idea of \textit{Stochastic Recursive Gradient Descent} to design a novel algorithm named SARAH-Compositional, and prove a sharp Incremental First-order Oracle (IFO) complexity upper bound for stochastic compositional optimization: $\mathcal{O}((n+m)^{1/2} \varepsilon^{-2})$ in the finite-sum case and $\mathcal{O}(\varepsilon^{-3})$ in the online case. Such a complexity is known to be the best one among IFO complexity results for non-convex stochastic compositional optimization, and is believed to be optimal. Our experiments validate the theoretical performance of our algorithm.
A novel tree-structured point cloud dataset for skeletonization algorithm evaluation
Jan 09, 2020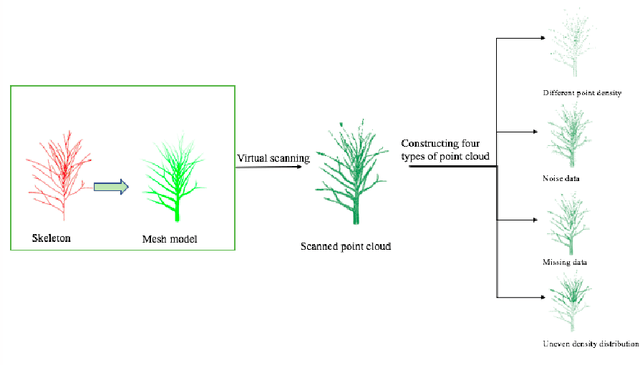


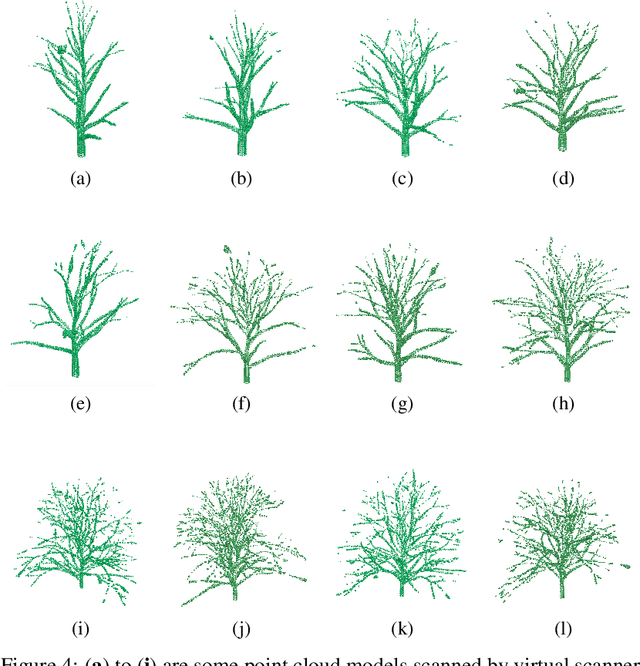
Curve skeleton extraction from unorganized point cloud is a fundamental task of computer vision and three-dimensional data preprocessing and visualization. A great amount of work has been done to extract skeleton from point cloud. but the lack of standard datasets of point cloud with ground truth skeleton makes it difficult to evaluate these algorithms. In this paper, we construct a brand new tree-structured point cloud dataset, including ground truth skeletons, and point cloud models. In addition, four types of point cloud are built on clean point cloud: point clouds with noise, point clouds with missing data, point clouds with different density, and point clouds with uneven density distribution. We first use tree editor to build the tree skeleton and corresponding mesh model. Since the implicit surface is sufficiently expressive to retain the edges and details of the complex branches model, we use the implicit surface to model the triangular mesh. With the implicit surface, virtual scanner is applied to the sampling of point cloud. Finally, considering the challenges in skeleton extraction, we introduce different methods to build four different types of point cloud models. This dataset can be used as standard dataset for skeleton extraction algorithms. And the evaluation between skeleton extraction algorithms can be performed by comparing the ground truth skeleton with the extracted skeleton.
