 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021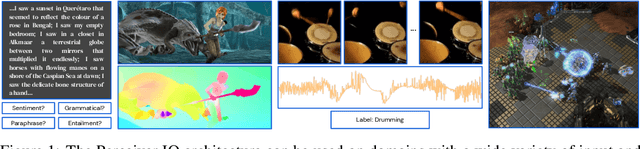
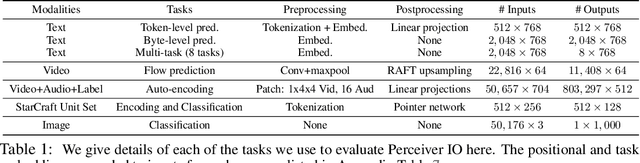
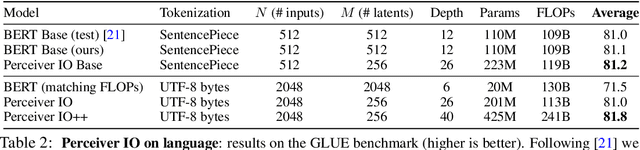
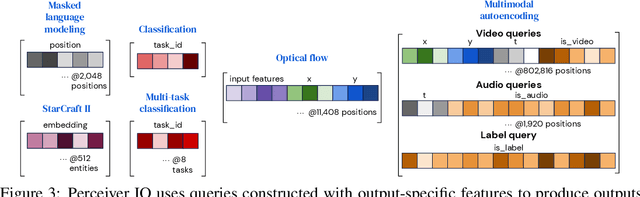
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


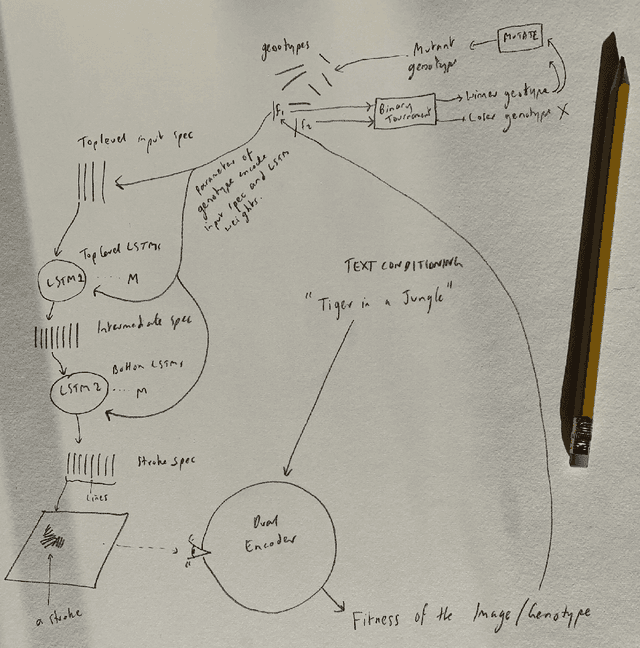
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
Multimodal Self-Supervised Learning of General Audio Representations
Apr 28, 2021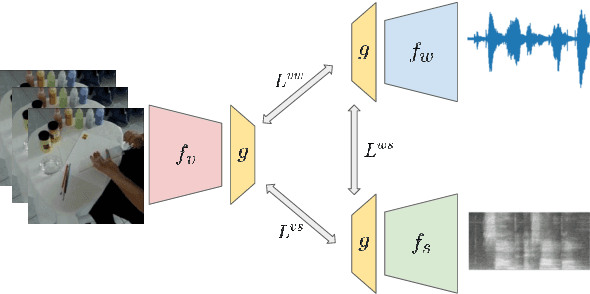

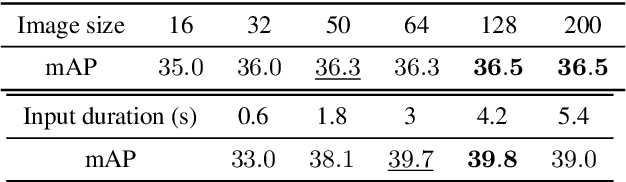

We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.
