 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling the Role of Data, Attention, and Losses in Multimodal Transformers
Paper and Code
Jan 31, 2021
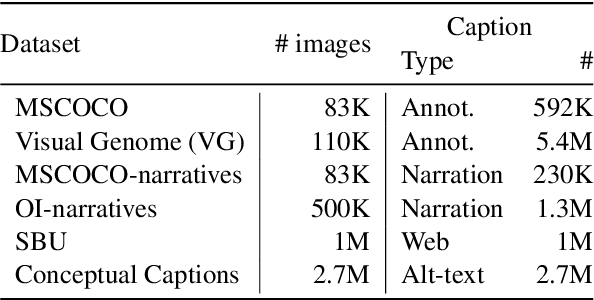
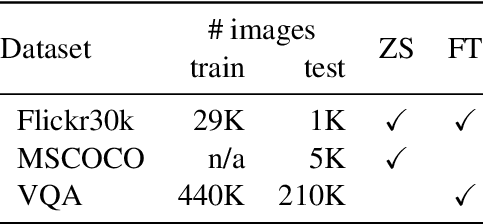
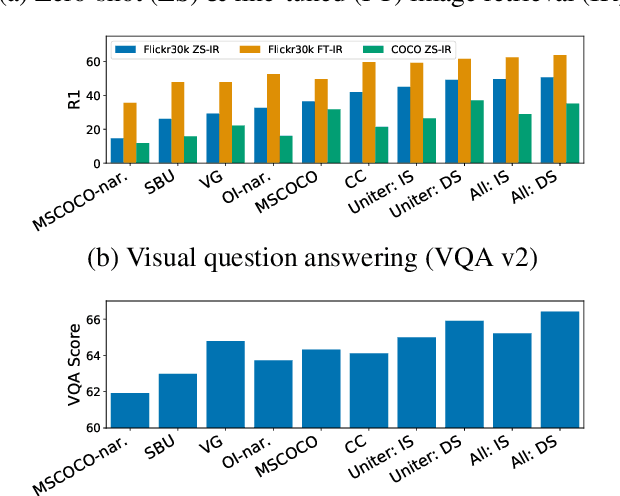
Recently multimodal transformer models have gained popularity because their performance on language and vision tasks suggest they learn rich visual-linguistic representations. Focusing on zero-shot image retrieval tasks, we study three important factors which can impact the quality of learned representations: pretraining data, the attention mechanism, and loss functions. By pretraining models on six datasets, we observe that dataset noise and language similarity to our downstream task are important indicators of model performance. Through architectural analysis, we learn that models with a multimodal attention mechanism can outperform deeper models with modality specific attention mechanisms. Finally, we show that successful contrastive losses used in the self-supervised learning literature do not yield similar performance gains when used in multimodal transformers