Global Sparse Momentum SGD for Pruning Very Deep Neural Networks
Oct 25, 2019
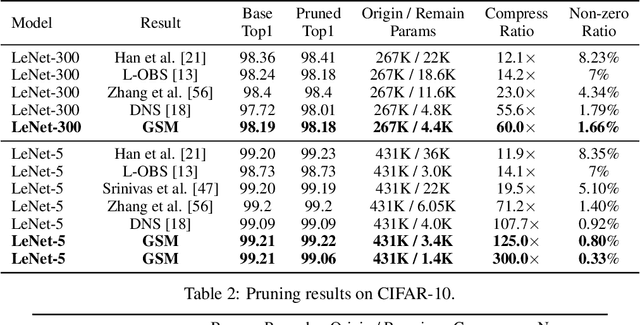
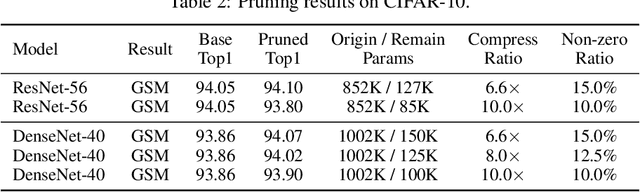
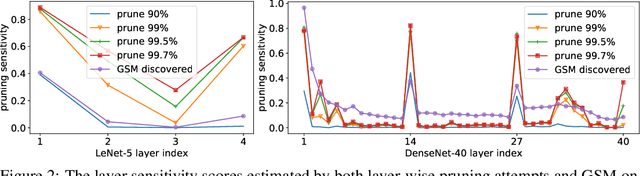
Deep Neural Network (DNN) is powerful but computationally expensive and memory intensive, thus impeding its practical usage on resource-constrained front-end devices. DNN pruning is an approach for deep model compression, which aims at eliminating some parameters with tolerable performance degradation. In this paper, we propose a novel momentum-SGD-based optimization method to reduce the network complexity by on-the-fly pruning. Concretely, given a global compression ratio, we categorize all the parameters into two parts at each training iteration which are updated using different rules. In this way, we gradually zero out the redundant parameters, as we update them using only the ordinary weight decay but no gradients derived from the objective function. As a departure from prior methods that require heavy human works to tune the layer-wise sparsity ratios, prune by solving complicated non-differentiable problems or finetune the model after pruning, our method is characterized by 1) global compression that automatically finds the appropriate per-layer sparsity ratios; 2) end-to-end training; 3) no need for a time-consuming re-training process after pruning; and 4) superior capability to find better winning tickets which have won the initialization lottery.
ATZSL: Defensive Zero-Shot Recognition in the Presence of Adversaries
Oct 24, 2019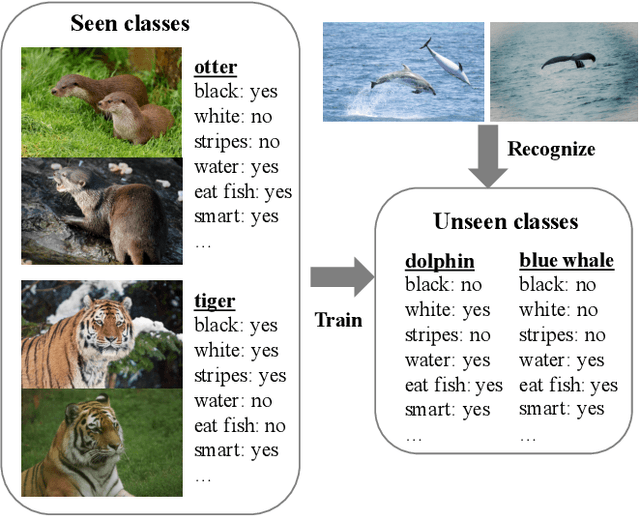
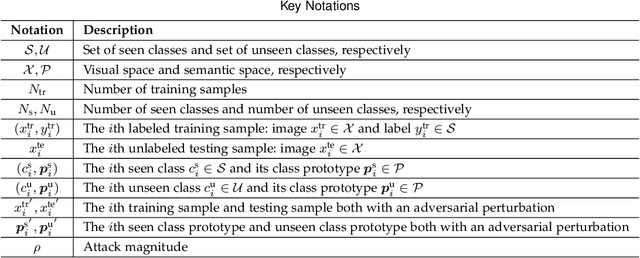

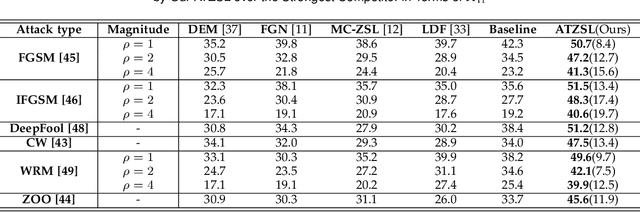
Zero-shot learning (ZSL) has received extensive attention recently especially in areas of fine-grained object recognition, retrieval, and image captioning. Due to the complete lack of training samples and high requirement of defense transferability, the ZSL model learned is particularly vulnerable against adversarial attacks. Recent work also showed adversarially robust generalization requires more data. This may significantly affect the robustness of ZSL. However, very few efforts have been devoted towards this direction. In this paper, we take an initial attempt, and propose a generic formulation to provide a systematical solution (named ATZSL) for learning a robust ZSL model. It is capable of achieving better generalization on various adversarial objects recognition while only losing a negligible performance on clean images for unseen classes, by casting ZSL into a min-max optimization problem. To address it, we design a defensive relation prediction network, which can bridge the seen and unseen class domains via attributes to generalize prediction and defense strategy. Additionally, our framework can be extended to deal with the poisoned scenario of unseen class attributes. An extensive group of experiments are then presented, demonstrating that ATZSL obtains remarkably more favorable trade-off between model transferability and robustness, over currently available alternatives under various settings.