Machine Translation Decoding beyond Beam Search
Apr 12, 2021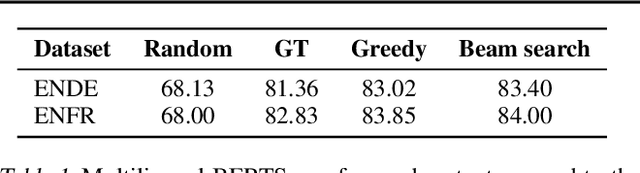
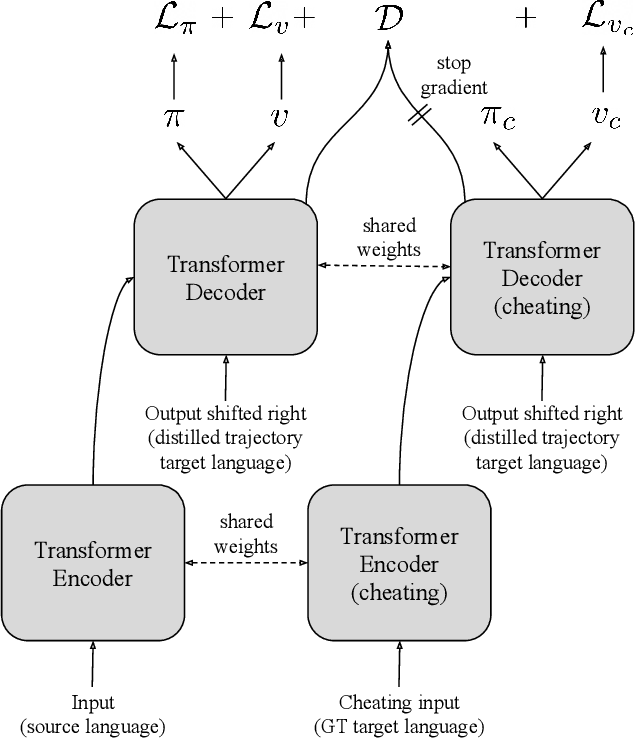
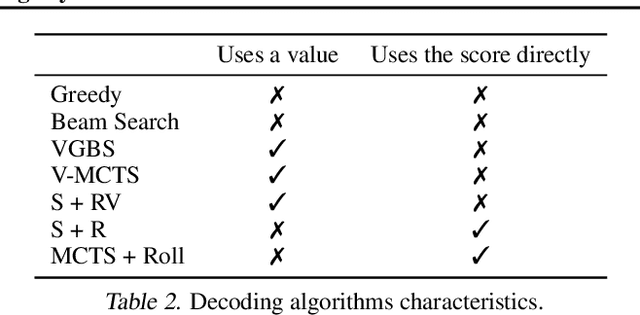
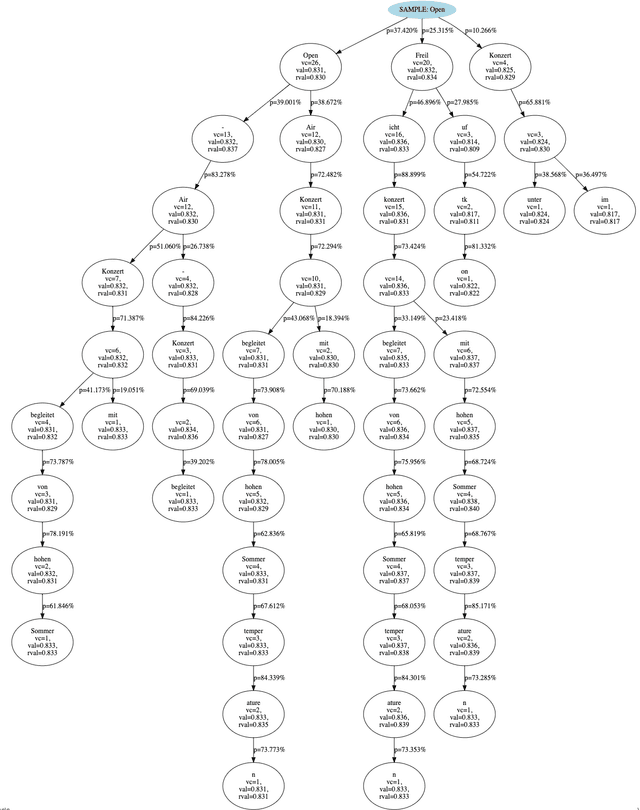
Beam search is the go-to method for decoding auto-regressive machine translation models. While it yields consistent improvements in terms of BLEU, it is only concerned with finding outputs with high model likelihood, and is thus agnostic to whatever end metric or score practitioners care about. Our aim is to establish whether beam search can be replaced by a more powerful metric-driven search technique. To this end, we explore numerous decoding algorithms, including some which rely on a value function parameterised by a neural network, and report results on a variety of metrics. Notably, we introduce a Monte-Carlo Tree Search (MCTS) based method and showcase its competitiveness. We provide a blueprint for how to use MCTS fruitfully in language applications, which opens promising future directions. We find that which algorithm is best heavily depends on the characteristics of the goal metric; we believe that our extensive experiments and analysis will inform further research in this area.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021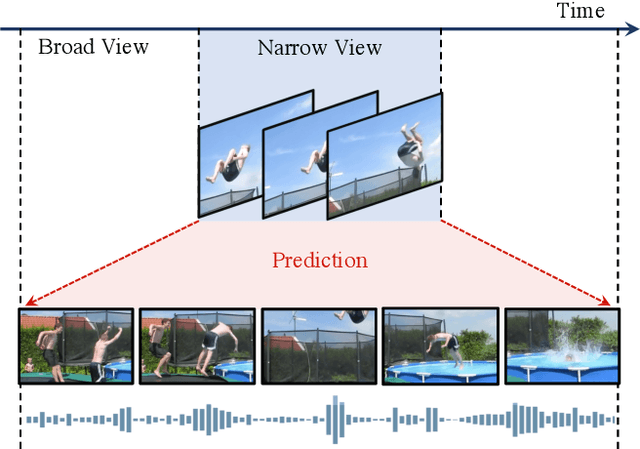
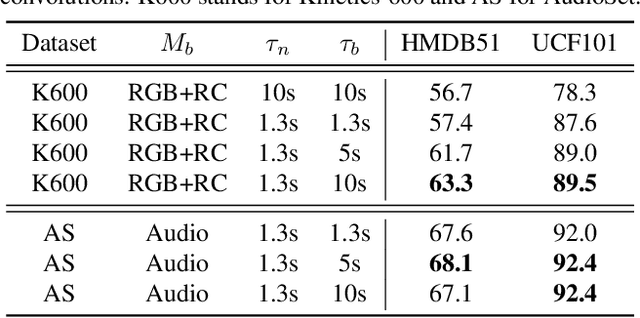
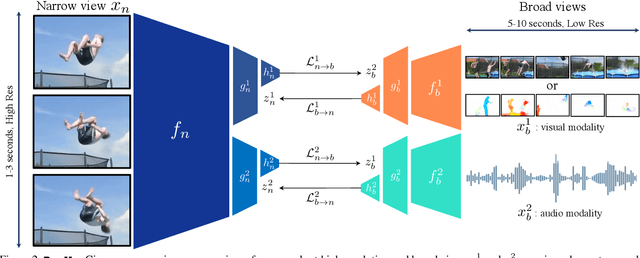
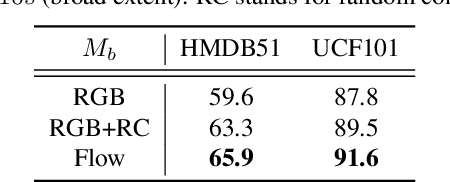
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
Mar 30, 2021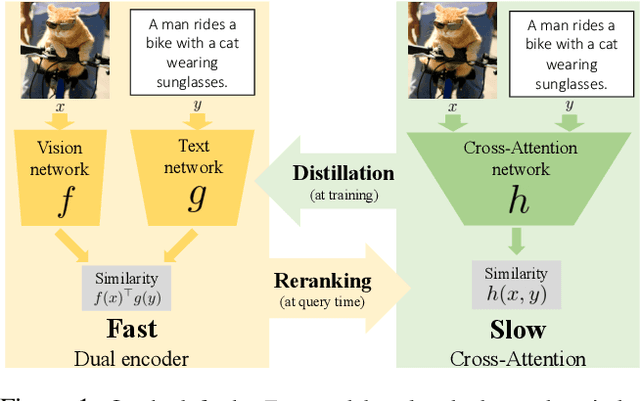
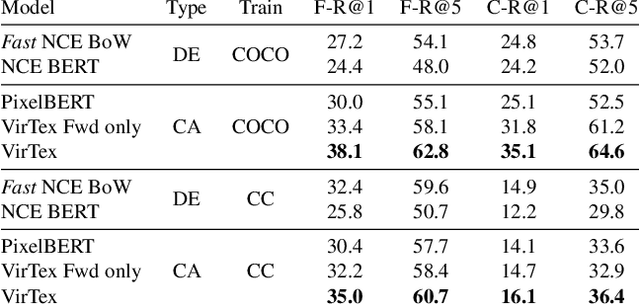
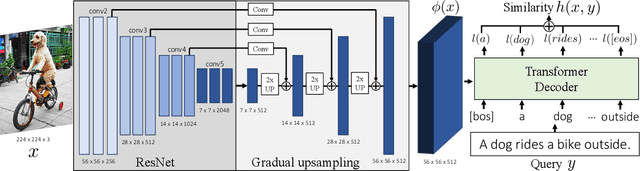
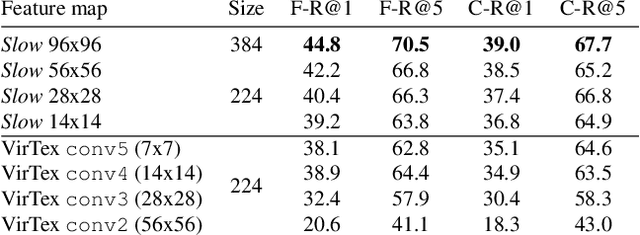
Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking. Finally, we validate our approach on the Flickr30K image dataset where we show an increase in inference speed by several orders of magnitude while having results competitive to the state of the art. We also extend our method to the video domain, improving the state of the art on the VATEX dataset.