Hierarchical Prototype Learning for Zero-Shot Recognition
Oct 24, 2019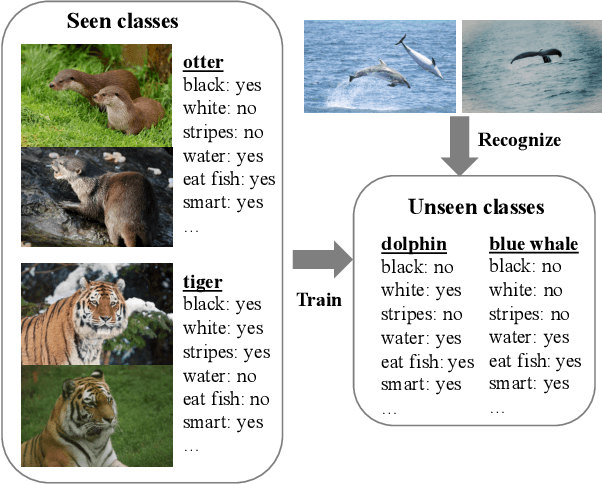

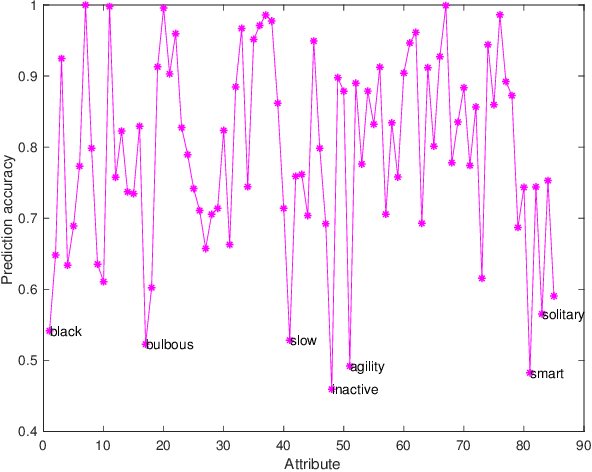
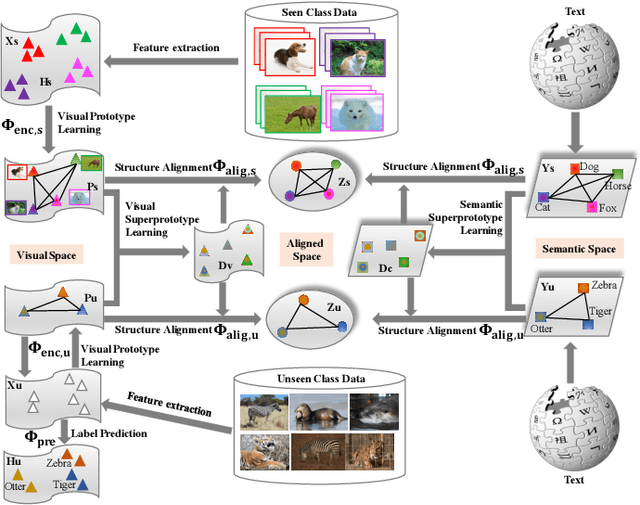
Zero-Shot Learning (ZSL) has received extensive attention and successes in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. Key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary semantic prototypes (e.g., word or attribute vectors). However, the popularly learned projection functions in previous works cannot generalize well due to non-visual components included in semantic prototypes. Besides, the incompleteness of provided prototypes and captured images has less been considered by the state-of-the-art approaches in ZSL. In this paper, we propose a hierarchical prototype learning formulation to provide a systematical solution (named HPL) for zero-shot recognition. Specifically, HPL is able to obtain discriminability on both seen and unseen class domains by learning visual prototypes respectively under the transductive setting. To narrow the gap of two domains, we further learn the interpretable super-prototypes in both visual and semantic spaces. Meanwhile, the two spaces are further bridged by maximizing their structural consistency. This not only facilitates the representativeness of visual prototypes, but also alleviates the loss of information of semantic prototypes. An extensive group of experiments are then carefully designed and presented, demonstrating that HPL obtains remarkably more favorable efficiency and effectiveness, over currently available alternatives under various settings.