Efficient Visual Pretraining with Contrastive Detection
Mar 19, 2021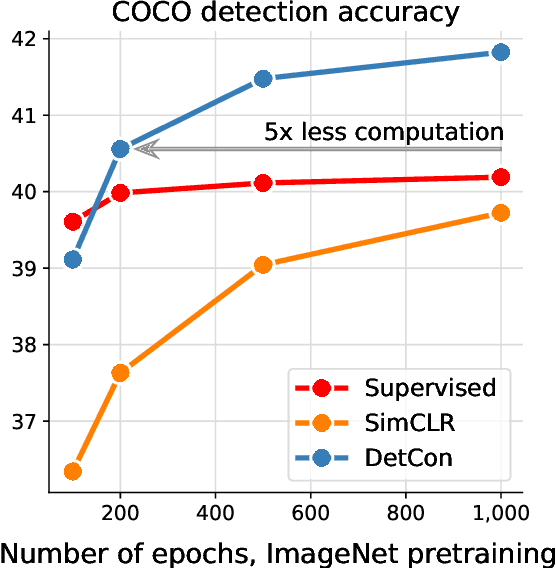
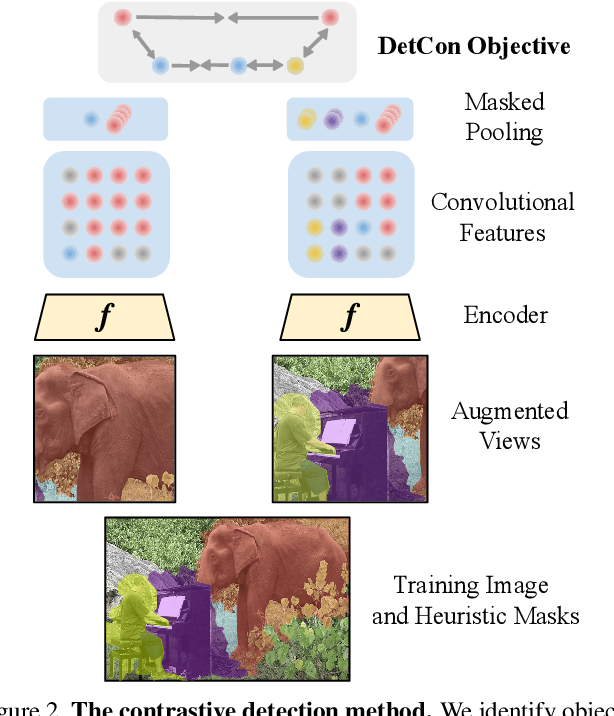
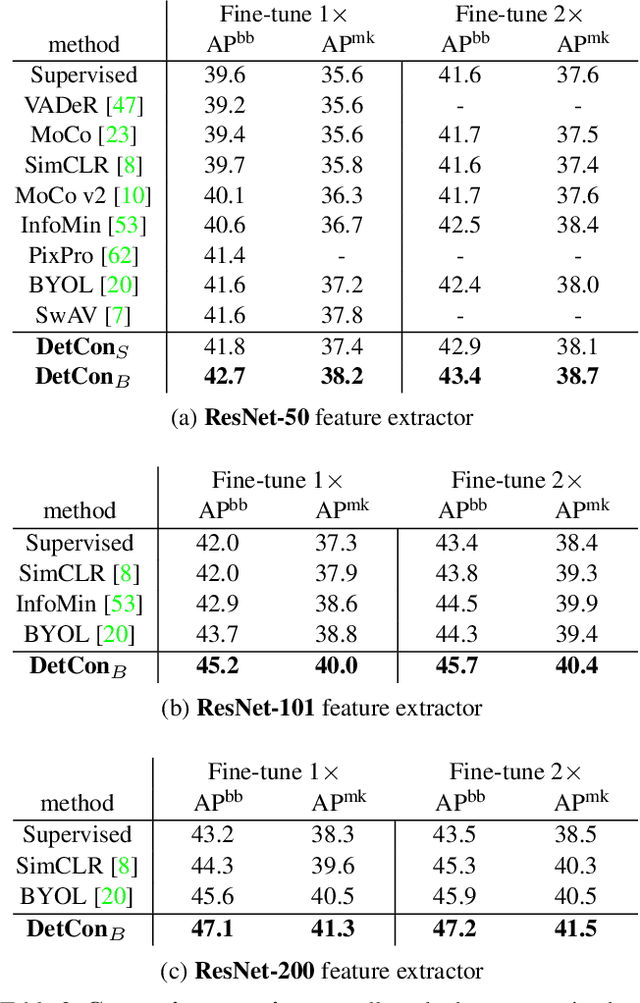

Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer performance from ImageNet to COCO, while requiring up to 5x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.
Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
Jan 31, 2021
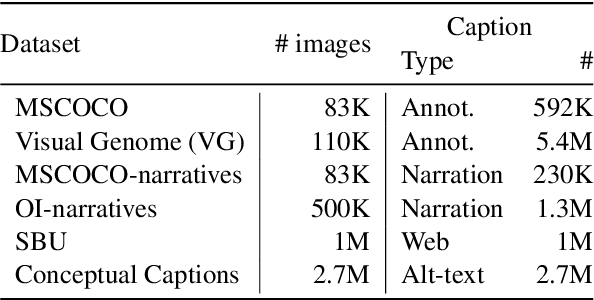
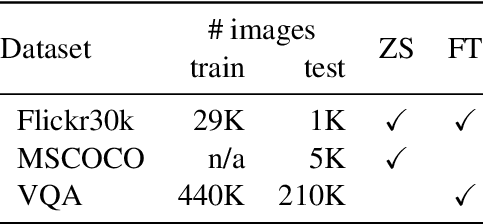
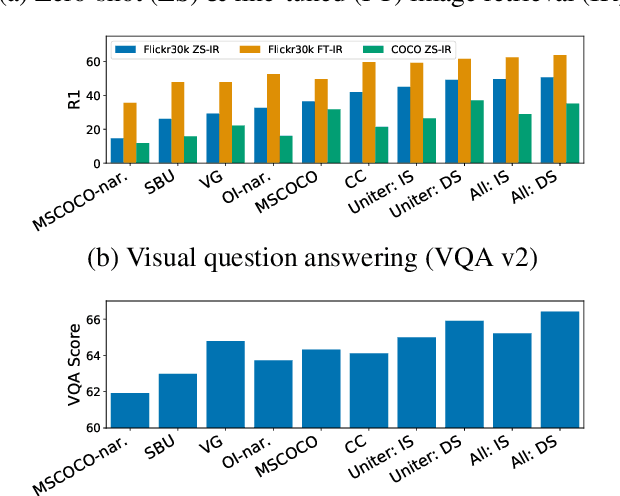
Recently multimodal transformer models have gained popularity because their performance on language and vision tasks suggest they learn rich visual-linguistic representations. Focusing on zero-shot image retrieval tasks, we study three important factors which can impact the quality of learned representations: pretraining data, the attention mechanism, and loss functions. By pretraining models on six datasets, we observe that dataset noise and language similarity to our downstream task are important indicators of model performance. Through architectural analysis, we learn that models with a multimodal attention mechanism can outperform deeper models with modality specific attention mechanisms. Finally, we show that successful contrastive losses used in the self-supervised learning literature do not yield similar performance gains when used in multimodal transformers
RareAct: A video dataset of unusual interactions
Aug 03, 2020


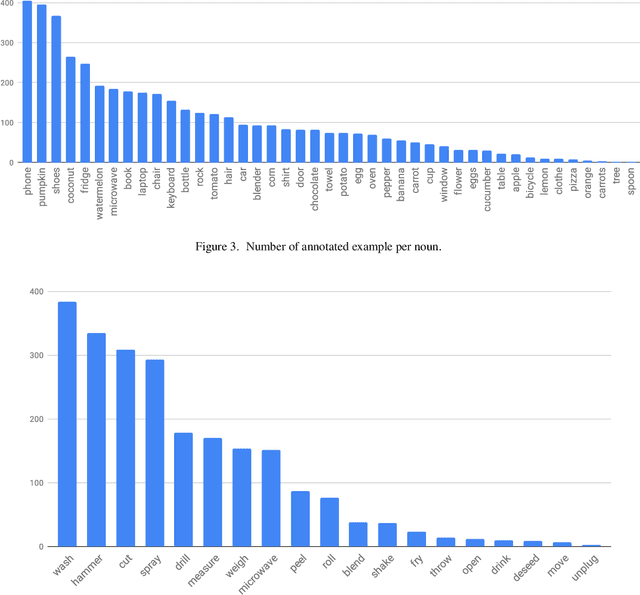
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020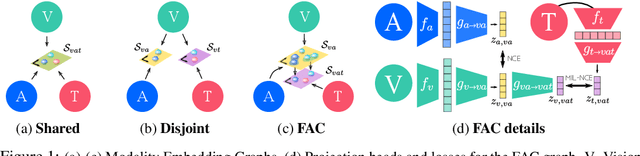
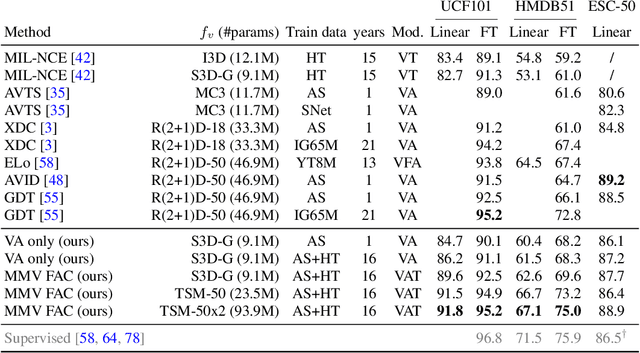
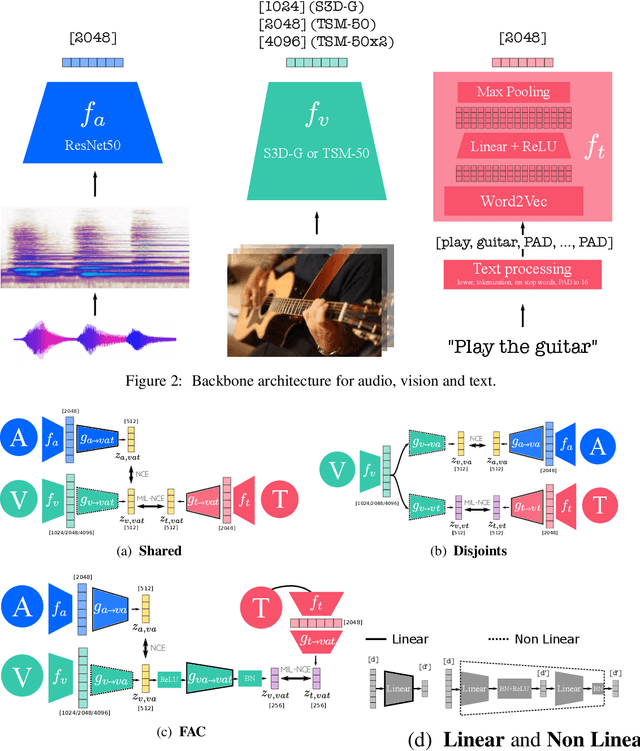
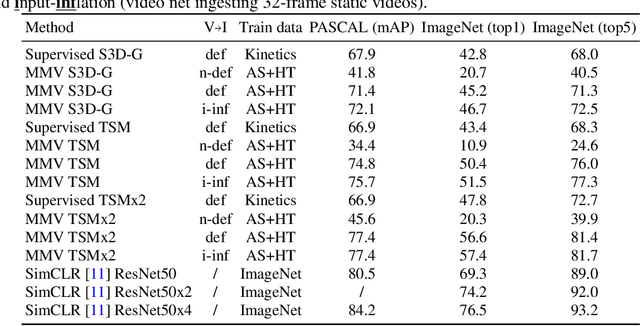
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.